智能体时代的强化学习:AReaL框架与Agent最佳实践
以 RL 打造 Agent
两个核心”暴论”
- Agent是未来五年AGI时代最重要的事。
- 强化学习是构建Agent最关键的技术。

强化学习的历史发展与突破
强化学习的早期认知
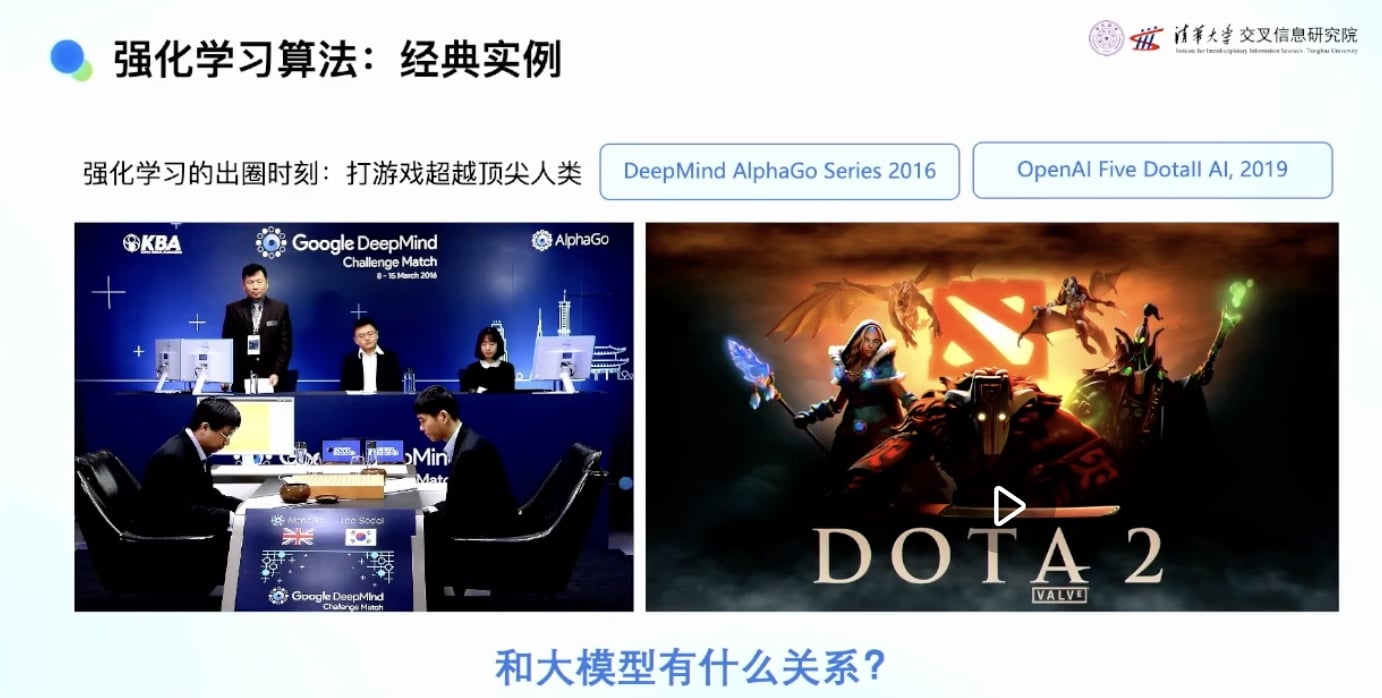
大多数人对强化学习的认知来源于:
- AlphaGo:DeepMind用强化学习训练围棋智能体,击败李世石和柯洁
- OpenAI打Dota:2019年用强化学习击败两届世界冠军OG
- 其他游戏AI:腾讯打王者荣耀、星际争霸等
当年的强化学习智能体主要都是打游戏的,与大模型驱动的AGI时代似乎没有太大关系。
强化学习与大模型的结合转折点
2020-2022年的关键变化
GPT-3 API的问题:
- 2020年OpenAI推出GPT-3 API时存在严重问题
- 例子:输入”explain the moon landing to a six year old in a few sentences”
- GPT-3会输出重复内容:”explain the serious gravity, explain the serious relative, explain blah blah blah”
- 原因:大模型训练基于next token prediction,但用户给的是指令(instruction following problem)
注: “Next Token Prediction”(下一个 token 预测)是大语言模型(LLM)的核心机制。简单来说,它的意思是:给定一段文本的前面部分,模型预测接下来最可能出现的“token”是什么。
