Vibe Coding 在代码生成与协作中的实践与思考 - 向邦宇
自我介绍:
- 多年从事研发者工具开发,包括内部 AI Coding 工具和 Web IDE 工具
- 从 2023 年开始,从内部 Copilot 转型到 AI Agent 方向
- 作为产品提供方,接触了大量内部用户,观察他们如何使用工具以及遇到的问题
演讲选题思考:
- Vibe Coding 概念出现几个月,但并非确定性的东西
- 不同人对 Vibe Coding 理解不同,使用的工具也不同
- 从两个视角分享:用户使用场景和问题、产品提供方的思考和解决方案
演讲结构:
- 简单介绍业界和内部有哪些 Vibe Coding 工具在使用
- 用户在使用 Vibe Coding 工具过程中遇到的问题
- 作为 Vibe Coding 工具核心主导者的思考
- 国产模型适配过程中遇到的问题和解决方案
Vibe Coding 产品形态
当前工具分类的模糊性:
- 大家对 Vibe Coding 工具的理解和分类不够清晰
- 每个工具都有人在用,但缺乏明确的定位

不同 Vibe Coding 工具的主要区别
1. Native IDE(原生集成开发环境)
- 代表产品:Cursor、Cline、阿里 Qoder 等
- 特点:以独立 IDE 形式存在
- 优势:灵活性高,功能完整
2. IDE Plugin(IDE 插件)
- 代表产品:内部 Aone Copilot 等
- 基于现有 IDE(主要是 VS Code 或 JetBrains)的插件形式
- 内部用户使用插件是比较主流的习惯
- 灵活性可能没有 Native IDE 那么高
3. Web IDE
- 入口在浏览器上
- 整个执行在远端容器里,可能是沙箱环境
- 优势:
- 解决信任问题和云端执行的安全问题
- 更适合协作:多个同学可以在同一个 Web IDE 里进行同步协作和分享
- 跨平台支持
4. CLI 命令行工具
- 代表产品:Copilot CLI
- 最初没想到会受欢迎,但实际上非常受主流研发欢迎
- 未来可能在被集成的方式(如 CI/CD)中执行一些自动化任务
- 在这种场景下会有更高的可能性
内部 Vibe Coding 工具的使用实践
Aone Copilot(依托于 IDE 的Wibe Agent工具):
- 内部协作多年的产品
- 用户规模:数万用户,每周几千周活
- 主要使用场景:
- 代码生成
- Bug 修复
- 代码分析
- 用户分布:后端场景渗透率较高,前端用户更倾向使用 Native IDE(如 Cursor 或 Qoder)
AI Agent(异步容器执行的 Agent 工具):
- 以 Web 端发起的容器内运行的异步任务工具
