AI coding 智能体设计
理解 AI coding 智能体的设计,可以帮助开发者更好地使用 AI coding 工具,实现开发提效。
了解用户提示词预处理,帮助我们写出高效的用户提示词。例如:为什么在提示词中使用 @字符引入文件、目录作为上下文,可以减少会话轮次?如何自定义命令?
- 了解智能体如何处理 MCP 扩展,如何解析 MCP 的 prompt 和 tool 能力,从而更好的进行 MCP 设计,为 AI coding 智能体提供子命令扩展和工具集扩展。
- 了解 SubAgent 的实现,理解上下文隔离的意义,基于高内聚、低耦合原则进行智能体的模块化设计,降低系统复杂度。
- 了解 MCP 工具调用的局限性,从而理解 Claude Code 推出 Skills、Code Execution with MCP 的动机和原理。
- 为什么规约驱动开发(spec-driven development)成为 AI coding 的最佳实践?通过对开源项目 OpenSpec 的解读,了解规约驱动开发背后的奥秘和改进点。
本文从分析 Gemini-CLI 源代码开始,解读 AI coding 工具的智能体设计。Claude Code 本身不开源,但是实现原理大同小异。
在分析 Gemini-CLI 过程中,特别感谢 Qwen Code 团队,他们的开源项目中的 openaiContentGenerator包提供了OpenAI API的兼容层,使用这个模块可以很容易将 Gemini-CLI 内置的谷歌认证和外部模型切换为公司内部模型。
Gemini-CLI 的用户提示词预处理
在 Gemini-CLI 中输入提示词,首先对输入的内容进行预处理。
- 如果提示词的第一个字符是斜线(/),将提示词视为命令,执行特定操作,或者替换为预置提示词和大模型交互。
- 如果提示词中包含 @字符+路径,检查 @字符后的路径是否存在,读取文件作为上下文,再发送给大模型。可减少不必要的模型会话。
内置命令
Gemini-CLI 的内置命令在 packages/cli/src/ui/commands/目录下定义。
例如
clear命令在文件packages/cli/src/ui/commands/clearCommand.ts中定义。内置命令可以执行特定操作。例如:
/clear命令用于重置对话、清空上下文。
内置命令可以使用预置用户提示词调用大模型完成相关任务。例如:/init 命令使用大模型分析工程代码创建 GEMINI.md 文件。
内置命令列表参见:docs/cli/commands.md。
MCP Server 提供的提示词命令
MCP server 提供两种能力:工具和提示词。工具被拼装为模型上下文,而提示词则作为 Gemini-CLI 的扩展命令。
例如安装 mcp-server-commands命令行工具后,该工具通过
STDIO 协议提供 MCP 服务,在 ~/.gemini/settings.json 配置示例如下:
1 | { |
在 Gemini-CLI 中输入斜线触发命令补全,可以看到新增的 run_command 命令,该命令有[MCP]标识和内置命令相区分:
1 | ╭─────────────────────────────────────────────────────────────────────────╮ |
扩展包提供的提示词命令
从 Gemini-CLI 的官方扩展市场下载扩展。扩展包安装在 ~/.gemini/extensions目录下,每个扩展下面的 commands/子目录提供扩展命令。
以gemini-cli-security扩展为示例,安装命令如下:
1 | $ gemini extensions install \ |
安装后重启 Gemini-CLI,执行命令 /extensions list查看安装的扩展:
1 | > /extensions list |
在 Gemini-CLI 中输入斜线触发命令补全,可以看到由扩展引入的新命令命令,这些命令有[
1 | ╭─────────────────────────────────────────────────────────────────────────╮ |
本地文件自定义命令
用户可以通过在特定目录下创建 *.toml文件,创建扩展命令。
- 用户级:
~/.gemini/commands/*.toml - 项目级:
<project>/.gemini/commands/*.toml - 扩展级:
<extension>/commands/*.toml(扩展包提供的命令扩展)
扩展文件名(包含相对路径名)作为扩展命令,文件内容定义提示词。
- prompt = “提示词”
- description = “命令描述(可选)”
@路径扩展
在提示词中出现的"@路径",在将提示词发送给大模型之前会提前读取相关文件(如果路径是目录名,会读取目录下所有文件)作为上下文,可以减少一轮或多轮和大模型的对话,提升效率。
Gemini-CLI 的工具注册和工具调用
在 Gemini-CLI 和大模型会话中,将工具列表作为上下文提供给大模型,由大模型决定是否调用,Gemini-CLI 接收到大模型的调用指令请求,由 Gemini-CLI 执行相应的调用指令,将命令输出作为上下文提供大模型,最终完成相应的任务。
注册核心工具
Gemini-CLI 内置的核心工具在 packages/core/src/tools/目录下定义,通过调用 packages/core/src/config/config.ts的createToolRegistry方法对工具注册。
可以通过配置文件中的 coreTools(如:"coreTools": ["ReadFileTool", "GlobTool", "ShellTool(ls)"])限制工具的访问,默认所有内置工具均可用。
这些核心工具,每个工具使用 TypeScript 实现相关功能,或者调用外部命令实现。
核心工具如下表所示:
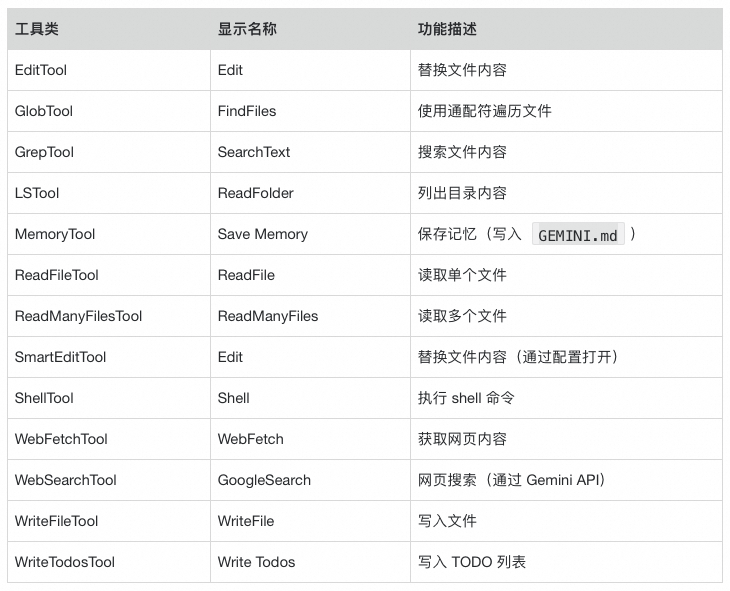
子智能体注册为工具
目前只有一个子智能体(SubAgent):CodebaseInvestigatorAgent,用于针对复杂请求的代码分析工作。Gemini-CLI 将子智能体 CodebaseInvestigatorAgent封装为工具,和其他工具以同样的流程调用。该子智能体被设置为只能使用只读工具。
子智能体在执行时有隔离的上下文空间,不会污染主智能体的上下文,通过高内聚松耦合的子智能体,有效降低智能体设计的复杂度。目前 Claude Code 已经提供用户自定义子智能体功能。

用户自定义工具
还支持通过用户指定命令提供自定义工具的发现。用配置tools.discoveryCommand设置自定义工具的发现命令(如 bin/get_tools),该命令的输出是一个 JSON 数组,提供自定义工具的定义。
参见 docs/get-started/configuration.md中的示例:
1 | "tools": { |
MCP 注册为工具
通过 settings.json配置的 MCP Servers,以及扩展(extensions)包含的 MCP
Servers,用于发现自定义工具。
在 settings.json中每一个 mcpServers.<SERVER_NAME>小节支持三种 MCP
配置:stdio/SSE/streamable HTTP。