RLHF技术的突破:
- OpenAI花了两年时间解决这个问题
- 2022年推出InstructGPT,采用RLHF(Reinforcement Learning from Human Feedback)技术
- 方法:找人标注数据,判断哪些回答遵从指令,哪些不遵从
- 训练奖励模型,然后用强化学习让模型探索获得最高分数的回答
- 结果:同样的基座模型,有没有强化学习决定了好用还是不好用
注: RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是一种用于对齐大语言模型(LLM)的技术。它的核心目标是:让模型的输出更符合人类的偏好、价值观和意图,而不仅仅是“语法正确”或“统计上常见”。
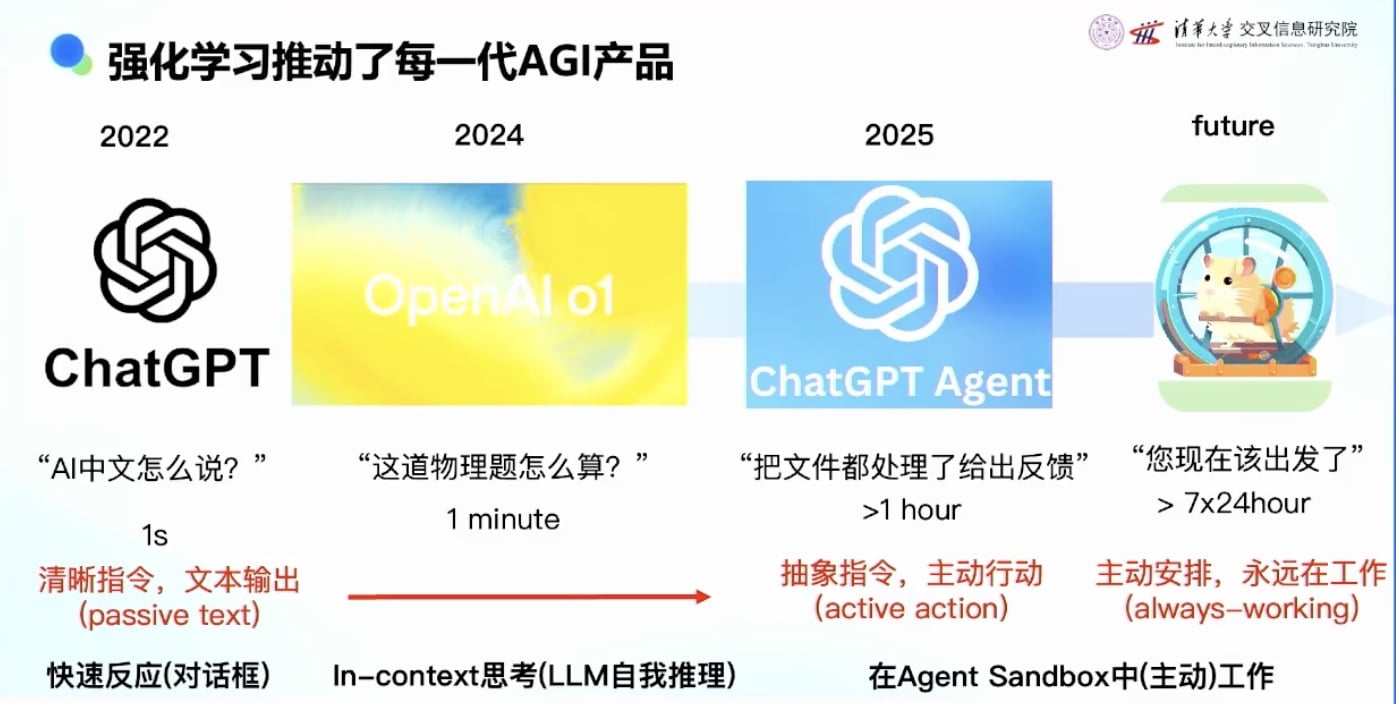
强化学习推动AGI产品发展的三个阶段
第一阶段:2022年ChatGPT
- 由RLHF技术引爆,让大家第一次感受到AGI能力
- 强化学习捅破了窗户纸,让AGI能力真正可用
第二阶段:2024年推理模型(Reasoning Model)

- 也称为思考模型(Thinking Model)
- 特点:给模型一个问题后,它会先想一会,输出大量thinking token
- 例子:帮我算个24点,思考模型(比如 deepseek)会先在”草稿纸”上写10分钟(输出thinking token),然后给答案
- 技术:也是强化学习驱动,模型自己探索如何思考, 思考什么,自己判断答案对不对, 也就产生了推理模型