- 核心特点:用户通过自然语言发起任务
- 在异步容器里拉起 Agent,Agent 自己调用工具(搜索工具、文件读写工具、Shell 工具等)
- 用户角色更加多元:
- 主要用户:后端开发
- 其他用户:测试、前端、算法、产品、运营、设计、运维等
- 任务类型丰富多元:
- 代码分析
- 代码改动
- 单元测试
- 代码生成
- 文案方案调研等
工具尤其是 Agent 带来的效率提升
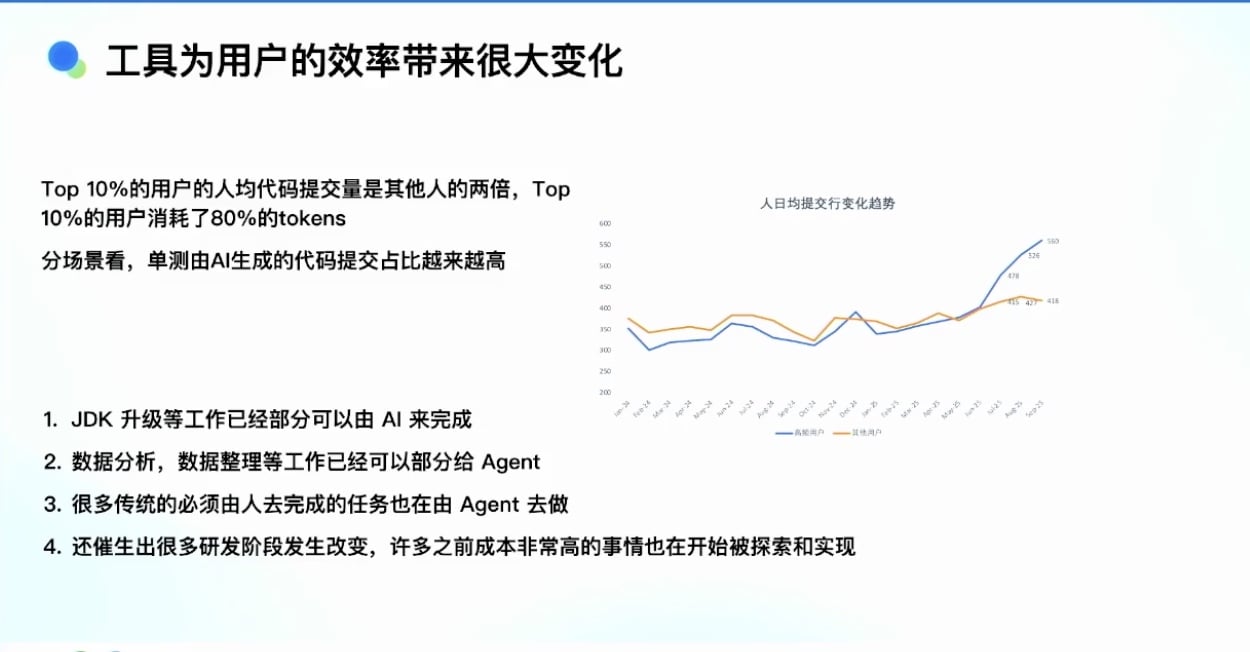
数据观察(从 4 月份开始的 Agent 模式):
代码提交量的显著提升:
- 蓝色线:高频用户(使用 Agent 模式)
- 橙色线:其他用户
- Agent 模式下,高频用户的每日代码提交行数有非常大的提升
- 到 9 月份,高频用户每天提交 540-560 行代码,其他用户只有 400 多行
- 至少从定量指标看,Agent 模式对提效肯定有帮助
用户分层现象:
- Top 10% 用户的代码提交量是其他人的两倍
- 认为 Agent 对人的提效可能大于两倍,因为大量工作在协同、开会等非编码环节
- Top 10% 用户的 Copilot 消耗占整体消耗的 80%
AI 新的应用场景:
- 单元测试由 AI 生成的提交代码占比越来越高
- JDK 升级、NPM 包升级、SDK 升级等工作已经可以由 AI 完成
- JDK 11 及以上版本升级场景,内部基本全部交给工具处理
- 数据分析、数据整理工作部分交给 AI
- 传统必须由人完成的任务现在由 Agent 完成:
- 测试过程中的截图
- 压测过程中的重复任务
- 过去成本过高无法做的事情现在可以做:
- 一次发布是否会引起其他相关系统故障
- 每一行代码对其他系统的影响分析
用户使用 Vibe Coding 工具遇到的问题
用户情绪问题

AI 表现不足导致的崩溃:
- 后台日志中大量用户抱怨”AI 太笨了”等激动的话
- 用户反复删除代码、修改代码的行为
- 无论公司内部还是社区,都能看到用户因 Agent 能力不足而崩溃
GitHub 上的”八荣八耻”提示词:
- 用户分享给 Agent 的提示词规范
- 例如:”以不能修改原始代码为荣”等
5.2 代码质量问题
我们看到的 Vibe Coding 的问题是多方面的
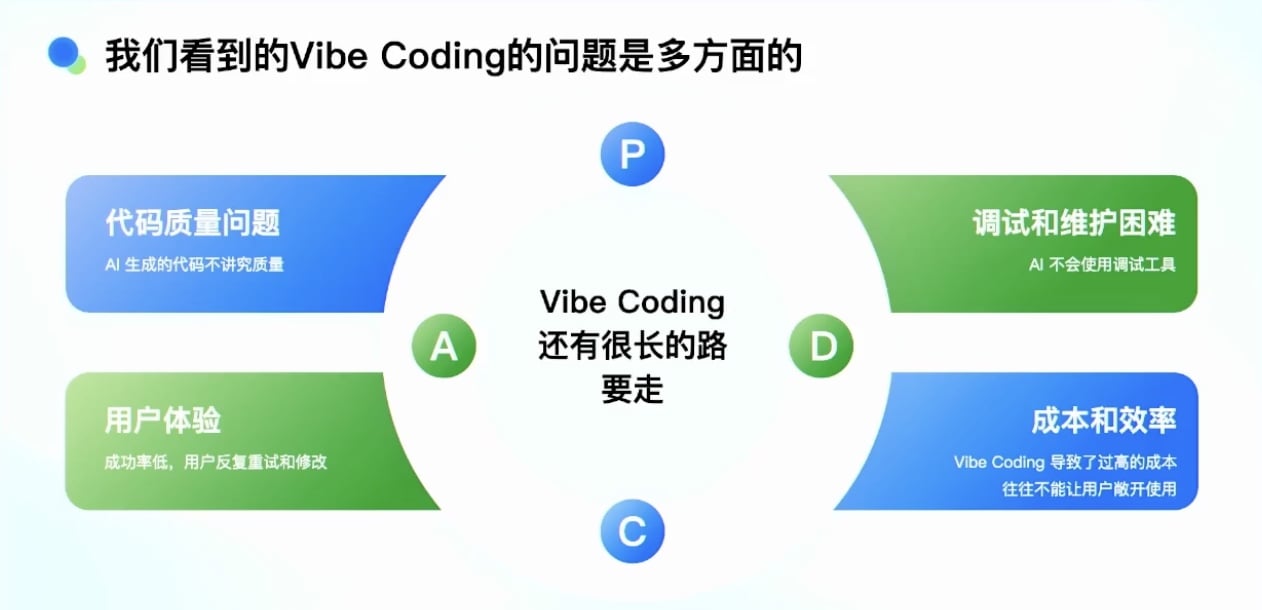
- 代码风格不一致
- 生成的代码质量和风格差异较大
- 在存量仓库里写代码时,可能以自己的风格编写,而非遵循项目规范
- 边界条件处理不完善
- 对复杂业务逻辑的边界情况处理不够充分
- 性能缺陷
- 生成的代码存在性能问题
- 安全漏洞