command、args、env、cwd:用于设置 stdio 协议 MCP 连接。url:用于 SSE 协议。httpUrl:用于 streamable HTTP 协议。headers:设置 HTTP 头。includeTools、excludeTools:从 MCP 服务中包含和排除工具。
示例:
1 | { |
MCP client 连接 MCP server 将返回注册到工具列表。参见代码文件 packages/core/src/tools/mcp-client-manager.ts、 packages/core/src/tools/mcp-client.ts。
流程图如下:
1 | 1. maybeDiscoverMcpServer (入口) |
工具列表作为上下文提供给大模型
会话时,工具列表作为上下文传递给大模型。这个过程中,MCP server 提供的工具和内置工具一样写入上下文。一个 MCP server 可能会广播上百个工具,如果一个 AI coding 智能体添加了过多的 MCP server,太多的 MCP 工具会导致大模型上下文爆炸。即使少量配置的 MCP server,对于大部分场景用不到的 tools,会大量消耗大模型 token,非常不经济。
Claude Code 引入和 Skills 扩展,以及提出了大模型通过编码调用 MCP,都是为了解决传统 MCP 工具广播造成的 token 爆炸问题。
Gemini-CLI 中相关执行链路:
1 | 1. 工具注册 |
Gemini API 的提示词中封装工具列表,示例如下:
1 | { |
OpenAI 兼容 API 的提示词中封装工具列表,示例如下:
1 | { |
大模型工具调用请求和结果返回
大模型如果判断需要执行相应工具,会在输出中包含工具调用。
Gemini API 的工具调用请求:
1 | // 从响应中提取的格式 |
OpenAI 兼容API的工具调用请求:
1 | { |
Gemini-CLI 执行相关命令后,执行结果以 JSON格式封装。
GEMINI API 将执行结果作为用户消息的一部分返回,格式示例:
1 | // 作为用户消息的一部分发送 |
OpenAI 兼容 API 将工具返回以新的 role(tool)返回:
1 |
|
Gemini-CLI 的架构设计
Gemini-CLI、Claude Code 不但是强大的 AI coding 工具,用户也可以将其扩展为更加通用的智能体。例如在Claude Agent SDK文档中写到 Claude Code 可以扩展为:
- 编程类智能体:
- 诊断并修复生产环境问题的 SRE(站点可靠性工程)智能体
- 审查代码漏洞的安全审计机器人
- 对突发事件进行分类处理的值班工程师助手
- 强制执行代码风格与最佳实践的代码审查智能体
- 业务类智能体:
- 审核合同与合规性的法律助手
- 分析财务报告与预测的金融顾问
- 解决技术问题的客户支持智能体
- 为营销团队提供内容创作支持的助手
分析 Gemini-CLI 架构,理解智能体设计,通过扩展放大智能体能力为我所用。
流程图
Gemini-CLI 智能体流程图如下: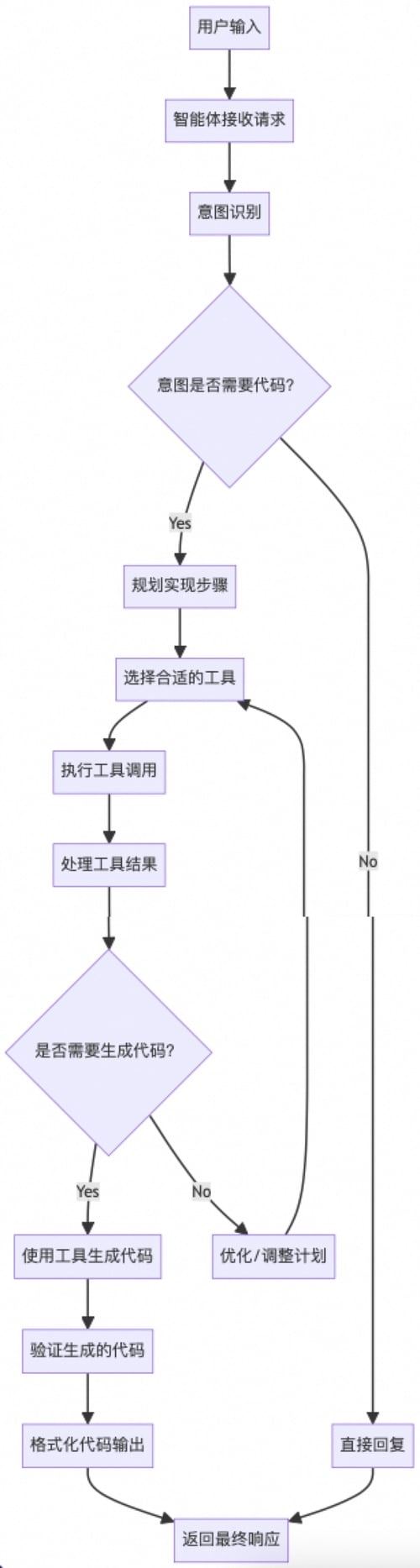
意图识别和智能路由
意图识别步骤是代码生成流程的第一阶段。当用户向 Gemini-CLI 提交请求时,系统必须首先理解用户想要完成什么任务,分析确定请求是需要代码生成还是可以通过直接响应来处理。
意图识别主要通过提示词工程和智能体ReAct架构实现。
文件packages/core/src/core/prompts.ts中的主系统提示词包含指导模型分析用户请求的特定指令:
- 对于软件工程任务,模型被指示思考用户请求和相关代码库上下文。
- 模型被指示使用 CodebaseInvestigatorAgent处理复杂任务或使用直接工具处理简单搜索。
- 提示提供了一个结构化的工作流程,用于在采取行动之前理解和制定代码库上下文策略。
- 详见后面的”主系统提示词”。
路由决策主要通过提示工程实现,配合少量支持代码。
- 没有显式的路由代码:路由决策由模型根据系统提示自主做出,而非硬编码的条件判断。
- 配置驱动可用性:智能体是否可用由配置决定,影响工具列表。
- 提示工程实现路由:系统提示明确指导何时使用智能体、何时使用直接工具。
- 工具化智能体:通过SubagentToolWrapper将智能体包装为工具,使其可被模型调用。
相关调用链路如下:
1 |
|
主流程的 ReAct 框架
简单的编码任务,不使用CodebaseInvestigatorAgent子智能体,在主流程的
ReAct 架构中实现。
- 文件
packages/cli/src/nonInteractiveCli.ts中的 while 循环。 - Reasoning:用
geminiClient.sendMessageStream()调用模型。 - Acting:
用executeToolCall()执行工具。 - Observing:收集
toolResponseParts。 - Updating:将结果设为
currentMessages,继续循环。
以一个简单的编码任务为例,流程如下:
1 | 用户输入: "在 helper.ts 中添加 formatDate 函数" |
子智能体的 ReAct 框架
子智能体CodebaseInvestigatorAgent封装为一个工具,针对复杂的软件工程场景,大模型第一轮返回对子智能体 CodebaseInvestigatorAgent的调用请求。于是 Gemini-CLI 调用子智能体对本地代码工程做分析,查找代码文件和内容。
子智能体有自己的系统提示词,参见后面的”代码库调查 SubAgent 的系统提示词”。
子智能体的运行的 ReAct 框架代码见文件:packages/core/src/agents/executor.ts。
流程图如下:
1 | ┌─────────────────────────────────────────────────────────────┐ |
完成编码
完成编码任务是通过大模型返回的工具调用实现的。
1 | 用户请求 (fixing bugs, adding features) |
针对要修改的文件,模型通过 functionCall 返回修改请求,示例如下:
1 | { |
针对要替换或新增的文件,模型返回 WriteFileTool
(创建新文件或覆盖),示例如下:
1 | { |
工具执行完成后,结果被封装为 functionResponse
并添加到对话历史,在下次请求时发送给模型:
1 | { |
记忆压缩
记忆压缩的触发条件:
- 用户提示词超过最大值的 20%(
DEFAULT_COMPRESSION_TOKEN_THRESHOLD),启动压缩。 - 记忆压缩方法:
- 使用
findCompressSplitPoint函数找到压缩分割点。 - 保留最近 30% 的对话历史 (
COMPRESSION_PRESERVE_THRESHOLD = 0.3)。 - 使用大模型和提示词,将较早的历史通过模型进行总结压缩。提示词参见后面的”记忆压缩系统提示词”。
- 如果压缩后 token 数量反而增加,则标记为压缩失败。
记忆压缩的完整流程图如下:
1 | 触发点:sendMessageStream() 发送消息前 |
Gemini-CLI 的预置提示词