- 训练范式与RLHF类似,但判断标准可能不同
第三阶段:2025年Agent模型
- 基于Agent的强化学习技术
- 代表产品:ChatGPT Deep Research 等
Agent产品的发展与特点
成功的Agent产品案例
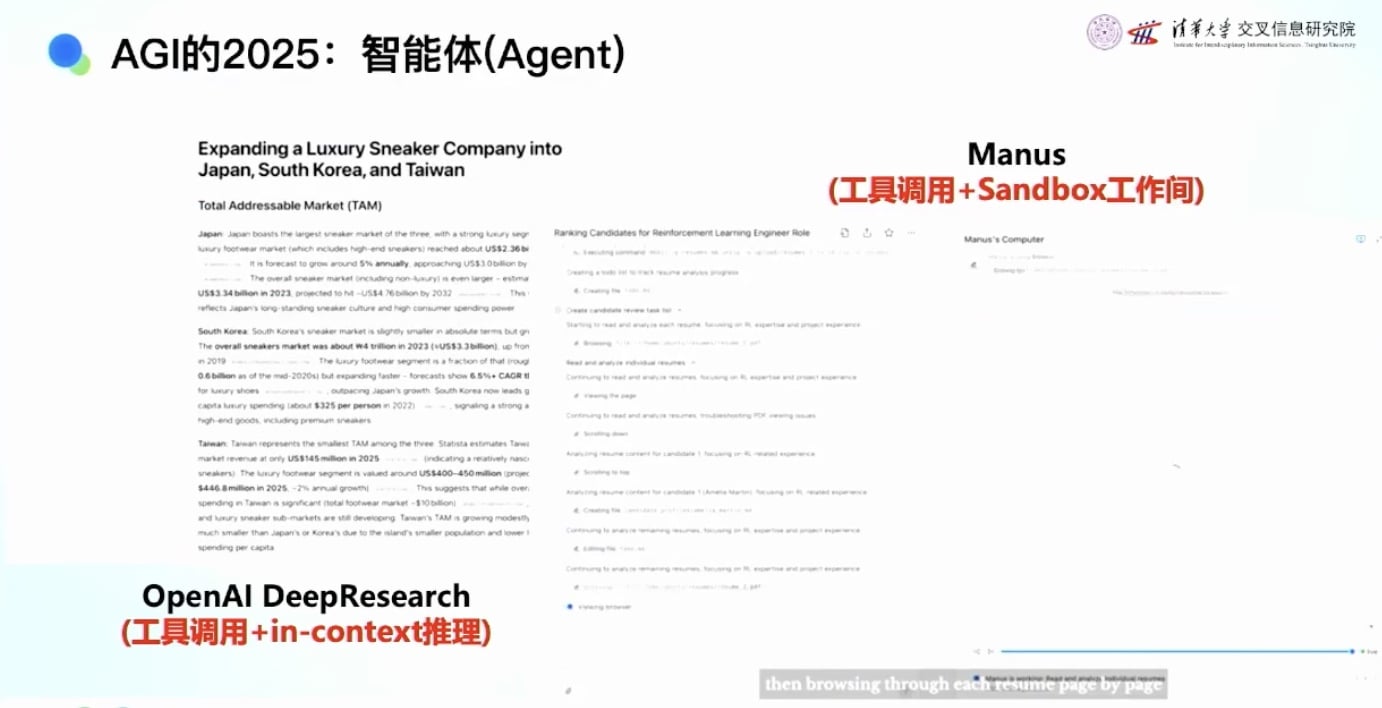
- ChatGPT Deep Research
- 2024年第一个比较成功的Agent产品
- 功能:给它一个topic,帮你做研究
- 工作流程:
- 花很多时间思考
- 调用工具,在网上搜索很多topic
- 可能运行20分钟到1小时
- 最终给出非常详实、有大量引用和reference的报告
- Manus /ChatGPT Agent / Kimi Agent Mode
- 功能更丰富,可以帮你做PPT
- 在Sandbox(沙盒)环境中工作:
- 读取PDF文件
- 在阅读器中打开PDF
- 存储PDF文件
- 编辑和创建文件
- 在虚拟机中进行各种操作
Agent能力的演进

从Deep Research到Manus的发展体现了Agent能力的进步:
- Deep Research:除了对话,可以调用搜索工具、浏览器工具,将信息放在Context Window中处理
- Manus:更进一步,加上了Sandbox工程AI,相当于有了自己的电脑
AI的能力演进:
- 有了脑子(大模型)
- 有了草稿纸和笔(Context Window)
- 有了一台自己的电脑(Sandbox)
产品发展趋势分析
- 用户交互的变化