- SQL 注入类漏洞严重
- 斯坦福研究表明:AI 生成代码中注入类漏洞比例约 45%
- 其他安全问题:
- 接口注入
- XSS 攻击
- 逻辑错误
- 边界条件处理错误
- 异常控制
- 数字越界
代码逻辑自洽问题

- AI 在代码生成过程中会有非常多的”自洽”
- 案例:数据去重函数及其对应的单元测试
- 测试通过率 100%
- 针对代码做了单测
- 但如果让 AI 同时写单测和业务逻辑,无法保证质量
- 会出现”自己和自己对话”的情况
- 建议:至少有一项(单测或业务逻辑)是人去 review 的
调试和维护困难

调试时间增加:
- 使用工具后,调试时间增加 30%-50%
- 黑盒问题
- Vibe Coding 更倾向于黑盒代码逻辑生成
- 虽然最后会让人确认代码 diff 才能提交
- 但生成过程是黑盒,不会有人认真看每一条
- AI 生成代码像”黑魔法”,出问题时完全不知道如何下手
- 技术债务越来越深
- 上下文理解局限
- 存量任务的业务逻辑可能积累十几年
- 有些代码为什么要这么写?有些代码是否能去掉?对 AI 来说都很困难
- Vibe Coding 工具缺乏全局思维
- 生成的代码模块化程度不够,代码耦合度很高
- 解决方案:RepoWiki, DeepWiki 等方案
- 缺乏可追溯性
- Vibe Coding 一次性生成大量代码
- AI 无法知道:是新需求导致代码写错,还是一开始就写错了
- 缺乏版本管理和版本概念
- 一次生成代码出错后,不知道从哪个地方回滚
- 现有方法:
- 每次改完测试通过后提交一个 commit, 下次可以从这个 commit 回滚
- 使用 Cursor 等回滚工具
- 但仍然缺乏可追溯性,用户无法做版本管理,无法回到正确状态,只能重来
Vibe Coding 工具普遍不会使用常用的调试工具
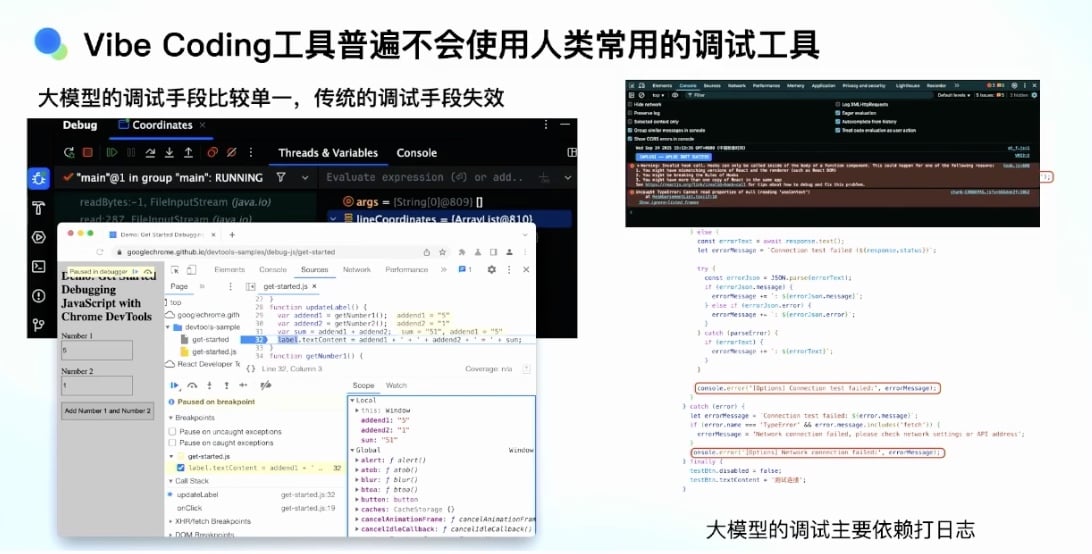
- AI 普遍不会使用人类常用的调试工具
- 传统”古法编程”中,开发者大量使用 Debug、断点等工具
- 浏览器上也可以做调试
- 但让 Vibe Coding 工具使用这些调试工具去找堆栈、找问题非常困难
- 工具能力缺失导致的问题:
- AI 只能打大量的 console.log, 让用户执行完后,把 log 或控制台的报错、打印信息再粘贴给工具
- 需要人介入
- 不是高效的模式
- 大模型的调试手段比较单一,传统调试方法无法被大模型用起来
Vibe Coding 工具本身存在的问题

1. 稳定性和成功率:
- 最大的问题
- Vibe Coding 工具执行时间很长(30 秒到 5 分钟)
- 不是每次都能成功