Gemini-CLI 的意图理解、智能路由能力,大部分是通过提示词实现的。
主系统提示词
参见文件 packages/core/src/core/prompts.ts的 getCoreSystemPrompt()方法。
关于主系统提示词的说明:
- 主系统提示词由以下所示的 preamble、coreMandates、primaryWorkflows*
- 等几个部分组成。
- 可以通过环境变量
GEMINI_PROMPT_*(如GEMINI_PROMPT_PREAMBLE=false)关闭相关的提示词。 - 提示词中的类似
${CodebaseInvestigatorAgent.name}的语法是变量替换。 - 提示词中的类似
${(function () { ... }()的语法是 IIFE(立即执行函数表达式),以便利用更加灵活的条件判断等指令生成字符串。 - 可以使用文件绕过系统提示词,使用文件内容作为系统提示词(不建议):
- 如果有环境变量
GEMINI_SYSTEM_MD,使用该环境变量指向的文件作为系统提示词。 - 默认检查是否存在文件
~/.gemini/system.md,如果存在则使用该文件作为系统提示词。
系统提示词的中文译文如下:
1.Preamble
1 | 你是一个专门从事软件工程任务的交互式 CLI 代理。 |
2.CoreMandates
1 | # 核心职责 |
3.PrimaryWorkflows_ (根据不同条件选择不同提示词)*
- primaryWorkflows_prefix_ci_todo(if enableCodebaseInvestigator &&
enableWriteTodosTool)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# 主要工作流程
## 软件工程任务
当被要求执行诸如修复错误、添加功能、重构或解释代码等任务时,
请遵循以下步骤:
1. **理解与策略:** 思考用户请求以及相关的代码库上下文。
当任务涉及**复杂的重构、代码库探索或系统级分析**时,
你的**第一且主要的工具**必须是「${CodebaseInvestigatorAgent.name}」。
使用它来全面了解代码、其结构和依赖关系。
对于**简单的、有针对性的搜索**(如查找特定函数名、文件路径或变量声明),
你应该直接使用「${GREP_TOOL_NAME}」或「${GLOB_TOOL_NAME}」。
2. **计划:** 基于第一步的理解,制定一个连贯且有根据的计划,
说明你打算如何解决用户的任务。
如果使用了「${CodebaseInvestigatorAgent.name}」,
请不要忽视其输出,你必须将其作为计划的基础。
对于复杂任务,将其分解为更小、可管理的子任务,
并使用「`${WRITE_TODOS_TOOL_NAME}`」工具跟踪进度。
如果有助于用户理解你的思路,
请提供一个极为简洁但清晰的计划。
在计划中,应包含编写单元测试来验证更改的迭代开发过程,
并在过程中使用输出日志或调试语句辅助实现解决方案。 - PrimaryWorkflows_prefix_ci(if enableCodebaseInvestigator)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 主要工作流程
## 软件工程任务
当被要求执行诸如修复错误、添加功能、重构或解释代码等任务时,
请遵循以下顺序:
1. **理解与制定策略:** 思考用户的要求和相关代码库的上下文。
当任务涉及**复杂重构、代码库探索或系统范围分析**时,
您的**第一个且主要的工具**必须是 '${CodebaseInvestigatorAgent.name}'。
使用它来全面了解代码、其结构和依赖关系。
对于**简单的、有针对性的搜索**(如查找特定函数名、文件路径或变量声明),
您应直接使用 '${GREP_TOOL_NAME}' 或 '${GLOB_TOOL_NAME}'。
2. **规划:** 基于第一步的理解,构建一个连贯且有根据的计划
来解决用户的任务。
如果使用了 '${CodebaseInvestigatorAgent.name}',
请不要忽视其输出,您必须将其作为计划的基础。
如果这有助于用户理解您的思考过程,
请与用户分享一个极其简洁但清晰的计划。
作为计划的一部分,您应该使用迭代开发过程,
包括编写单元测试来验证您的更改。
在这个过程中使用输出日志或调试语句来得出解决方案。 - PrimaryWorkflows_todo(if enableWriteTodosTool)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 主要工作流程
## 软件工程任务
当被要求执行诸如修复错误、添加功能、重构或解释代码等任务时,
请遵循以下步骤:
1. **理解:** 思考用户请求及相关代码库上下文。
广泛使用 '${GREP_TOOL_NAME}' 和 '${GLOB_TOOL_NAME}' 搜索工具
(若独立则并行使用),以了解文件结构、现有代码模式和规范。
使用 '${READ_FILE_TOOL_NAME}' 和 '${READ_MANY_FILES_TOOL_NAME}'
来理解上下文并验证你可能有的任何假设。
2. **计划:** 制定一个连贯且有根据(基于第1步的理解)的计划,
说明你打算如何解决用户的任务。
对于复杂的任务,将其分解为更小、易于管理的子任务,
并使用 \`${WRITE_TODOS_TOOL_NAME}\` 工具来跟踪你的进度。
如果有助于用户理解你的思路,
可向用户提供一个极其简洁但清晰的计划。
作为计划的一部分,你应该采用包含编写单元测试
以验证更改的迭代开发过程。
在此过程中使用输出日志或调试语句来得出解决方案。 - PrimaryWorkflows_prefix
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 主要工作流程
## 软件工程任务
当被要求执行诸如修复错误、添加功能、重构或解释代码等任务时,
请遵循以下步骤:
1. **理解:** 思考用户的需求以及相关的代码库上下文。
广泛使用 '${GREP_TOOL_NAME}' 和 '${GLOB_TOOL_NAME}' 搜索工具
(如果独立则并行使用),以了解文件结构、现有代码模式和规范。
使用 '${READ_FILE_TOOL_NAME}' 和 '${READ_MANY_FILES_TOOL_NAME}'
来理解上下文并验证你可能有的任何假设。
2. **计划:** 制定一个连贯且基于第一步理解的计划,
说明你打算如何解决用户的任务。
如果对用户理解你的思路有帮助,
可以向用户提供一个极其简洁但清晰的计划。
作为计划的一部分,你应该采用包含编写单元测试
来验证更改的迭代开发过程。
在这一过程中使用输出日志或调试语句来得出解决方案。
4.PrimaryWorkflows_suffix
1 | # 主要工作流程 |
5.OperationalGuidelines
1 | # 操作指南 |
6.Sandbox
1 | ${(function () { |
7.Git
1 | ${(function () { |
8.FinalReminder
1 | # 最终提醒 |
记忆压缩系统提示词
记忆压缩的触发条件:
用户提示词超过最大值的 20%(DEFAULT_COMPRESSION_TOKEN_THRESHOLD),启动压缩。
记忆压缩方法:
- 使用
findCompressSplitPoint函数找到压缩分割点。 - 保留最近 30% 的对话历史 (
COMPRESSION_PRESERVE_THRESHOLD = 0.3)。 - 使用大模型和提示词,将较早的历史通过模型进行总结压缩。
- 如果压缩后 token 数量反而增加,则标记为压缩失败。
记忆压缩系统提示词如下(文件 packages/core/src/core/prompts.ts 的 getCompressionPrompt()方法)。译文如下:
1 | 你是负责将内部聊天历史总结为给定结构的组件。 |
代码库调查 SubAgent 的系统提示词
代码库调查以 SubAgent 方式定义,目前属于实验功能。
- 默认开启,可以通过配置
experimental.codebaseInvestigatorSettings.enabled = false关闭。 - SubAgent 和其他内部工具以工具方式注册,通过工具调用方式执行。
- 仅允许运行只读工具,如:
[LS_TOOL_NAME, READ_FILE_TOOL_NAME, GLOB_TOOL_NAME, GREP_TOOL_NAME]
代码库调查 SubAgent 的系统提示词译文如下:
1 | 你是**代码库调查员**, |
内置/init命令生成 GEMINI.md用户提示词
内置/init命令使用预置用户提示词,调用大模型分析本地工程,创建GEMINI.md文件。
预置的用户提示词英文版参见文件:packages/cli/src/ui/commands/initCommand.ts
翻译成中文如下:
1 | 你是一个AI代理, |
AI coding 工具的能力扩展
Gemini-CLI 的可扩展性设计
从上述 Gemini-CLI 的代码分析,可以看到 Gemini-CLI 提供了强大的可扩展性设计。
| 扩展能力 | 说明 |
|---|---|
| 命令 | 通过在特定文件夹创建 TOML 文件,创建自定义命令: * 用户级自定义命令:在 ~/.gemini/commands/目录下创建 *.toml文件。* 项目级自定义命令:在 .gemini/commands/)下创建 *.toml文件。 |
| MCP | 通过配置文件添加 MCP Serrver。 即在 ~/.gemini/settings.json配置 MCP 服务,通过三方的 MCP Server 提供扩展的 prompts 和 tools。其中 prompt 提示词作为子命令,工具则传递给大模型使用。 |
| 工具 | 小众,可忽略。 可以通过 ~/.gemini/settings.json配置 tools.discoveryCommand,该命令用于提供用户自定义的工具列表。 |
| 子智能体 | 暂不支持自定义子智能体。 提供子智能体扩展框架,目前仅有一个可用的实验阶段的子智能体,不提供用户自定义子智能体扩展的机制,未来应会支持。短期可以参考 Codebase Investigator 子智能体硬编码实现。 |
| 插件扩展 | 支持通过安装扩展(extension)提供附加的命令、MCP。 提供官方扩展市场 |
| 记忆管理 | 工程目录下的 GEMINI.md保存工程长期记忆,可以用/init命令生成。支持通过配置文件定义多个上下文文件,例如 AGENTS.md。{ ”context”: { ”fileName”: [“AGENTS.md”, “CONTEXT.md”, “GEMINI.md”] } } |
Claude Code 的可扩展性设计
Claude Code 无论模型还是命令行工具都是 AI coding 领域的 SOTA,代码不开源,仅从使用角度介绍 Claude Code 的可扩展设计。
| 扩展能力 | 说明 |
|---|---|
| 命令 | 通过在特定文件夹创建 Markdown 文件,创建自定义命令: 用户级自定义命令:在 ~/.claude/commands/目录下创建 *.md文件。项目级自定义命令:在 .claude/commands/)下创建 *.md文件。参见文档 |
| MCP | 使用 claude scp 命令为 Claude 添加MCP,支持不同协议、不同的 scope:* claude mcp add --transport http sentry https://mcp.sentry.dev/mcp* claude mcp add --transport sse --scope project atlassian https://mcp.atlassian.com/v1/sse * claude mcp add --transport stdio --scope user clickup --env CLICKUP_API_KEY=YOUR_KEY --env CLICKUP_TEAM_ID=YOUR_ID -- npx -y @hauptsache.net/clickup-mcp当配置了越来越多的 MCP Server,会导致大模型上下文爆炸,还有调用多个 MCP 工具时,中间数据向大模型传递也不经济。Claude Code 的博客介绍了一个新的方案:使用代码执行MCP,解决 MCP 以上两个问题。 参见文档1 参见文档2 |
| Hooks | 类似 Git 的 Hooks,Claude 通过 hook 脚本机制确保在 Cluade 执行步骤中执行特定脚本,实现如通知、格式化文件等能力。支持的 Hook 脚本: * PreToolUse:在工具调用前运行(可阻止调用) * PostToolUse:在工具调用完成后运行 * UserPromptSubmit:在用户提交提示后、Claude 处理之前运行 * Notification:在 Claude Code 发送通知时运行 * Stop:在 Claude Code 完成响应时运行 * SubagentStop:在子智能体任务完成时运行 * PreCompact:在 Claude Code 即将执行压缩操作前运行 * SessionStart:在 Claude Code 启动新会话或恢复已有会话时运行 * SessionEnd:在 Claude Code 会话结束时运行 参见文档 示例项目 |
| Skills | 在用户主目录(~/.claude/skills/)或项目目录(.claude/skills/)下创建Skills。和 MCP 等工具的区别在于懒加载。 * 初始只加载 SKILL.md的YAML头中的名称和描述(小于1k)。 * 如果模型确定某 skill 和任务相关,再二次加载完整的SKILL.md到上下文。 * 也可以将 SKILL.md文档拆解为多个文档,在文档中引用其他文档。Claude 会三次加载这些文件。 * 最终调用 Skill 中的命令脚本,执行命令后将执行结果发给大模型。 参见文档1 参见文档2 Anthropics 官方 Skills 扩展 |
| 子智能体 | 可以使用 /agents命令创建新的子智能体。子智能体通过 Markdown 文件定义,可以保存在全局目录( ~/.claude/agents/)或者项目级目录(.claude/agents/)。参见文档 |