- ChatGPT时代:需要很长的prompt,详细描述要做什么
- Agent时代:用户说的话越来越抽象,越来越少
- AI能力的变化
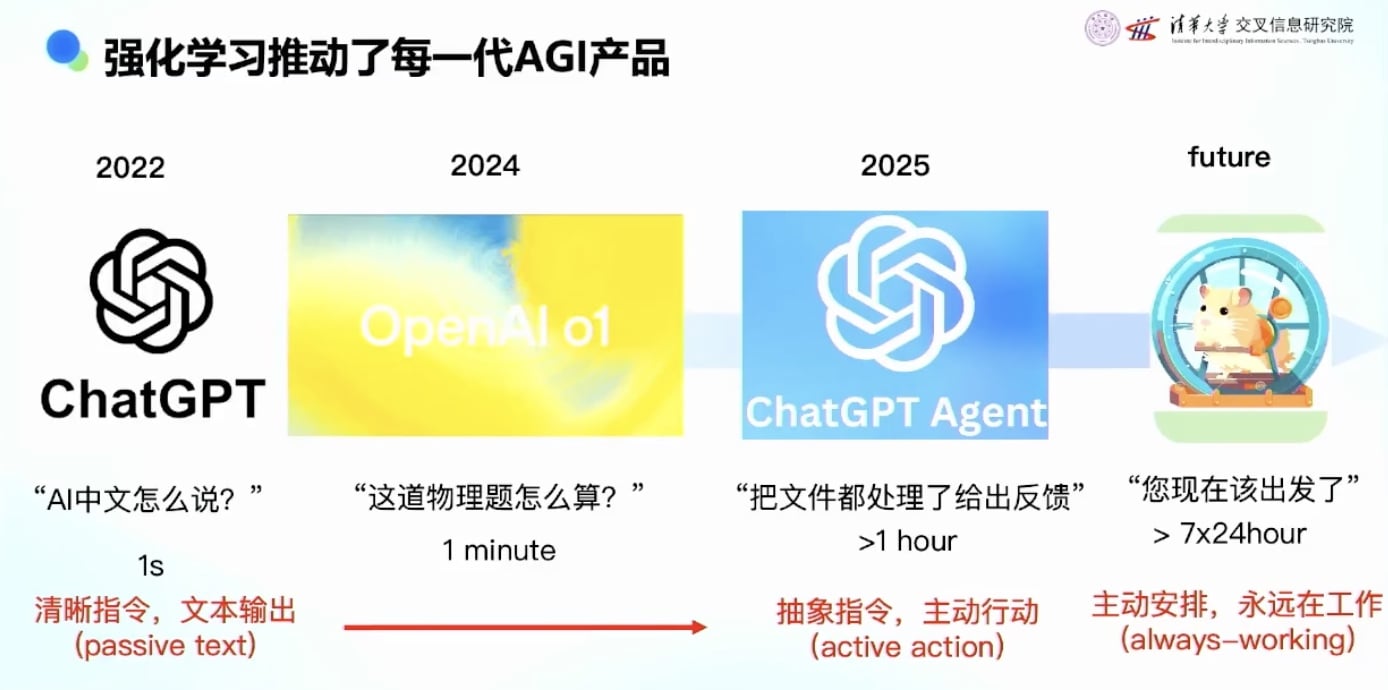
- ChatGPT:1秒钟给出文本输出
- Thinking Model:1-2分钟思考后给出答案
- Agent Model:1小时处理复杂任务,主动行动
- 未来: 牛马 AI, AI一直在做事, 主动帮人安排
- 从Reactive到Proactive的转变

- 传统模式:用户告诉AI做什么(Reactive)
- 未来趋势:AI主动准备,告诉用户要不要(Proactive)
- 例子:OpenAI的ChatGPT Plus每天主动推送早报等内容
未来愿景
理想的AI助手具体技术化来讲:
- 信息模糊处理:人很难把想做的事讲清楚
- 个性化:每个人的需求不一样
- 主动规划:主动安排和执行任务
- 提前工作:AI不需要休息,可以一直工作
什么是好的 Agent 团队

- 组织 AI 化
- 技术栈完整
- 持续高速0-1 创新, 高效迭代
为什么Agent需要RL(强化学习)
市面上Agent 有各种 framework, 这些框架主要通过拖拉拽的方式构建Agent工作流,但对于复杂的Agent问题存在局限性。
强化学习解决的三大核心问题

问题一:处理不确定性和冲突信息
案例:阿里CTO是谁?
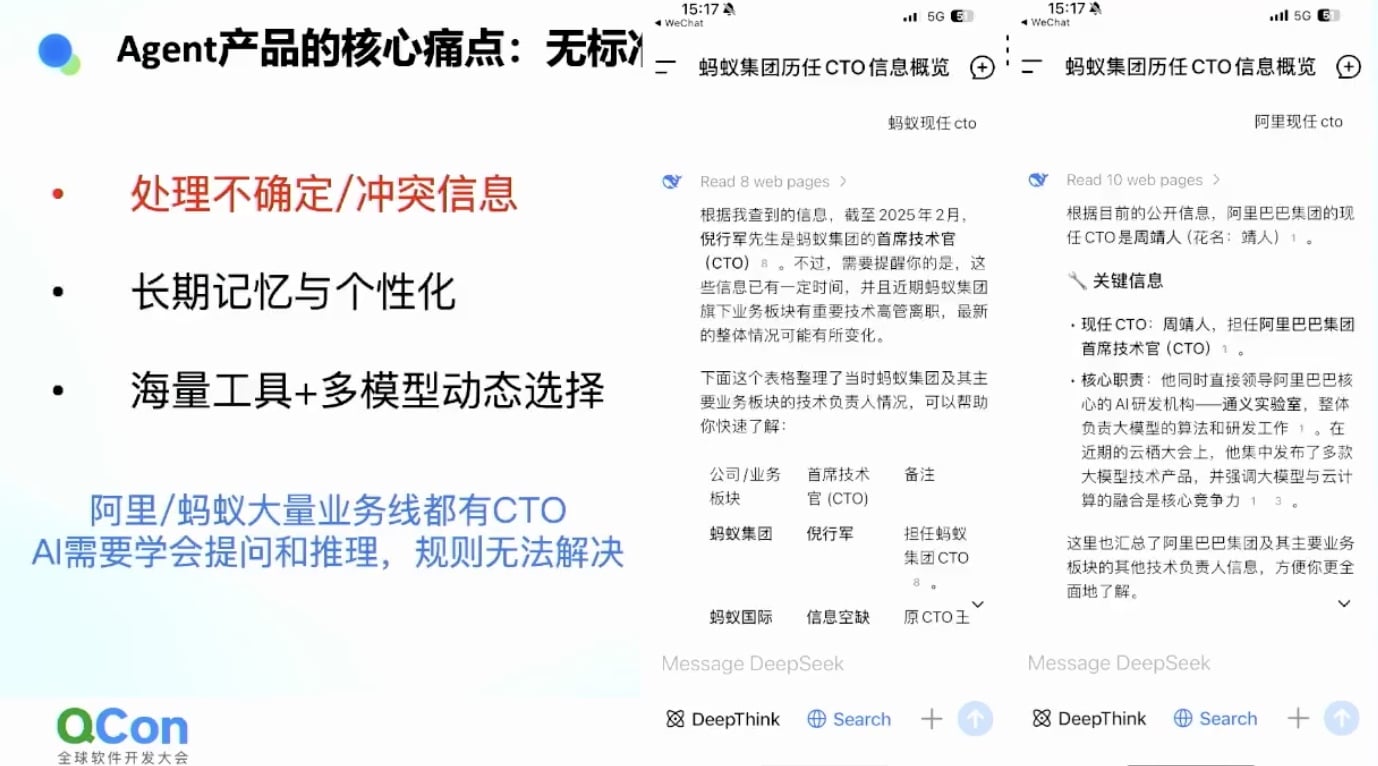
- 阿里和蚂蚁有很多子公司,每个公司都有CTO
- 搜索”蚂蚁CTO”会得到很多不同的结果