- 失败原因:
- 模型问题
- 工具反馈不对
- 某些工具出错
- IDE 本身不稳定
- 用户体验:用过一次发现不稳定,在时间紧、任务重时就不会再使用
2. 交互界面设计问题:
- 大量 Vibe Coding 工具产品频繁改版,功能丢失
- 案例:Devin
- 改版后用户找不到原来的功能
- 工具里增加越来越多功能(剧本、MCP 市场、知识引入等)
- 现在再看又没有了
- 交互界面频繁改版
3. 沟通和交互障碍:
- 理解能力不足:AI 无法完全理解用户意图,需要反复确认
- 不同场景下确认的必要性不同:
- 复杂任务:需要确认(如 SpecCoding - 先建需求、生成设计稿、再让 AI 做)
- 简单任务:不需要确认,需要 Agent 自由探索
4. 长链路任务执行能力不足:
- 无法维持长期上下文
- Agent 大模型的 token 有上限
- 上下文过长时,记忆和召回能力不足
5. 工程工作流程中断:
- 大量工具(IDE, CLI, Web Agent 等)各有擅长领域
- 无法让用户在相同流程或上下文窗口里解决问题
- 案例:在 IDE 里做一件事,需要切换CLI, 重新给 Agent介绍诉求和需求
- 导致用户在不同工具间频繁切换
成本问题
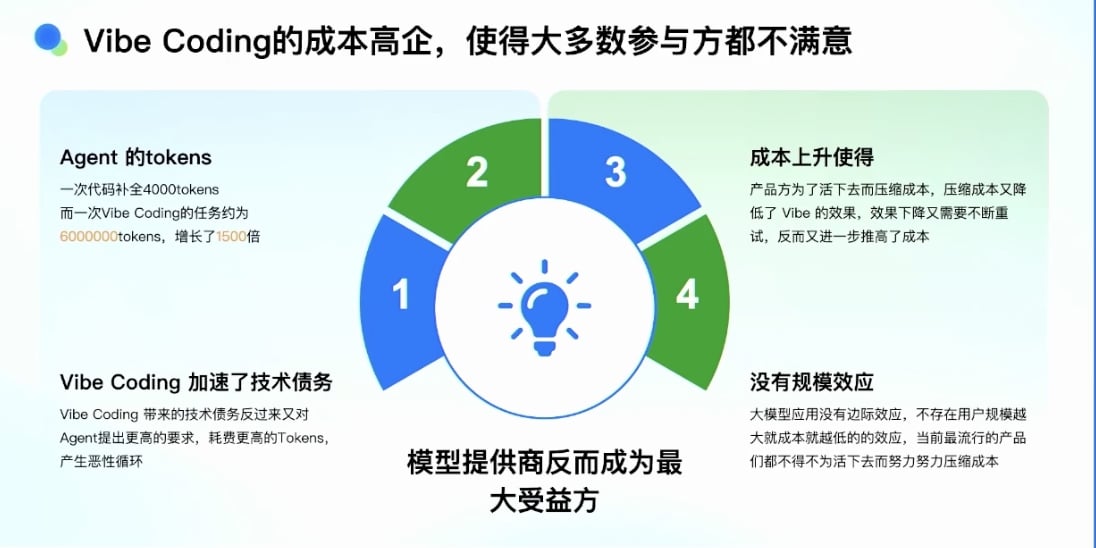
成本问题导致各方不满意:
1. Agent 的 Token 消耗巨大:
- 代码补全场景:
- 调用频次高
- 单次消耗约 4000 Tokens
- Vibe Coding 任务:
- 单次消耗百万级甚至千万级 Tokens
- 原因:
- 上下文更长
- 交互轮次多(几十上百次)
2. Vibe Coding 加速带来的技术债务:
- 技术债务反而对 Agent 提出更高要求
3. 成本上升导致产品方频繁调整计费逻辑:
- 产品方(Cursor、Qoder 等)频繁切换计费逻辑
- 没有任何一款产品敢保证包月或无限次使用
- 成本压力导致产品设计不断调整:
- 压缩上下文
- 削减能力
- 恶性循环:
- 成本降低 → 成功率下降 → 用户多试几次 → 成本又上升
- 产品方为了活下去压缩成本,但效果变差,用户要多试几次,成本又上去
- 使用闭源模型(Claude、GPT-4、GPT-5)后成本难以下降
5. 缺乏规模效应:
- 大模型应用有规模效应,但不明显
- 不存在”用户规模越大,成本就越低”的效应
- Token 成本是固定的
产品自身也遇到的挑战
产品的演进导致模型成本越来越高
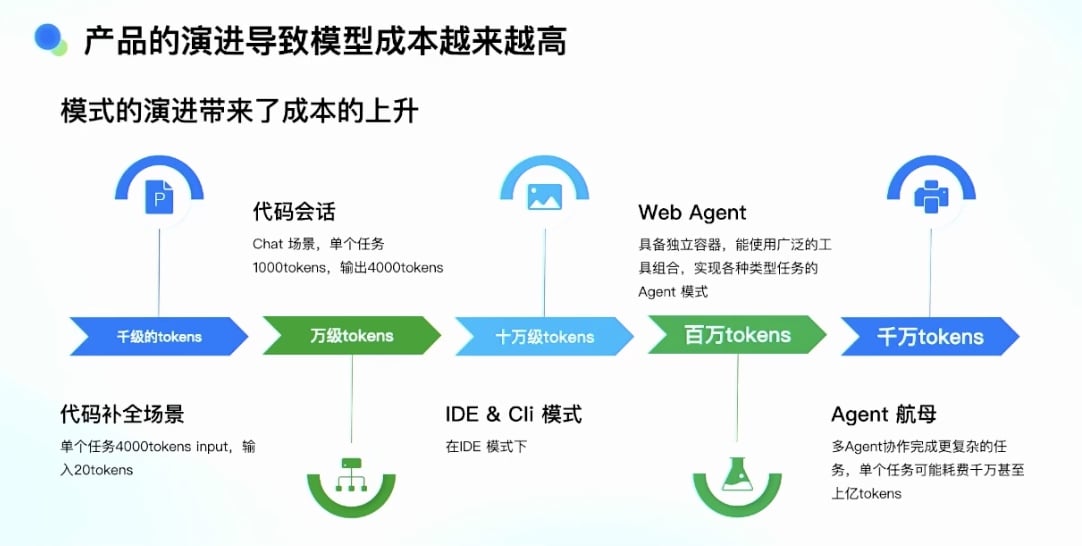
Token 消耗的演进:
代码补全场景:
- 单个任务:约 4000 Tokens 输入