| 插件扩展 | 提供插件(plugins)扩展机制,使用 /plugin命令安装插件,插件支持对命令、Agent、Hook、MCP扩展。 没有官方插件市场,可以自建或将某个 GitHub 仓库添加为插件市场。 参见文档 |
| 记忆管理 | 工程目录下的 CLAUDE.md保存工程长期记忆,可以用/init命令生成。 |
| Claude Agent SDK | 提供 TypeScript 和 Python 语言的 SDK,提供更加强大的定制整合能力。 参见文档 |
MCP 服务扩展
规约驱动开发模式(spec-driven development)
开源软件OpenSpec提供了完整的 spec-driven 开发模式,支持对各种 AI coding 工具的整合。整合方法如下:
- 创建两个公共文件:
- 在项目中创建
openspec/AGENTS.md文件。该文件是 OpenSpec 使用的指南文档。 - 在项目中创建
openspec/project.md文件。该文件内容中包含占位字符,用户需要按照模板完善文件内容,定义项目代码格式规范、架构、测试框架等。
- 在项目中创建
- 更新工具的核心记忆文件(例如:
CLAUDE.md),在文件头新增 spec-driven 开发模式描述信息。 - 针对用户选择支持的 AI coding工具,创建三个子命令(如果支持命令扩展的话)。以 Claude Code 为例:
- 文件
.claude/commands/openspec/proposal.md:分析用户需求,生成 proposal、tasks 等 Markdown 文件。 - 文件
.claude/commands/openspec/apply.md:遵循前一步生成的 spec,按照tasks 描述步骤开发。 - 文件
.claude/commands/openspec/archive.md:将开发完毕的 spec 存档到archive 目录,避免影响后续开发。
- 文件
开发过程,运行次序如下:
先运行指令创建 spec:
openspec:proposal 详细述求说明... ...运行指令,开始代码生成:
openspec:apply最后运行指令将 spec 文件归档:
openspec:archive
AI CODING 工具记忆文件(如 CLAUDE.md)头部插入的提示词
- 原始英文提示词,参见
- 中文翻译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<!-- OPENSPEC:START -->
# OpenSpec 指令
这些指令适用于在此项目中工作的AI助手。
当请求满足以下条件时,请始终打开 \`@/openspec/AGENTS.md\`:
- 提及规划或提案(如 proposal、spec、change、plan 等词汇)
- 引入新功能、破坏性变更、架构调整或重要的性能/安全工作
- 内容听起来含糊不清,您需要在编码前获取权威规范
使用 \`@/openspec/AGENTS.md\` 来学习:
- 如何创建和应用变更提案
- 规范格式和约定
- 项目结构和指南
请保留此管理块,以便 'openspec update' 可以刷新指令。
<!-- OPENSPEC:END -->
文件openspec/AGENTS.md中的提示词
- 原始英文提示词,参见
- 中文翻译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
# OpenSpec 指令
使用 OpenSpec 进行规范驱动开发的 AI 编码助手指令。
## TL;DR 快速检查清单
- 搜索现有工作:\`openspec spec list --long\`,\`openspec list\`(仅全文搜索使用 \`rg\`)
- 决定范围:新增能力 vs 修改现有能力
- 选择唯一的 \`change-id\`:kebab-case,动词开头(\`add-\`,\`update-\`,\`remove-\`,\`refactor-\`)
- 脚手架:\`proposal.md\`,\`tasks.md\`,\`design.md\`(仅需要时),以及每个受影响能力的增量规范
- 编写增量:使用 \`## ADDED|MODIFIED|REMOVED|RENAMED Requirements\`;每个需求至少包含一个 \`#### Scenario:\`
- 验证:\`openspec validate [change-id] --strict\` 并修复问题
- 请求批准:在提案获批前不要开始实施
## 三阶段工作流
### 第1阶段:创建变更
当需要以下操作时创建提案:
- 添加功能或特性
- 进行破坏性变更(API、schema)
- 更改架构或模式
- 优化性能(更改行为)
- 更新安全模式
触发词(示例):
- "Help me create a change proposal"
- "Help me plan a change"
- "Help me create a proposal"
- "I want to create a spec proposal"
- "I want to create a spec"
宽松匹配指导:
- 包含其中一个:\`proposal\`,\`change\`,\`spec\`
- 以及其中一个:\`create\`,\`plan\`,\`make\`,\`start\`,\`help\`
跳过提案的情况:
- Bug修复(恢复预期行为)
- 拼写错误、格式、注释
- 依赖更新(非破坏性)
- 配置更改
- 现有行为的测试
**工作流程**
1. 查看 \`openspec/project.md\`,\`openspec list\` 和 \`openspec list --specs\` 以了解当前上下文。
2. 选择一个唯一的动词开头的 \`change-id\` 并创建脚手架 \`proposal.md\`,\`tasks.md\`,可选的 \`design.md\`,以及 \`openspec/changes/<id>/\` 目录下的增量规范。
3. 使用 \`## ADDED|MODIFIED|REMOVED Requirements\` 草拟规范增量,每个需求至少有一个 \`#### Scenario:\`。
4. 运行 \`openspec validate <id> --strict\` 并在分享提案前解决任何问题。
### 第2阶段:实施变更
将这些步骤作为待办事项跟踪并逐一完成。
1. **阅读 proposal.md** - 了解要构建的内容
2. **阅读 design.md**(如果存在) - 查看技术决策
3. **阅读 tasks.md** - 获取实施清单
4. **按顺序实施任务** - 按顺序完成
5. **确认完成** - 在更新状态前确保 \`tasks.md\` 中的每一项都已完成
6. **更新清单** - 所有工作完成后,将每个任务设置为 \`- [x]\` 以便列表反映实际情况
7. **批准关卡** - 提案审查和批准前不要开始实施
### 第3阶段:归档变更
部署后,创建单独的 PR 来:
- 移动 \`changes/[name]/\` → \`changes/archive/YYYY-MM-DD-[name]/\`
- 如果能力发生变化则更新 \`specs/\`