- 需要AI去理解和判断才能做出正确回答
案例:退票问题
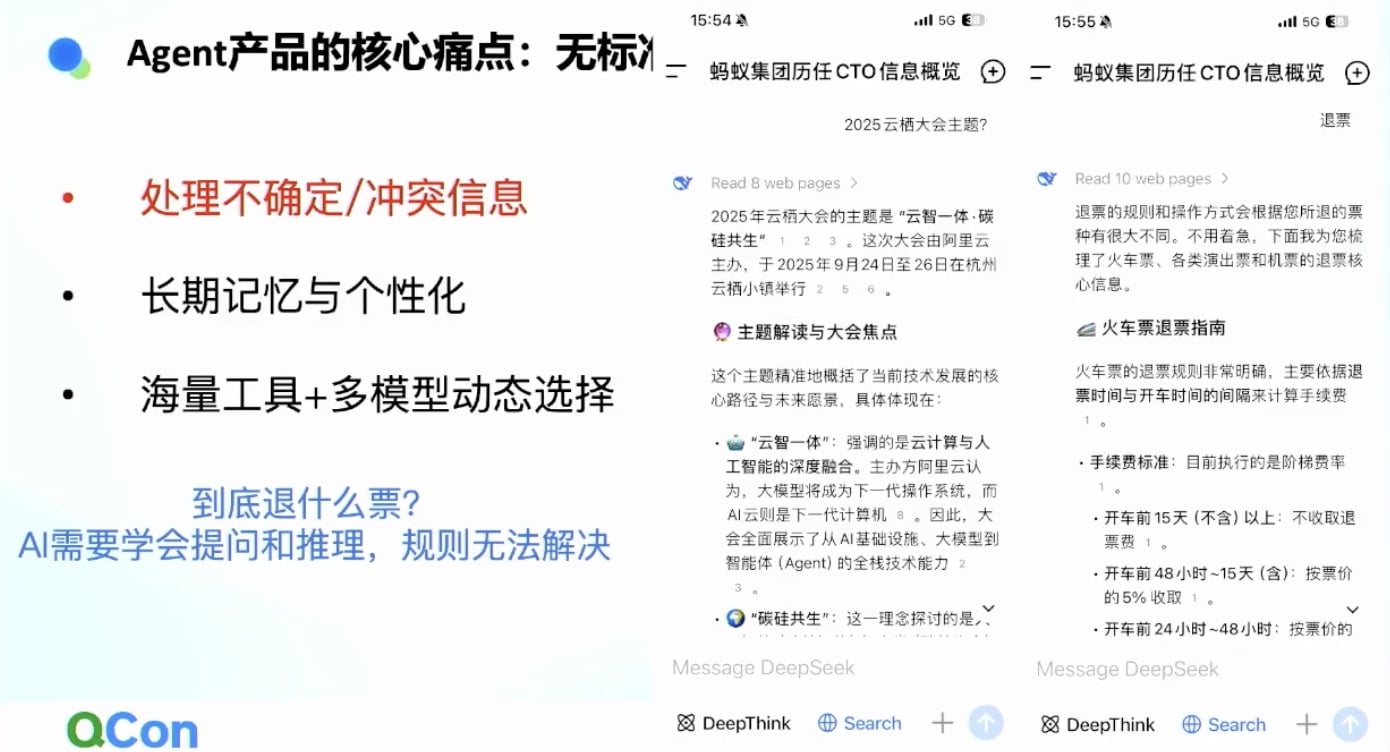
- 用户说”退票”,但上下文可能很不确定
- 退什么票?需要AI主动提问澄清
问题二:长期记忆和个性化
- 案例:美团小美推荐

- 我说”要吃晚饭,要清淡点”
- AI推荐白灼生菜等蔬菜
- 但我从来不点蔬菜,喜欢吃肉
- “清淡点”对我可能意味着”清淡点的肉”
- 需要从很长的记录中挖掘个性化信息
问题三:海量工具和模型选择
- 案例:Reddit上的模型组合使用
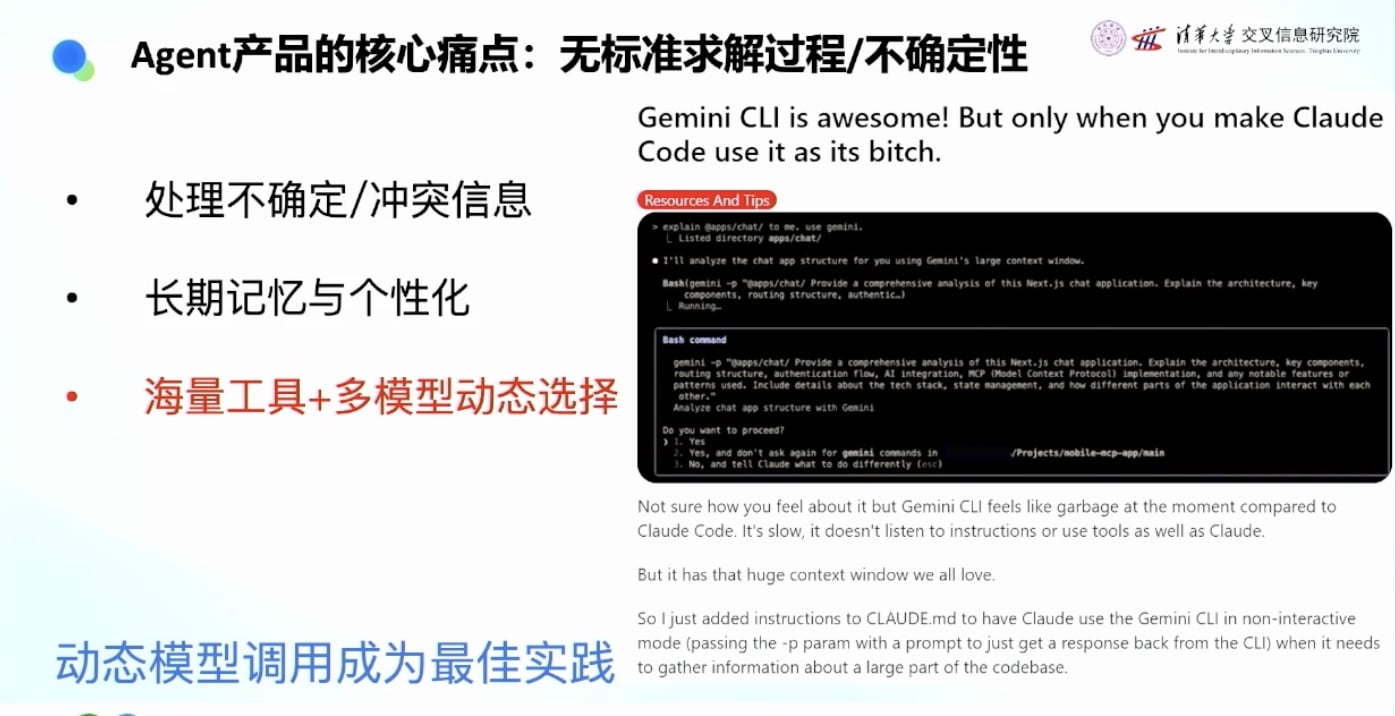
- Claude写代码很聪明但Context Window短且贵
- Gemini写代码不够聪明但Context Window长且便宜
- 用户发现可以用Claude调用Gemini:让Gemini读代码,然后扔给Claude写
- 相当于”聪明的人指挥体力无限的傻子干活”
- 这种最佳实践应该由AI自己探索出来,而不是人工定义规则
强化学习的统一解决方案
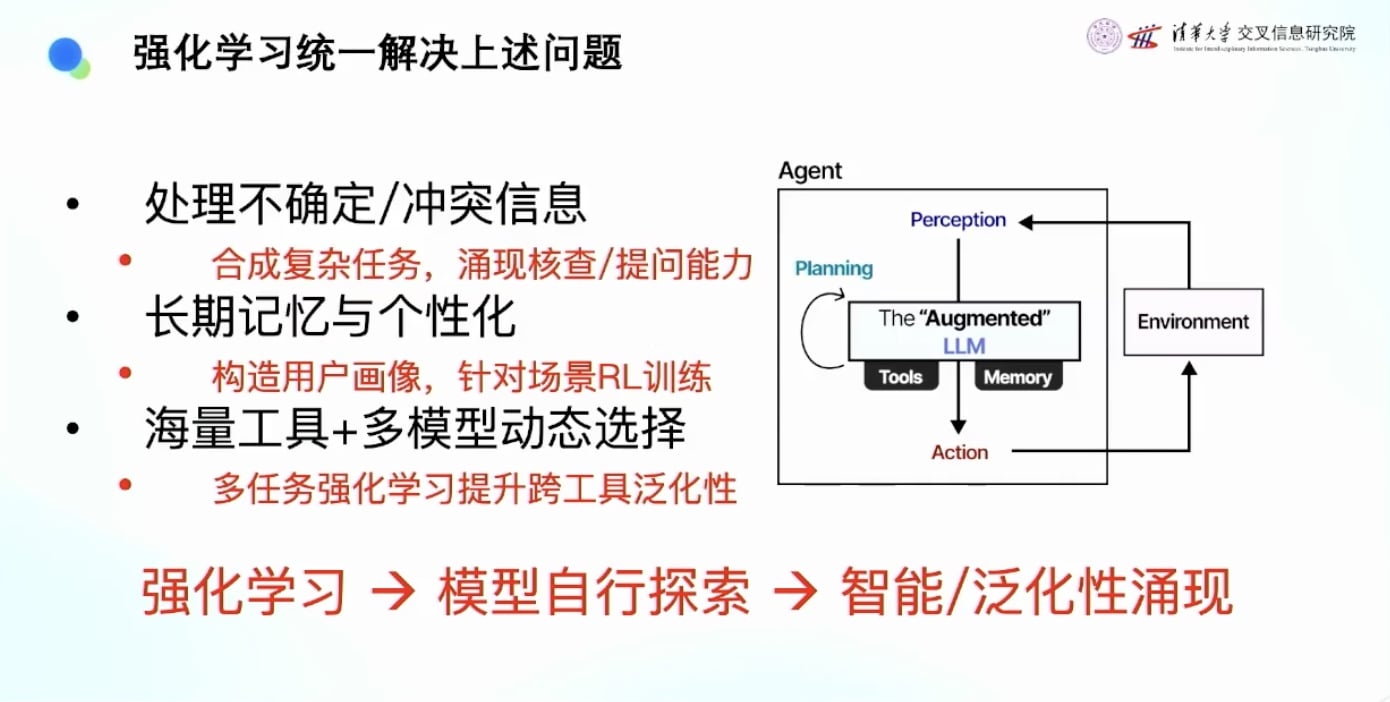
强化学习可以用统一的框架解决这些复杂问题:
- 让AI在环境中自己探索
- 涌现出处理复杂任务的能力
- 比规则和Workflow更灵活和强大
搜索智能体案例深度分析-看似简单的问题实际很复杂
问题案例:伦敦奥运会中国金牌数
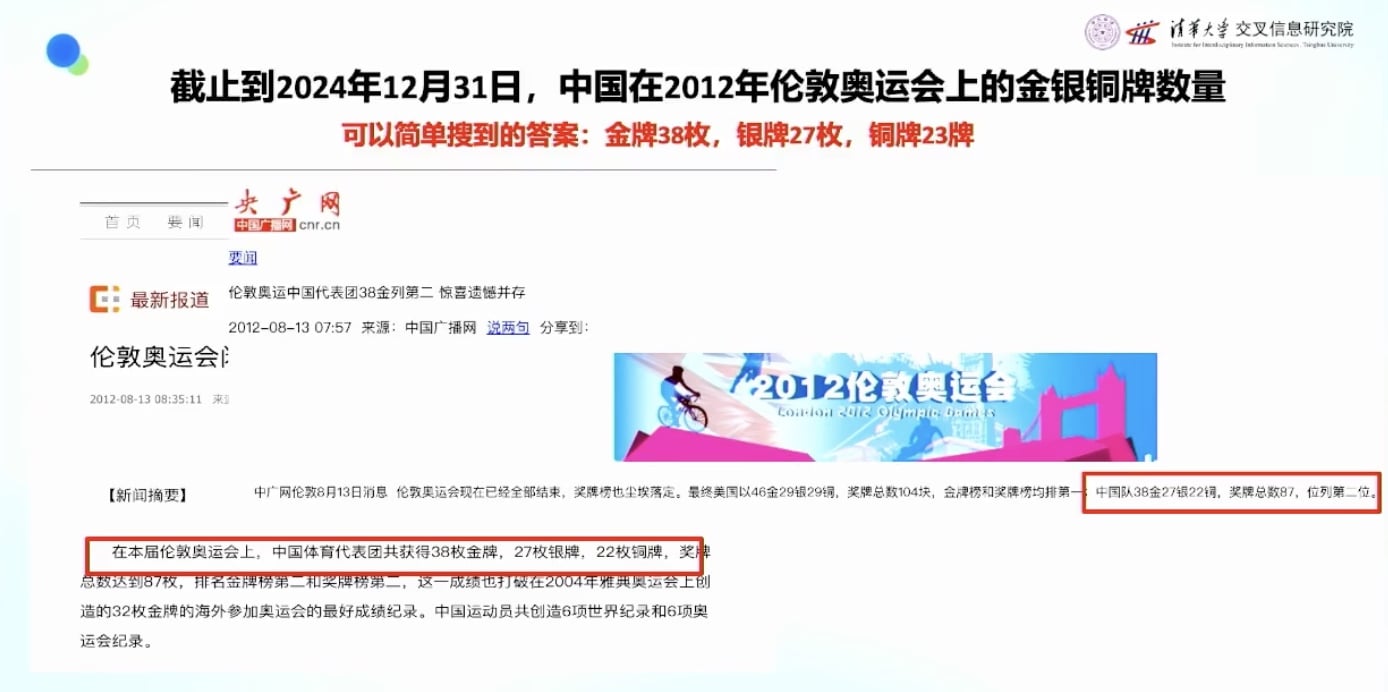
表面上的简单:
- 问题:伦敦奥运会中国拿多少块金银铜牌?