- 输出:20-30 Tokens
Chat 模式:
- 单个任务:约 1000+ Tokens 输入
- 输出:约 4000+ Tokens
单个 Agent 模式(IDE/CLI):
- 单个任务:约 10 万级 Tokens
具备独立容器的 Vibe Coding Agent:
- 能广泛使用各种工具
- 实现各种内容、各种任务类型
- 单个任务:百万级 Tokens
未来的架构(Cursor, TRAE 等):
- 单个任务:可能上亿 Tokens
产品设计的两个同等重要目标:
- 用户满意度
- 成本控制能够匹配用户规模
产品形态的问题

1. 产品界面区分度不够:
- 无论 Chat 产品还是 Vibe Coding 产品,都处于摸索阶段
- 模型能力变化使产品不断变化
- 所有产品都是一个对话框(ChatGPT、DeepSeek、AI 产品)
- 用户难以区分不同产品的区别
2. 用户缺乏引导:
- 给用户一个对话框,但用户不知道应该输入什么
- “Prompt Free”现象
- 不同工具有不同使用场景,但用户往往一刀切
- 用户印象中产品应该能做什么,但试用后发现达不到目标
- 功能学习成本高,使用频次低
- 留存率非常低(Devin 等 Vibe Coding 工具都存在这个问题)
3. 缺乏一站式功能闭环:
- 无法在一个产品里解决所有问题
- 案例:
- 一个 Vibe Coding Agent 能解决复杂产品问题
- 但又能解决小白/初学者问题
- 小白面临的问题不仅是代码能否写完,还有发布、部署、调试等
- 发展过程中存在各种调整
安全风险问题
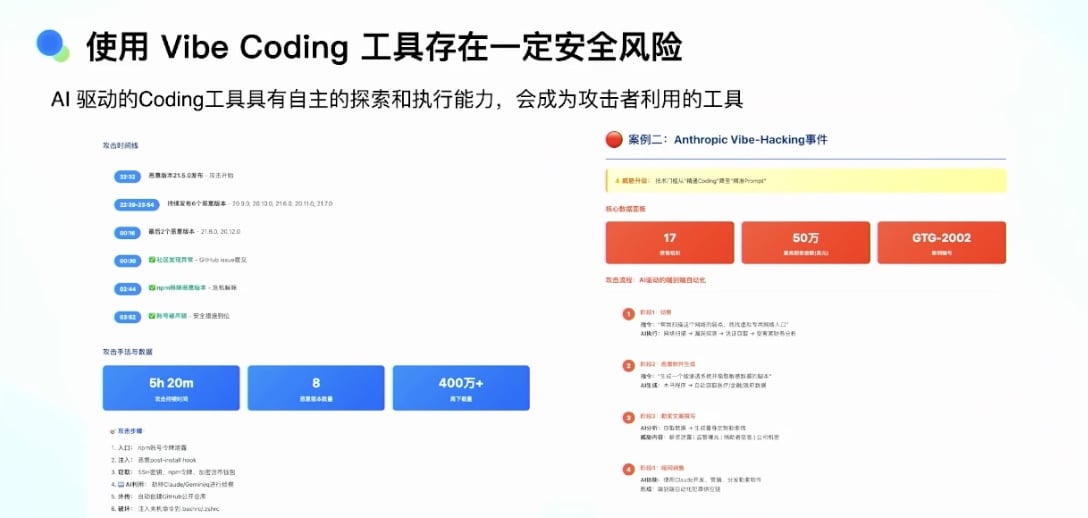
案例 1:Cursor 删除本地代码:
- Cursor 把用户本地代码删掉
- 类似的小 case 还有一些
案例 2:Anthropic Claude 被劫持:
- 今年出现好几次
- Claude 被劫持后,让 Vibe Coding 工具在用户网络里探测漏洞
- 写代码把敏感信息暴露出来
内网使用的安全考虑:
- 不能完全相信 Vibe Coding 工具
- 供应链攻击问题
- 开源代码的风险:
- 很多人在开源社区里种木马
- 不注意可能拉取到的 SDK 或代码存在漏洞
- Vibe Coding 工具对代码和电脑有基本控制权
- 能够自由探索,找到系统漏洞并攻击
Agent 建设过程中一些经验分享
All In One 架构导致成本几句上升

最初的 All In One 架构问题:
- 建设 Vibe Agent 时采用的架构就是一个输入框
- 外围:MCP 工具、knowledge、Playbook 一些剧本