- 对于仅工具变更使用 \`openspec archive <change-id> --skip-specs --yes\`(始终显式传递变更ID)
- 运行 \`openspec validate --strict\` 确认归档的变更通过检查
## 任何任务之前
**上下文检查清单:**
- [ ] 阅读 \`specs/[capability]/spec.md\` 中的相关规范
- [ ] 在 \`changes/\` 中检查是否有冲突的待处理变更
- [ ] 阅读 \`openspec/project.md\` 了解约定
- [ ] 运行 \`openspec list\` 查看活动变更
- [ ] 运行 \`openspec list --specs\` 查看现有能力
**创建规范之前:**
- 始终检查能力是否已存在
- 优先修改现有规范而非创建副本
- 使用 \`openspec show [spec]\` 查看当前状态
- 如果请求模糊,在创建脚手架前询问1-2个澄清问题
### 搜索指导
- 枚举规范:\`openspec spec list --long\`(或 \`--json\` 用于脚本)
- 枚举变更:\`openspec list\`(或 \`openspec change list --json\` - 已弃用但可用)
- 显示详情:
- 规范:\`openspec show <spec-id> --type spec\`(使用 \`--json\` 进行过滤)
- 变更:\`openspec show <change-id> --json --deltas-only\`
- 全文搜索(使用 ripgrep):\`rg -n "Requirement:|Scenario:" openspec/specs\`
## 快速开始
### CLI 命令
\`\`\`bash
# 基本命令
openspec list # 列出活动变更
openspec list --specs # 列出规范
openspec show [item] # 显示变更或规范
openspec validate [item] # 验证变更或规范
openspec archive <change-id> [--yes|-y] # 部署后归档(添加 --yes 用于非交互式运行)
# 项目管理
openspec init [path] # 初始化 OpenSpec
openspec update [path] # 更新指令文件
# 交互模式
openspec show # 提示选择
openspec validate # 批量验证模式
# 调试
openspec show [change] --json --deltas-only
openspec validate [change] --strict
\`\`\`
### 命令标志
- \`--json\` - 机器可读输出
- \`--type change|spec\` - 区分项目
- \`--strict\` - 全面验证
- \`--no-interactive\` - 禁用提示
- \`--skip-specs\` - 归档时跳过规范更新
- \`--yes\`/\`-y\` - 跳过确认提示(非交互式归档)
## 目录结构
\`\`\`
openspec/
├── project.md # 项目约定
├── specs/ # 当前真相 - 实际构建的
│ └── [capability]/ # 单一专注能力
│ ├── spec.md # 需求和场景
│ └── design.md # 技术模式
├── changes/ # 提案 - 应该改变的
│ ├── [change-name]/
│ │ ├── proposal.md # 为什么、改变什么、影响
│ │ ├── tasks.md # 实施清单
│ │ ├── design.md # 技术决策(可选;见标准)
│ │ └── specs/ # 增量变更
│ │ └── [capability]/
│ │ └── spec.md # ADDED/MODIFIED/REMOVED
│ └── archive/ # 已完成的变更
\`\`\`
## 创建变更提案
### 决策树
\`\`\`
新请求?
├─ Bug修复恢复规范行为? → 直接修复
├─ 拼写/格式/注释? → 直接修复
├─ 新功能/能力? → 创建提案
├─ 破坏性变更? → 创建提案
├─ 架构变更? → 创建提案
└─ 不清楚? → 创建提案(更安全)
\`\`\`
### 提案结构
1. **创建目录:** \`changes/[change-id]/\`(kebab-case,动词开头,唯一)
2. **编写 proposal.md:**
\`\`\`markdown
# Change: [变更简要描述]
## Why
[1-2句话说明问题/机会]
## What Changes
- [变更列表]
- [用 **BREAKING** 标记破坏性变更]
## Impact
- 受影响的规范:[列出能力]
- 受影响的代码:[关键文件/系统]
\`\`\`
3. **创建规范增量:** \`specs/[capability]/spec.md\`
\`\`\`markdown
## ADDED Requirements
### Requirement: New Feature
The system SHALL provide...
#### Scenario: Success case
- **WHEN** user performs action
- **THEN** expected result
## MODIFIED Requirements
### Requirement: Existing Feature
[完整的修改后需求]
## REMOVED Requirements
### Requirement: Old Feature
**Reason**: [为什么移除]
**Migration**: [如何处理]
\`\`\`
如果影响多个能力,在 \`changes/[change-id]/specs/<capability>/spec.md\` 下为每个能力创建多个增量文件。
4. **创建 tasks.md:**
\`\`\`markdown
## 1. Implementation
- [ ] 1.1 创建数据库schema
- [ ] 1.2 实施API端点
- [ ] 1.3 添加前端组件
- [ ] 1.4 编写测试
\`\`\`
5. **需要时创建 design.md:**
如果以下任一情况适用则创建 \`design.md\`,否则省略:
- 跨切变更(多个服务/模块)或新的架构模式
- 新的外部依赖或重大的数据模型变更
- 安全、性能或迁移复杂性
- 需要编码前技术决策的模糊性
最小的 \`design.md\` 骨架:
\`\`\`markdown
## Context
[背景、约束、利益相关者]
## Goals / Non-Goals
- Goals: [...]
- Non-Goals: [...]
## Decisions
- Decision: [什么和为什么]
- Alternatives considered: [选项 + 理由]
## Risks / Trade-offs
- [风险] → 缓解措施
## Migration Plan
[步骤、回滚]
## Open Questions
- [...]