- 看起来很简单,百度搜索就能找到答案
- 官网显示:中国队拿了38块金牌,是2012年历史第二高的成绩
实际的复杂性:
- 正确答案应该是39枚金牌
- 原因:2012年伦敦奥运会女子田径竞走项目
- 中国派出三位选手,当时拿了第3、4、5名
- 后来第1、2名被查出禁药,被剥夺奖牌资格
- 11年后(2023年),中国选手获得了补发的金牌
- 所以现在问中国奥运会金牌数,答案应该是39枚
现有产品的表现
测试了多个产品:
- DeeSeek:搜出38枚金牌
- ChatGLM:38枚金牌
- ChatGPT:搜到了39枚金牌的信息,说”有一些资料显示数字略有差异,39枚金牌”,但最后结论还是38枚金牌(因为大量信息都是38枚)
- ChatGPT Agent Mode:会答对
传统方法vs强化学习方法
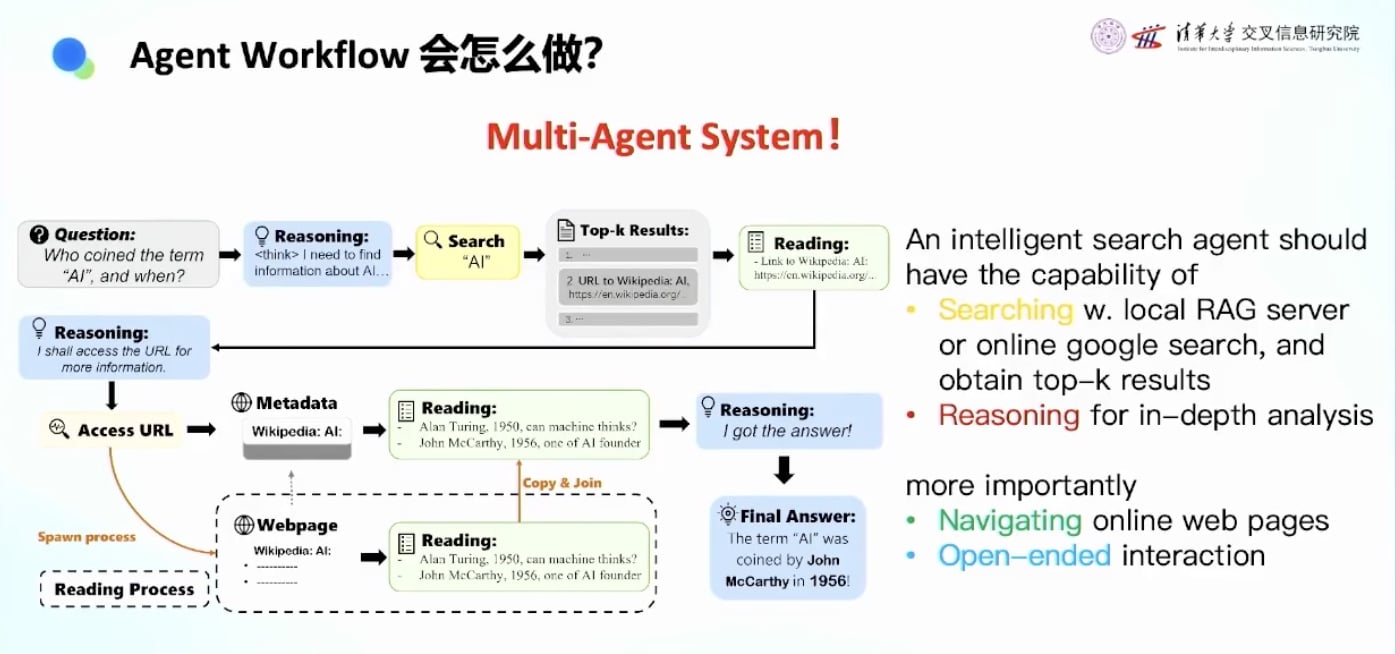
传统Multi-Agent System方法
需要构建复杂的多智能体系统:
- 搜索Agent
- 核查Agent
- 调用知识的Agent
- 检验Agent