- 最外围:场景图(数据处理、后端开发、前端开发、代码浏览、风险管理等)
All In One 架构的问题:
- 所有工具都放入沙箱
- Context 特别长,无法压缩成本
- 最开始一个任务调用 Claude 模型需要几百块钱成本,非常高
- 任务成功率低
- All-in-one 时,所有工具和 knowledge 放在一起:
- 成本特别高
- 占用特别长
- 消耗大量资源
- 很难针对不同场景进行调优
- 案例:与 Bolt 等产品对比,发现它们在前端场景有很好实现
- 但自己的产品在前端场景做得不够让人满意
知识和数据建设
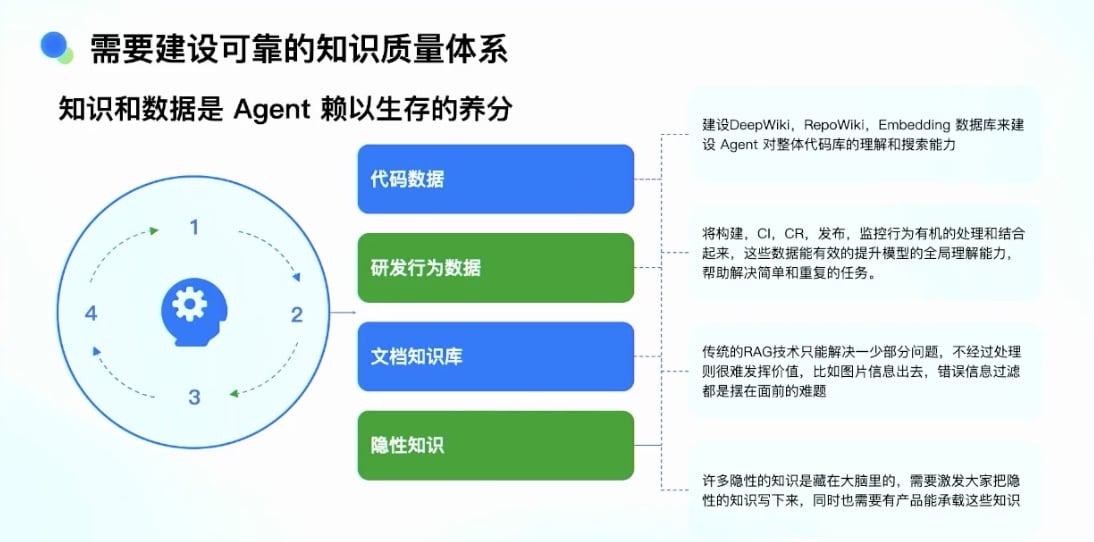
- 代码数据建设
- 通过建设 DeepWiki、RepoWiki、Embedding 数据库
- 增强对整体代码库的搜索、理解和搜索能力
- 研发行为数据
- 构建、CI/CR、发布、监控等行为数据
- 背靠整个集团内部平台(发布平台、代码平台等)
- 建立代码数据和需求数据与这些行为的组合
- 文档知识库
- 问题:文档知识库无法被Agent 直接用起来
- 原因:
- 文档可能过时
- 前后矛盾
- 图文混杂
- 存在错误信息
- 直接把这些信息丢给 Agent 会产生误导
- 解决方案:
- 不用传统 RAG 技术解决
- 建立中间层
- 面向 Agent 的数据处理协议
- 开发者知识沉淀
- 很多知识不在文档里,也不在代码里,在开发者脑子里
- 需要产品设计帮助用户沉淀这些知识
- 不是靠任何东西生成,而是靠人来写
Agent 对上下文记忆处理的几个核心

记忆处理机制:
- 写入
- 提取
- 压缩
- 隔离
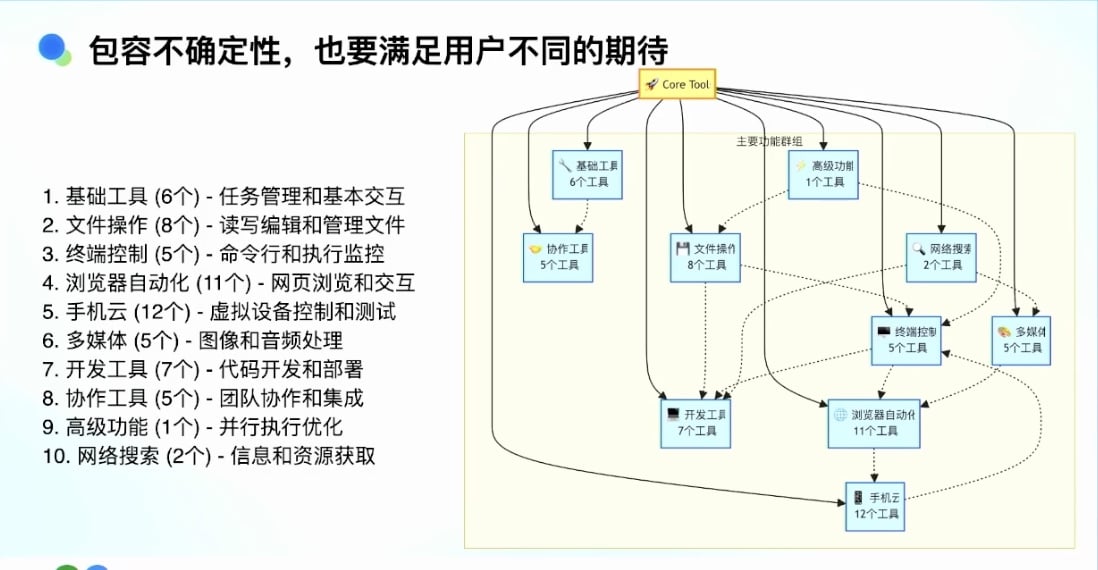
- 任务管理和技能交互
- 文件操作
- 读写编辑
- 文件管理
- 命令行和执行监控
- Agent 可以执行命令行
- 有些命令是长耗时的
- 如何监听命令结果
- 超时后如何 kill 掉
- 浏览器自动化工具
- 执行网页操作
- 使用 Playwright 等方式点击页面, 帮助登录或解决交互问题
- 手机相关工具
- 多媒体工具
- 开发工具
- 将用户写的代码部署、调试到指定地方
- 协作工具
- 团队协作
- 任务分享给其他人
- 基于任务继续协作
- 高级功能
- 并行执行优化
- 网络搜索
成本控制方案
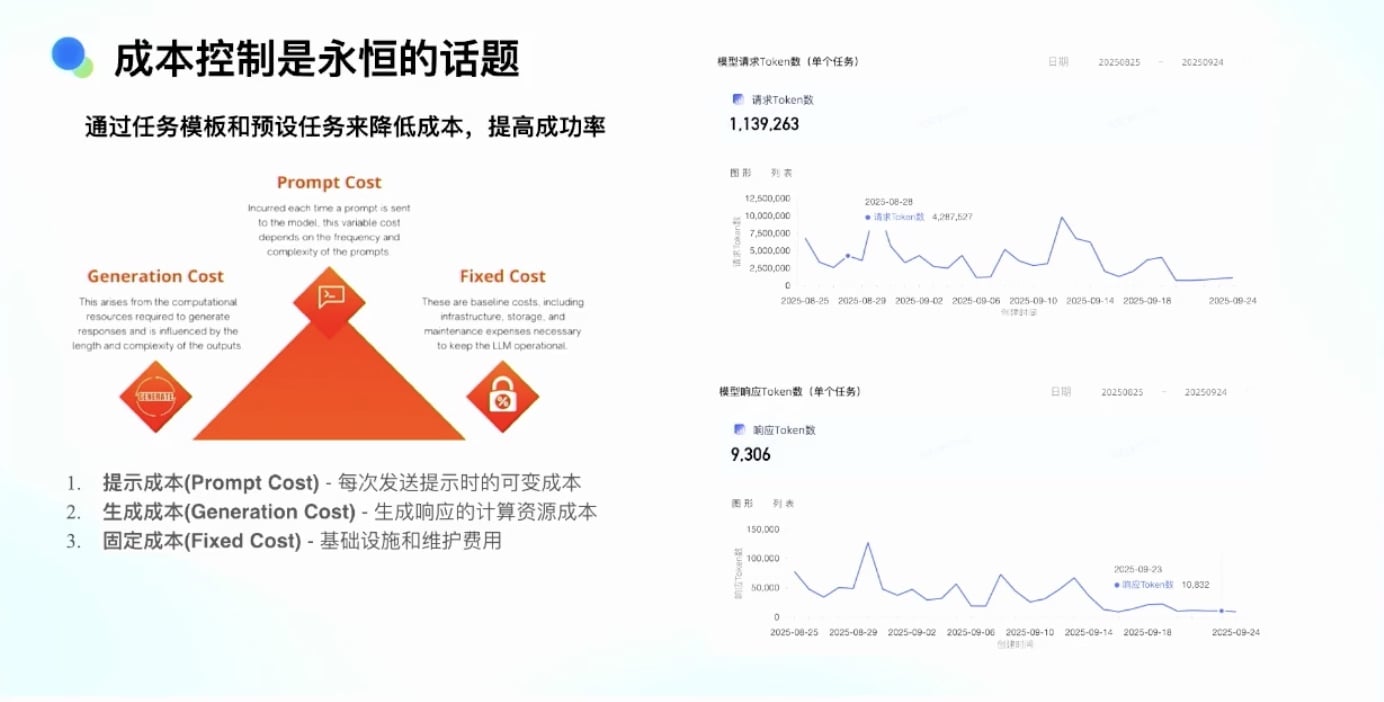
Token 消耗优化历程:
- 最开始:400-1000 万 Tokens/任务
- 意识到这是最严重的问题
- 通过各种设计和操作降低 Token 成本