\`\`\`
## 规范文件格式
### 关键:场景格式
**正确**(使用 #### 标题):
\`\`\`markdown
#### Scenario: User login success
- **WHEN** valid credentials provided
- **THEN** return JWT token
\`\`\`
**错误**(不要使用项目符号或粗体):
\`\`\`markdown
- **Scenario: User login** ❌
**Scenario**: User login ❌
### Scenario: User login ❌
\`\`\`
每个需求必须至少有一个场景。
### 需求措辞
- 对规范性需求使用 SHALL/MUST(除非有意使用非规范性,否则避免 should/may)
### 增量操作
- \`## ADDED Requirements\` - 新能力
- \`## MODIFIED Requirements\` - 更改行为
- \`## REMOVED Requirements\` - 已弃用功能
- \`## RENAMED Requirements\` - 名称更改
标题与 \`trim(header)\` 匹配 - 忽略空白符。
#### 何时使用 ADDED vs MODIFIED
- ADDED: 引入可以作为独立需求存在的新能力或子能力。当变更正交时优先使用 ADDED(例如添加"斜杠命令配置")而非更改现有需求的语义。
- MODIFIED: 更改现有需求的行为、范围或验收标准。始终粘贴完整的更新后需求内容(标题+所有场景)。归档器会用您提供的内容替换整个需求;部分增量将丢弃先前细节。
- RENAMED: 仅名称更改时使用。如果同时更改行为,使用 RENAMED(名称)加上 MODIFIED(内容)引用新名称。
常见陷阱:使用 MODIFIED 添加新关注点而不包含先前文本。这会在归档时导致细节丢失。如果您没有明确更改现有需求,请在 ADDED 下添加新需求。
正确编写 MODIFIED 需求:
1) 在 \`openspec/specs/<capability>/spec.md\` 中定位现有需求。
2) 复制整个需求块(从 \`### Requirement: ...\` 到其场景)。
3) 将其粘贴到 \`## MODIFIED Requirements\` 下并编辑以反映新行为。
4) 确保标题文本完全匹配(忽略空白符)并至少保留一个 \`#### Scenario:\`。
RENAMED 示例:
\`\`\`markdown
## RENAMED Requirements
- FROM: \`### Requirement: Login\`
- TO: \`### Requirement: User Authentication\`
\`\`\`
## 故障排除
### 常见错误
**"Change must have at least one delta"**
- 检查 \`changes/[name]/specs/\` 是否存在 .md 文件
- 验证文件是否有操作前缀(## ADDED Requirements)
**"Requirement must have at least one scenario"**
- 检查场景使用 \`#### Scenario:\` 格式(4个井号)
- 不要对场景标题使用项目符号或粗体
**静默场景解析失败**
- 精确格式要求:\`#### Scenario: Name\`
- 调试:\`openspec show [change] --json --deltas-only\`
### 验证提示
\`\`\`bash
# 始终使用严格模式进行全面检查
openspec validate [change] --strict
# 调试增量解析
openspec show [change] --json | jq '.deltas'
# 检查特定需求
openspec show [spec] --json -r 1
\`\`\`
## 顺利路径脚本
\`\`\`bash
# 1) 探索当前状态
openspec spec list --long
openspec list
# 可选全文搜索:
# rg -n "Requirement:|Scenario:" openspec/specs
# rg -n "^#|Requirement:" openspec/changes
# 2) 选择变更ID并创建脚手架
CHANGE=add-two-factor-auth
mkdir -p openspec/changes/$CHANGE/{specs/auth}
printf"## Why\\n...\\n\\n## What Changes\\n- ...\\n\\n## Impact\\n- ...\\n" > openspec/changes/$CHANGE/proposal.md
printf"## 1. Implementation\\n- [ ] 1.1 ...\\n" > openspec/changes/$CHANGE/tasks.md
# 3) 添加增量(示例)
cat > openspec/changes/$CHANGE/specs/auth/spec.md << 'EOF'
## ADDED Requirements
### Requirement: Two-Factor Authentication
Users MUST provide a second factor during login.
#### Scenario: OTP required
- **WHEN** valid credentials are provided
- **THEN** an OTP challenge is required
EOF
# 4) 验证
openspec validate $CHANGE --strict
\`\`\`
## 多能力示例
\`\`\`
openspec/changes/add-2fa-notify/
├── proposal.md
├── tasks.md
└── specs/
├── auth/
│ └── spec.md # ADDED: Two-Factor Authentication
└── notifications/
└── spec.md # ADDED: OTP email notification
\`\`\`
auth/spec.md
\`\`\`markdown
## ADDED Requirements
### Requirement: Two-Factor Authentication
...
\`\`\`
notifications/spec.md
\`\`\`markdown
## ADDED Requirements
### Requirement: OTP Email Notification
...
\`\`\`
## 最佳实践
### 简单优先
- 默认 <100 行新增代码
- 单文件实施直到证明不足
- 避免没有明确理由的框架
- 选择简单、经过验证的模式
### 复杂性触发器
只在以下情况下增加复杂性:
- 性能数据表明当前解决方案太慢
- 具体的规模要求(>1000用户,>100MB数据)
- 需要抽象的多个已验证用例
### 清晰引用
- 使用 \`file.ts:42\` 格式表示代码位置
- 引用规范为 \`specs/auth/spec.md\`
- 链接相关的变更和PR
### 能力命名
- 使用动词-名词:\`user-auth\`,\`payment-capture\`
- 每个能力单一用途
- 10分钟理解规则
- 如果描述需要"AND"则拆分
### 变更ID命名
- 使用 kebab-case,简短且描述性:\`add-two-factor-auth\`
- 优先使用动词开头前缀:\`add-\`,\`update-\`,\`remove-\`,\`refactor-\`
- 确保唯一性;如果已被使用,追加 \`-2\`,\`-3\` 等
## 工具选择指南
| 任务 | 工具 | 原因 |
|------|------|-----|
| 按模式查找文件 | Glob | 快速模式匹配 |
| 搜索代码内容 | Grep | 优化的正则搜索 |
| 读取特定文件 | Read | 直接文件访问 |
| 探索未知范围 | Task | 多步调查 |
## 错误恢复
### 变更冲突
1. 运行 \`openspec list\` 查看活动变更
2. 检查规范重叠
3. 与变更所有者协调
4. 考虑合并提案
### 验证失败
1. 使用 \`--strict\` 标志运行
2. 检查JSON输出详情
3. 验证规范文件格式
4. 确保场景格式正确
### 缺失上下文
1. 首先阅读 project.md
2. 检查相关规范
3. 查看近期归档
4. 要求澄清
## 快速参考
### 阶段指示器
- \`changes/\` - 已提议,尚未构建
- \`specs/\` - 已构建和部署
- \`archive/\` - 已完成的变更
### 文件用途
- \`proposal.md\` - 为什么和什么
- \`tasks.md\` - 实施步骤
- \`design.md\` - 技术决策
- \`spec.md\` - 需求和行为
### CLI 基础
\`\`\`bash
openspec list # 进行中的工作?
openspec show [item] # 查看详情
openspec validate --strict # 是否正确?