- 需要很长很复杂的流程
强化学习方法
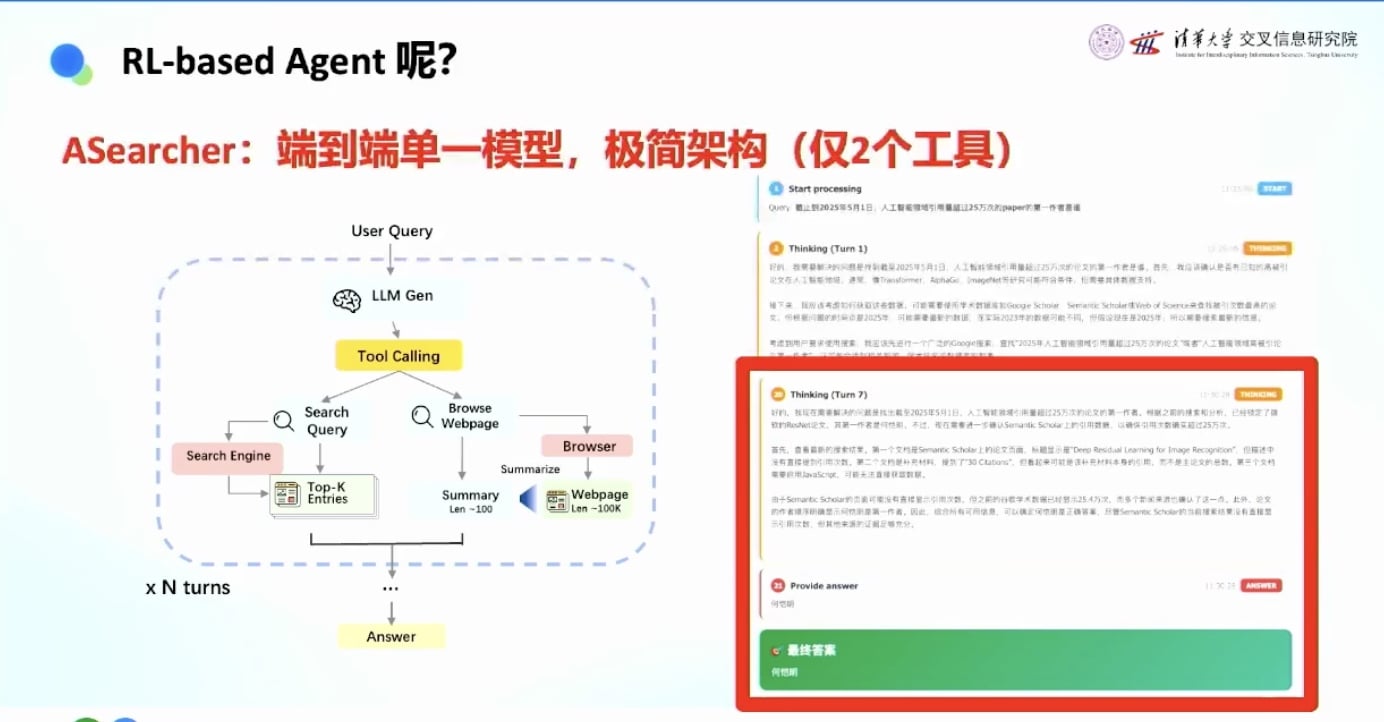
极简设计:
- 一个模型
- 两个工具:搜索工具 + 点击网页工具
- 让模型在环境中循环探索
实际效果: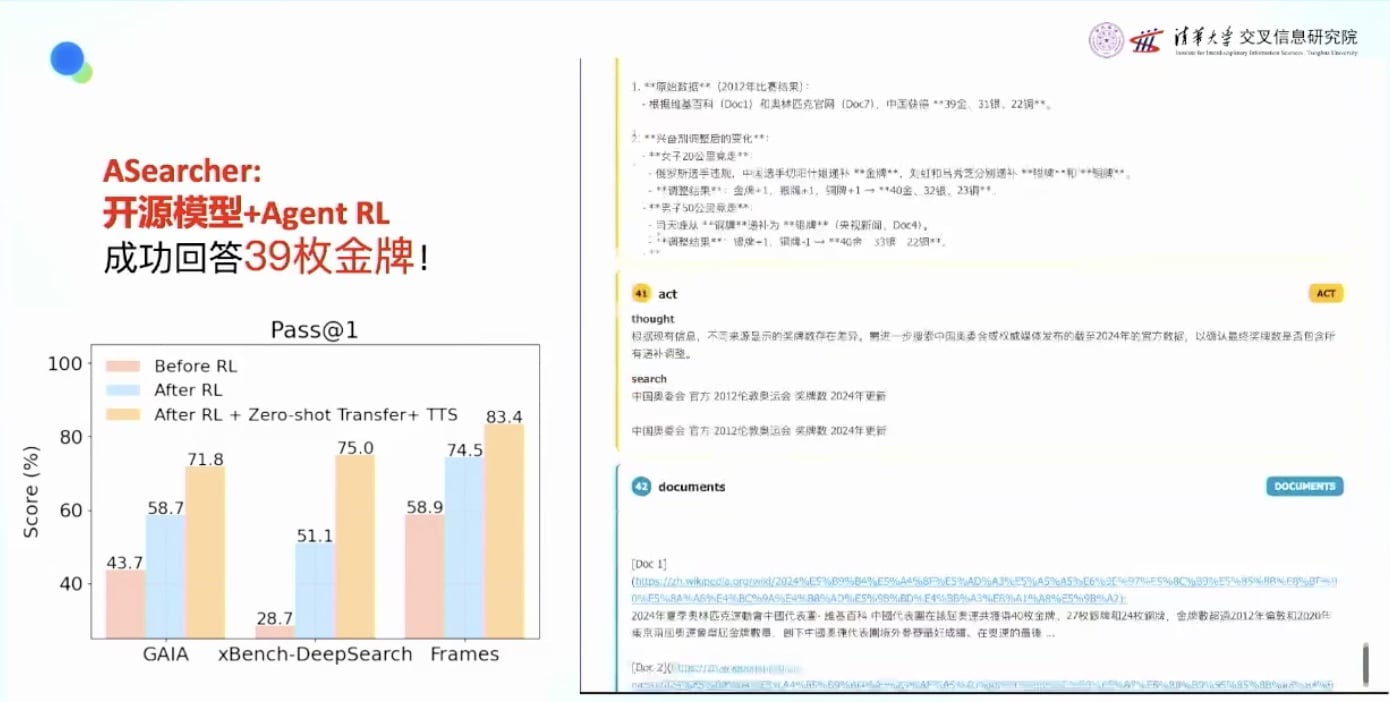
- 第5轮搜到39枚金牌的新闻
- 开始疯狂核查
- 经过60多轮迭代
- 最终确定正确答案是39枚金牌
- 还具有泛化能力,可以添加更强的工具
- 32B模型可以在准确度上超越商用产品
强化学习的两大优势

- 简单: 简化Agent的workflow, 不需要复杂的多智能体系统设计
- 涌现: 让AI涌现出复杂的多步推理能力, 通过探索自动获得复杂能力
Agent RL 的核心难点
强化学习面临的三大挑战

要做好强化学习,必须解决三个问题:
- 缺Infra和算法:强化学习算法运算速度很慢很慢
- 缺数据:训练数据的获取和质量, 强化学习的数据是很缺很缺德, 预训练数据可以在网上扒, 但强化学习的数据不太能直接网上扒