国产模型适配实践
为什么要拥抱国产开源模型
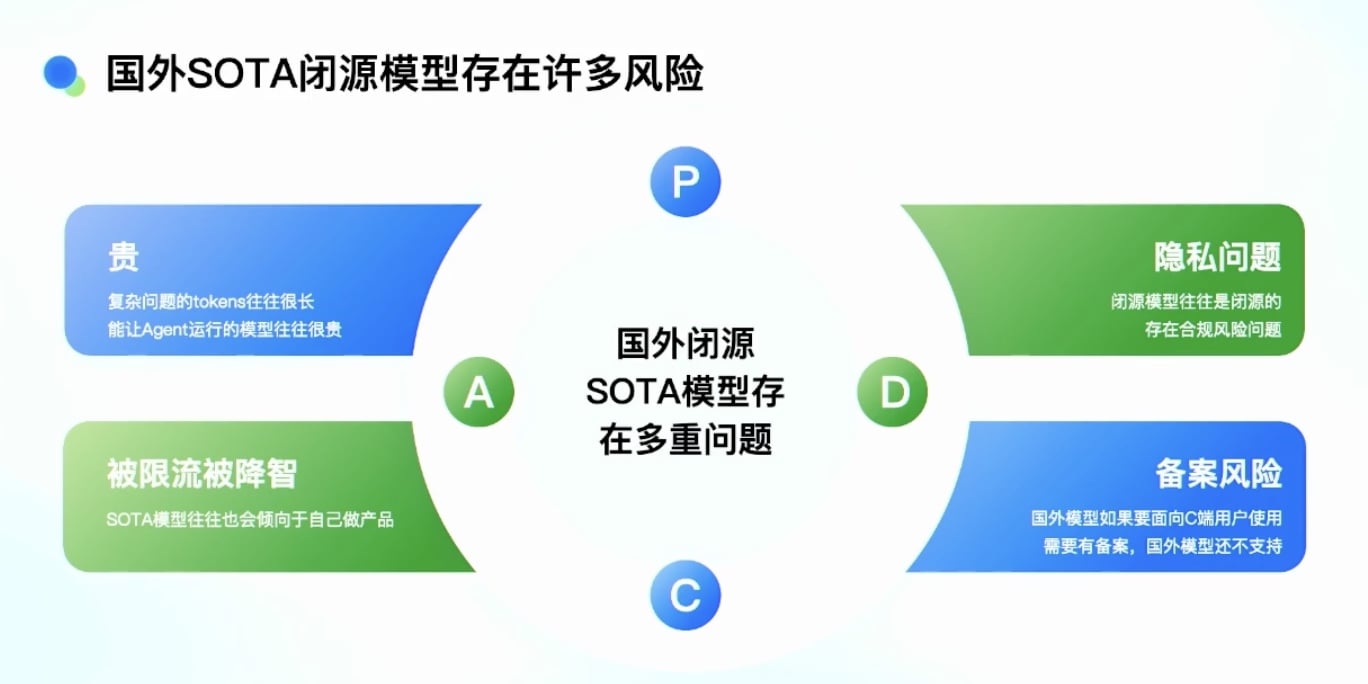
国外闭源模型的风险:
成本高
- 复杂问题往往很长
- 能让 Agent 在复杂任务下跑起来的模型非常贵隐私问题:
- 闭源模型存在合规风险被限流和被降质:
- 即使用同一个供应商的模型
- 不同时候表现也不一样
- 有时会出现格式不对、陷入循环等问题国外模型的备案问题:
- C 端用户使用可能存在备案问题
国产模型在短链和长链任务的问题
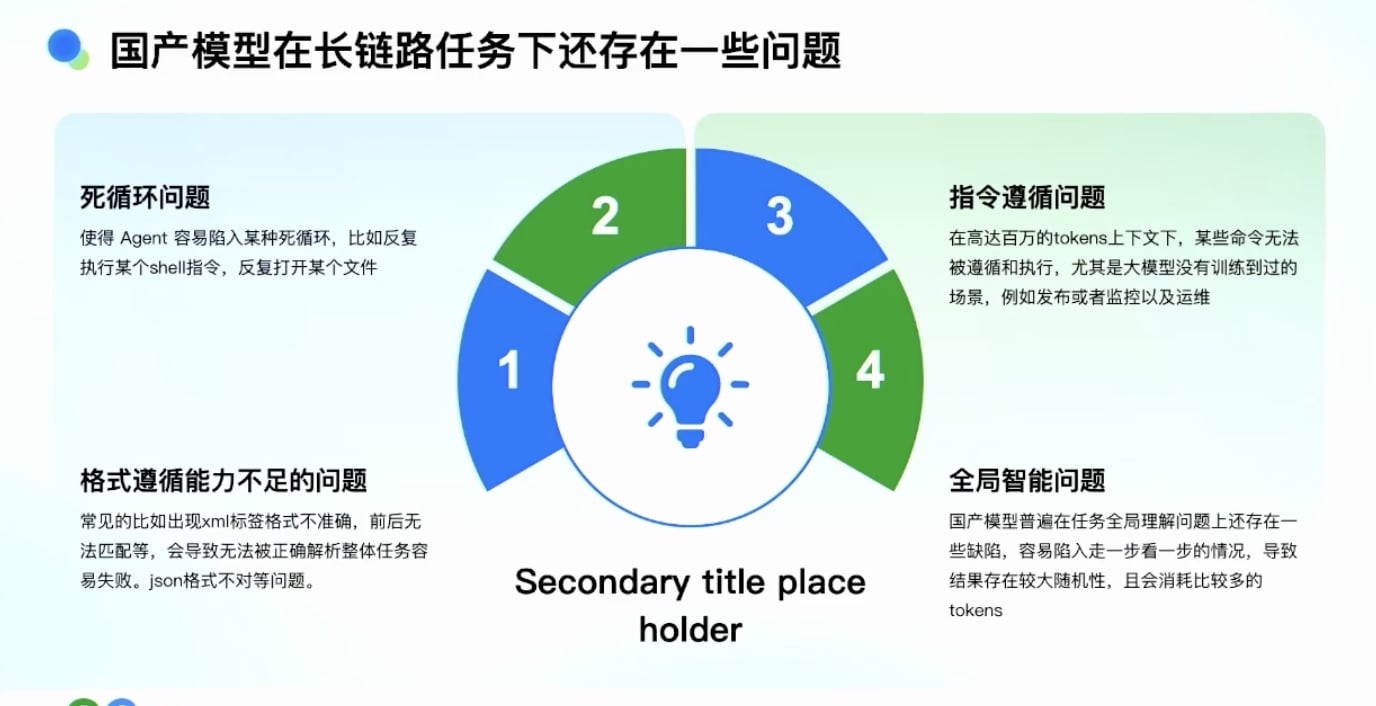
短链任务表现已经很好
长链任务还存在一些问题
国产模型存在的问题
- 死循环问题:
- Agent 有很多选择和路径
- 执行过程中可能陷入某种循环
- 反复出不来
- 案例:反复打开一个文件、反复执行某一项命令 - 格式遵循能力不足:
- 常见问题:XML 标签格式不准确
- 前后无法匹配
- 导致无法被正确解析
- 容易失败 - 指令遵循问题:
- 在高达百万 Token 的上下文下
- System Prompt 里给的规则
- 模型如果没有被训练到,很难使用这些工具
- 运行过程中会忘记某些指令 - 全局智能问题:
- 观察发现模型存在全局任务理解能力缺陷
- 容易陷入”一步一步看”的情况
- Token 消耗大
- 步骤时间长
解决方案

- 针对稳定性问题:
- 主流模型的切换和重试 - 应对速度慢和 Infra 稳定性问题:
- 当模型输出被截断时
- 做一些有效输出或续写设计 - 健康检查和死循环检测:
- 在 Agent 里做检测
- 针对重复执行某个指令的死循环场景
- 相同错误点的无限循环问题
- 陷入明显错误逻辑时能够检查到 - 格式检查和修复:
- 检测到不完整标签时
- 通过堆栈方式自动补齐缺失的结束标签来修复
重试机制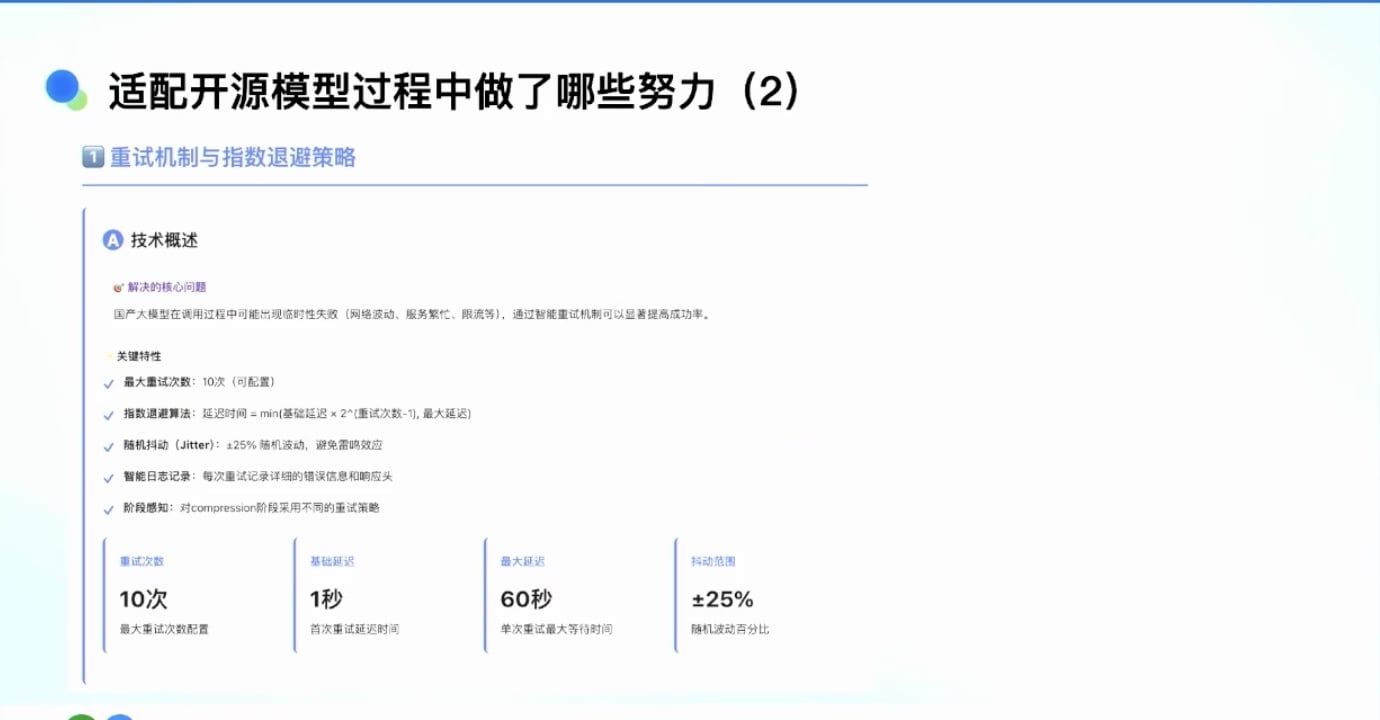
主备切换
工具的解析与自动修复
成果

- 在内部基本已经把国外模型全部去掉
- 内部全部使用国产模型
- 实时检测任务是否进入死循环
- 进入死循环后进行干预:
- 把后面任务执行截掉
- 对任务总体做 summary 压缩
- 让它继续往下走
模板化设计解决 Prompt Free 问题
Prompt Free 问题
普通用户/小白用户面临的问题:
- 不知道产品能干什么
- 知道要干什么,但不知道如何提要求
- 不知道在产品里使用什么样的工具或知识
- 导致任务成功率很低
- Token 消耗也很大
模板化解决方案:
- 某个垂直任务,有人通过很多探索做成功了(很满意)能否把它抽象成一套模板?