openspec archive <change-id> [--yes|-y] # 标记完成(添加 --yes 用于自动化)
\`\`\`
记住:规范是真相。变更是提案。保持同步。
文件openspec/projects.md中的提示词
原始英文提示词,参见
中文翻译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31## Purpose
${context.description || '[Describe your project\'s purpose and goals]'}
## Tech Stack
${context.techStack?.length
? context.techStack.map(tech => `- ${tech}`).join('\n')
: '- [List your primary technologies]\n- [e.g., TypeScript, React, Node.js]'}
## Project Conventions
### Code Style
[Describe your code style preferences,
formatting rules, and naming conventions]
### Architecture Patterns
[Document your architectural decisions and patterns]
### Testing Strategy
[Explain your testing approach and requirements]
### Git Workflow
[Describe your branching strategy and commit conventions]
## Domain Context
[Add domain-specific knowledge that AI assistants need to understand]
## Important Constraints
[List any technical, business, or regulatory constraints]
## External Dependencies
[Document key external services, APIs, or systems]新增命令openspec:proposal的提示词由以下几个部分组合
原始英文提示词,参见
中文翻译
baseGuardrails
1
2
3
4
5
6
7
8
9
10
11
12**护栏**
- 优先采用直接、简洁的实现方式,
仅在被要求或明显需要时才增加复杂性。
- 将变更范围严格限制在所请求的结果内。
- 如需额外的 OpenSpec 规范或说明,
请参考 \`openspec/AGENTS.md\`
(位于 \`openspec/\` 目录下——
如果未看到该文件,请运行
\`ls openspec\` 或 \`openspec update\` 命令)。proposalGuardrails
1
识别任何模糊或不明确的细节,并在编辑文件前提出必要的后续问题。
proposalSteps
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34**步骤**
1. 审查 \`openspec/project.md\`,
运行 \`openspec list\` 和 \`openspec list --specs\`,
并检查相关代码或文档(例如通过 \`rg\`/\`ls\`)
以确保提案基于当前行为;
注意任何需要澄清的差距。
2. 选择一个独特的以动词开头的 \`change-id\`,
并在 \`openspec/changes/<id>/\` 下搭建
\`proposal.md\`、\`tasks.md\` 和 \`design.md\`(如需要)的框架。
3. 将变更映射为具体的容量或需求,
将多范围的工作分解为具有明确关系和顺序的
不同规范增量。
4. 当解决方案跨越多个系统、引入新模式
或在提交规范前需要讨论权衡时,
在 \`design.md\` 中记录架构推理。
5. 在 \`changes/<id>/specs/<capability>/spec.md\` 中起草规范增量
(每个容量一个文件夹),
使用 \`## ADDED|MODIFIED|REMOVED Requirements\` 格式,
每项需求至少包含一个 \`#### Scenario:\`,
并在适当时交叉引用相关容量。
6. 将 \`tasks.md\` 起草为有序列表,
列出小的、可验证的工作项目,
这些项目能提供用户可见的进展,
包括验证(测试、工具),
并突出显示依赖关系或可并行的工作。
7. 使用 \`openspec validate <id> --strict\` 进行验证,
并在分享提案前解决每个问题。proposalReferences
1
2
3
4
5
6
7
8
9
10
11
12
13
14**参考**
- 验证失败时,使用
\`openspec show <id> --json --deltas-only\`
或 \`openspec show <spec> --type spec\`
来检查详细信息。
- 编写新需求前,先用
\`rg -n "Requirement:|Scenario:" openspec/specs\`
搜索已有的需求。
- 使用 \`rg <keyword>\`、\`ls\`
或直接读取文件来浏览代码库,
确保提案与当前实现保持一致。
新增命令openspec:apply的提示词由以下几个部分组合
- 原始英文提示词,参见
- 中文翻译
- baseGuardrails
1
2
3
4
5
6
7
8
9
10
11
12**护栏**
- 优先采用直接、简洁的实现方式,
仅在被要求或明显需要时才增加复杂性。
- 将变更范围严格限制在所请求的结果内。
- 如需额外的 OpenSpec 规范或说明,
请参考 \`openspec/AGENTS.md\`
(位于 \`openspec/\` 目录下——
如果未看到该文件,请运行
\`ls openspec\` 或 \`openspec update\` 命令)。 - applySteps
- 没有提示在每个步骤创建Git提交,差评。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19**步骤**
将这些步骤标记为待办事项(TODOs),然后逐个完成。
1. 阅读 \`changes/<id>/proposal.md\`、
\`design.md\`(如果存在)和 \`tasks.md\`,
以确认范围和验收标准。
2. 按顺序执行任务,
保持修改最小化且专注于所请求的变更。
3. 在更新状态前确认已完成——
确保 \`tasks.md\` 中的每项内容都已完成。
4. 所有工作完成后更新清单,
使每项任务都标记为 \`- [x]\` 并反映实际情况。
5. 当需要额外上下文时,
参考 \`openspec list\` 或 \`openspec show <item>\`。
- 没有提示在每个步骤创建Git提交,差评。
- applyReferences
1
2
3
4**参考**
- 如果在实现过程中需要提案的更多上下文信息,
请使用 \`openspec show <id> --json --deltas-only\`。
新增命令openspec:archive的提示词由以下几个部分组合
- 原始英文提示词,参见
- 中文翻译
- baseGuardrails
1
2
3
4
5
6
7
8
9
10
11
12**护栏**
- 优先采用直接、简洁的实现方式,
仅在被要求或明显需要时才增加复杂性。
- 将变更范围严格限制在所请求的结果内。
- 如需额外的 OpenSpec 规范或说明,
请参考 \`openspec/AGENTS.md\`
(位于 \`openspec/\` 目录下——
如果未看到该文件,请运行
\`ls openspec\` 或 \`openspec update\` 命令)。 - archiveSteps
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33**步骤**
1. 确定要归档的变更 ID:
- 如果此提示中已包含特定的变更 ID
(例如在由斜杠命令参数填充的 \`<ChangeId>\` 块内),
请在去除空白字符后使用该值。
- 如果对话中松散地引用了变更
(例如通过标题或摘要),
请运行 \`openspec list\` 以显示可能的 ID,
分享相关候选结果,并确认用户想要归档的是哪一个。
- 否则,请回顾对话内容,运行 \`openspec list\`,
并询问用户要归档哪个变更;
在继续操作前等待确认的变更 ID。
- 如果仍无法确定单一的变更 ID,
请停止并告知用户目前无法进行归档。
2. 通过运行 \`openspec list\`
(或 \`openspec show <id>\`)验证变更 ID,
如果变更不存在、已归档或尚未准备好归档,
则停止操作。
3. 运行 \`openspec archive <id> --yes\`,
让 CLI 在无提示的情况下移动变更
并应用规范更新
(仅对纯工具性工作使用 \`--skip-specs\` 参数)。
4. 检查命令输出,
以确认目标规范已更新
且变更已移至 \`changes/archive/\`。
5. 使用 \`openspec validate --strict\` 进行验证,
如果发现任何异常,
请使用 \`openspec show <id>\` 进行检查。 - archiveReferences
1
2
3
4
5
6**参考**
- 使用 \`openspec list\` 命令在归档前确认变更 ID。
- 使用 \`openspec list --specs\` 检查刷新后的规范,
并在交付前解决任何验证问题。
AI coding 时代,规约、提示词可能超越代码本身成为项目的核心资产,保存在仓库,胜过流失在和AI的对话中,但是放在仓库中是最佳选择么?
参考链接
- https://github.com/QwenLM/qwen-code/tree/main/packages/core/src/core/openaiContentGenerator
- https://github.com/google-gemini/gemini-cli/blob/main/docs/cli/commands.md
- https://www.npmjs.com/package/mcp-server-commands
- https://geminicli.com/extensions/
- https://docs.claude.com/en/docs/agent-sdk/overview
- https://github.com/google-gemini/gemini-cli/blob/main/packages/core/src/core/prompts.ts
- https://github.com/google-gemini/gemini-cli/blob/main/packages/cli/src/ui/commands/initCommand.ts
- https://geminicli.com/extensions/
- https://code.claude.com/docs/en/slash-commands
- https://code.claude.com/docs/en/mcp
- https://www.anthropic.com/engineering/code-execution-with-mcp
- https://code.claude.com/docs/en/hooks-guide
- https://github.com/decider/claude-hooks
- https://docs.claude.com/en/docs/agents-and-tools/agent-skills/overview
- https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
- https://github.com/anthropics/skills
- https://code.claude.com/docs/en/sub-agents
- https://code.claude.com/docs/en/plugins
- https://docs.claude.com/en/docs/agent-sdk/overview
- https://github.com/punkpeye/awesome-mcp-servers
- https://github.com/Fission-AI/OpenSpec/
- https://github.com/Fission-AI/OpenSpec/blob/main/src/core/templates/agents-root-stub.ts
- https://github.com/Fission-AI/OpenSpec/blob/main/src/core/templates/slash-command-templates.ts