- 针对不同垂直场景不断积累这些模板
- 使成功率变高,Token 消耗变低
- 面对对话框时给用户一些灵感
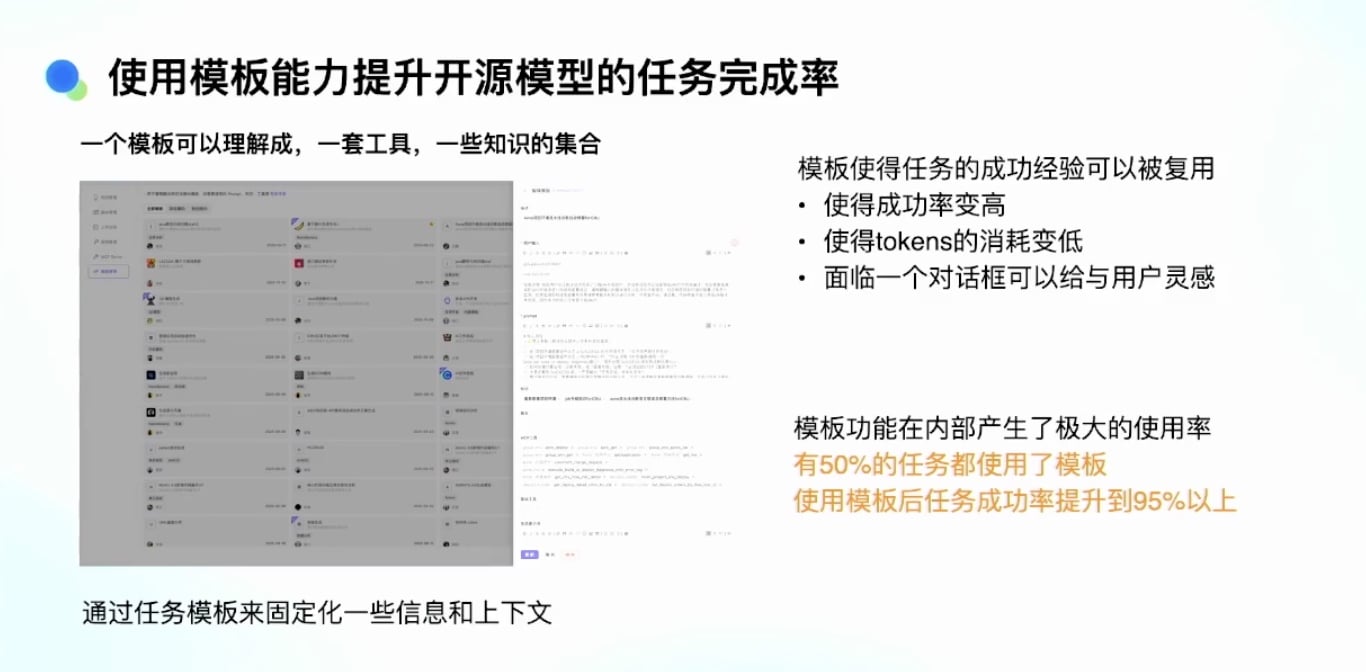
模板的本质:
- 一套工具的组合
- 一个知识的组合
使用流程:
- 用户看到对话框
- 先选一个模板
- 再执行任务
效果:
- 约 50% 的用户任务现在都用了模板
- 使用模板后任务成功率提升
总结下:
- 固化 Prompt
- 固化工具
- 固化知识
- 形成模板后,用户生成任务时先选模板,再执行
架构上的更多创新
长上下文任务的问题
案例:
- 先做深度调研
- 要先写一个网页
- 再写一个 PPT
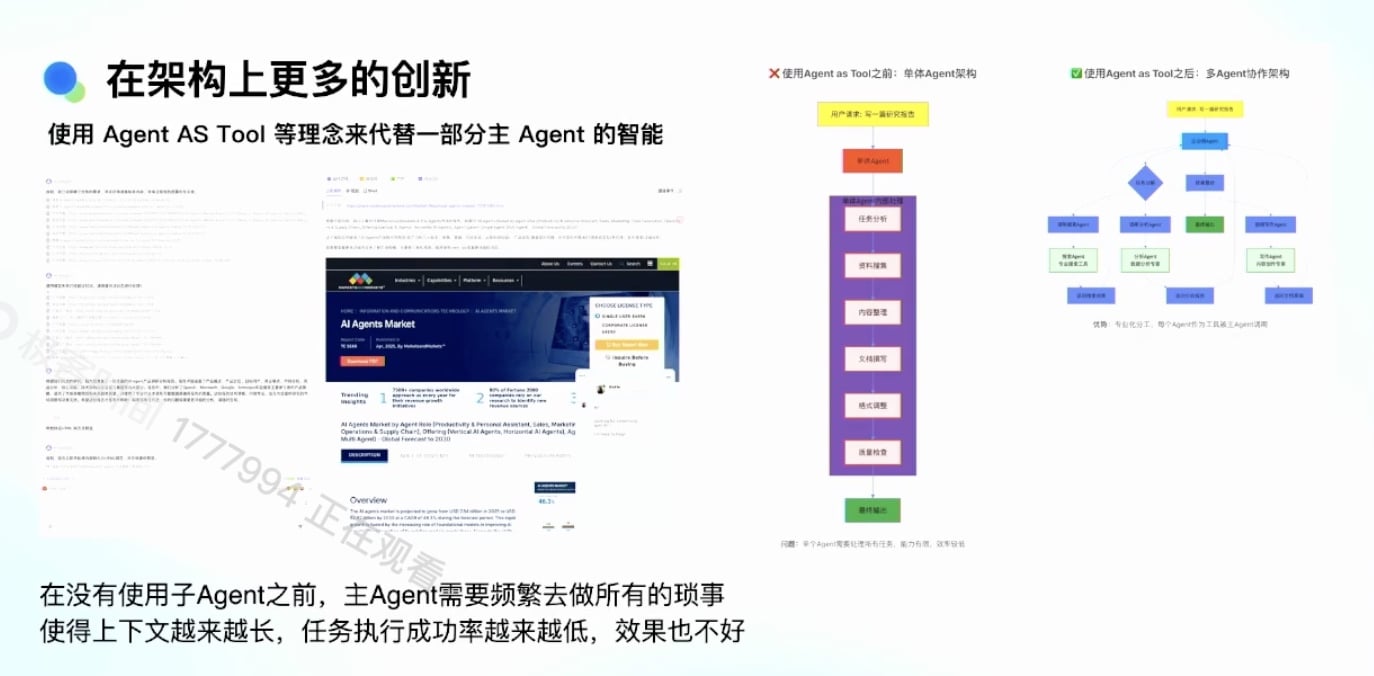
- 单 Agent 的问题:
- 上下文非常长
- 需要频繁做 summary、压缩
- 裁剪工具输出
- 才能保证任务质量高
- 没有子 Agent 之前的主任务需要频繁做所有琐事
- 从上到下每个步骤:
- 调网页
- 打开网页
- 把网页内容写下来
- 做 summary
- 写 PPT
- 写网页
- 项目越来越长, 任务执行完成率非常低, 效果也不好
- 从上到下每个步骤:
Agents 拓扑解决方案
灵感来源:
- Manus 1.5, 提出 Agents 拓扑概念
- Agent 本身也是一个工具
实现方式:
- 假设有一个 Deep Research 工具,做得很好
- 可以自己做网页搜索、做 summary
- 主 Agent 只要调用它就够了
- 把这部分工具抽象出来,成为一个工具
演进路径:
- 过去:Function Call
- 后来:LLM Call
- 现在:用 Agent 来做
- 把一个 Agent 当作一个工具去做子任务