- 缺环境:Sandbox等执行环境的构建
如何全栈解决 Agent RL 的难点
Infra(基础设施)和算法优化
速度慢的根本原因
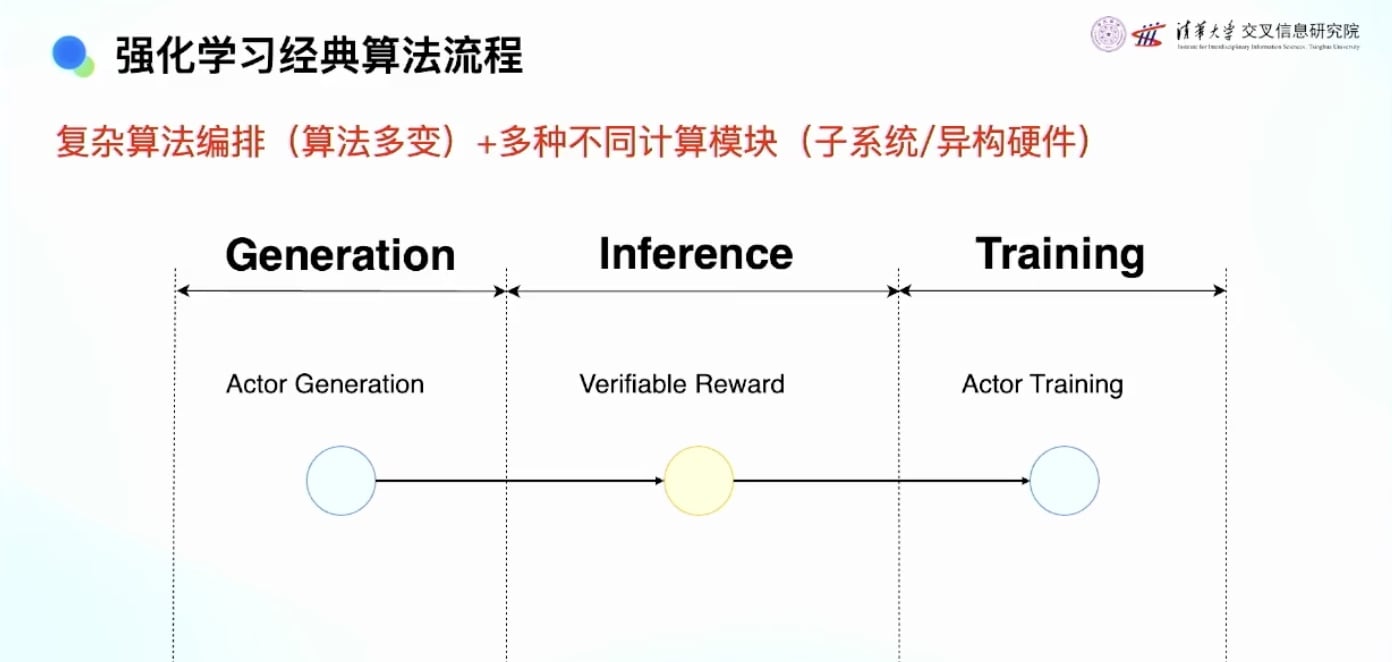
强化学习的三个流程:
- 生成:让模型在环境中交互生成数据
- 评分:用奖励模型计算奖励
- 训练:放到训练集中训练
复杂性分析:
- 涵盖了三种完全不同的计算模块
- 预训练只有训练,SFT只有训练,评测只有评测
- 强化学习包含:训练、评测、在线生成、Sandbox等
- 是一个算法编排了多种完全不同计算模式的复杂系统
算法与系统协同设计的重要性
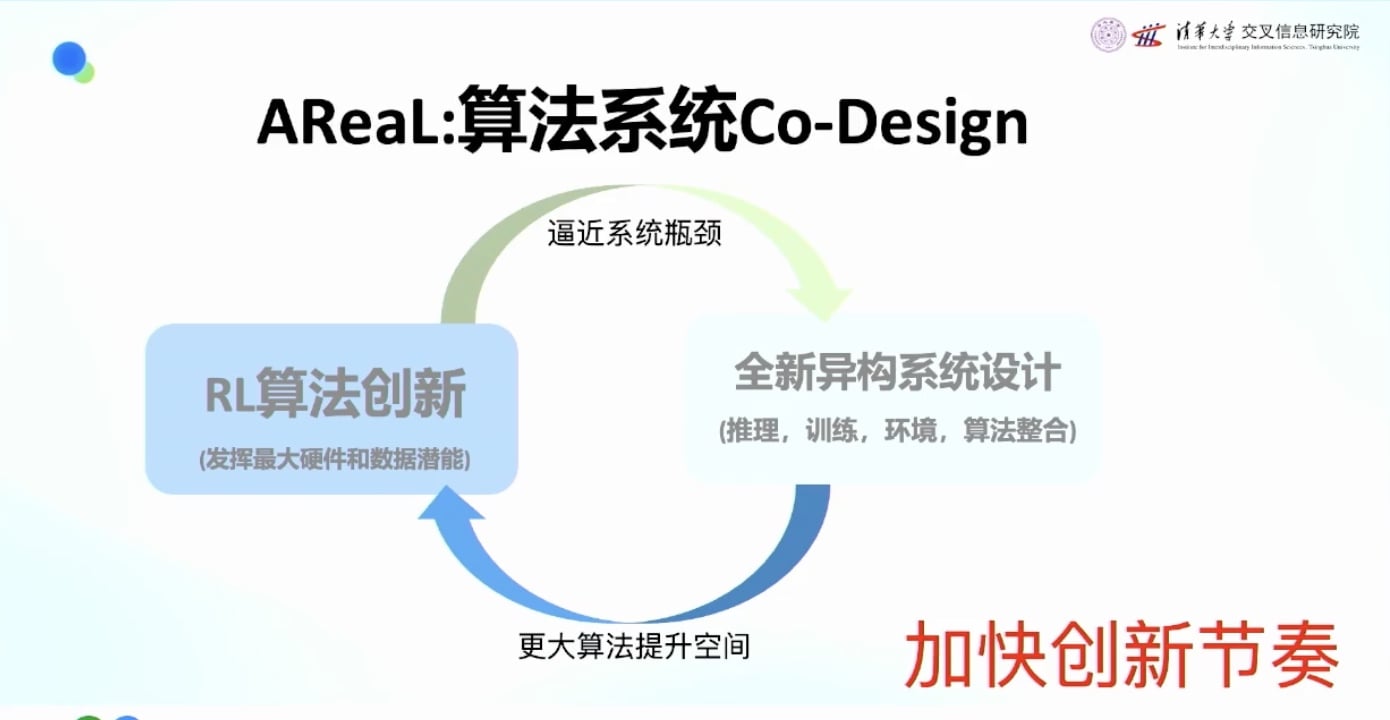
为什么需要协同设计:
- 强化学习算法创新很容易碰到系统瓶颈
- 四个系统模块(推理/训练/环境/算法整合)中任何一个打满都会成为瓶颈
- 强化学习算法很容易打到系统瓶颈
团队组织建议:
- 做算法的同学需要了解Infra
- 做Infra的同学需要了解算法
- 最好能坐在一起工作, 这是加快创新节奏的重要方式
具体的性能瓶颈
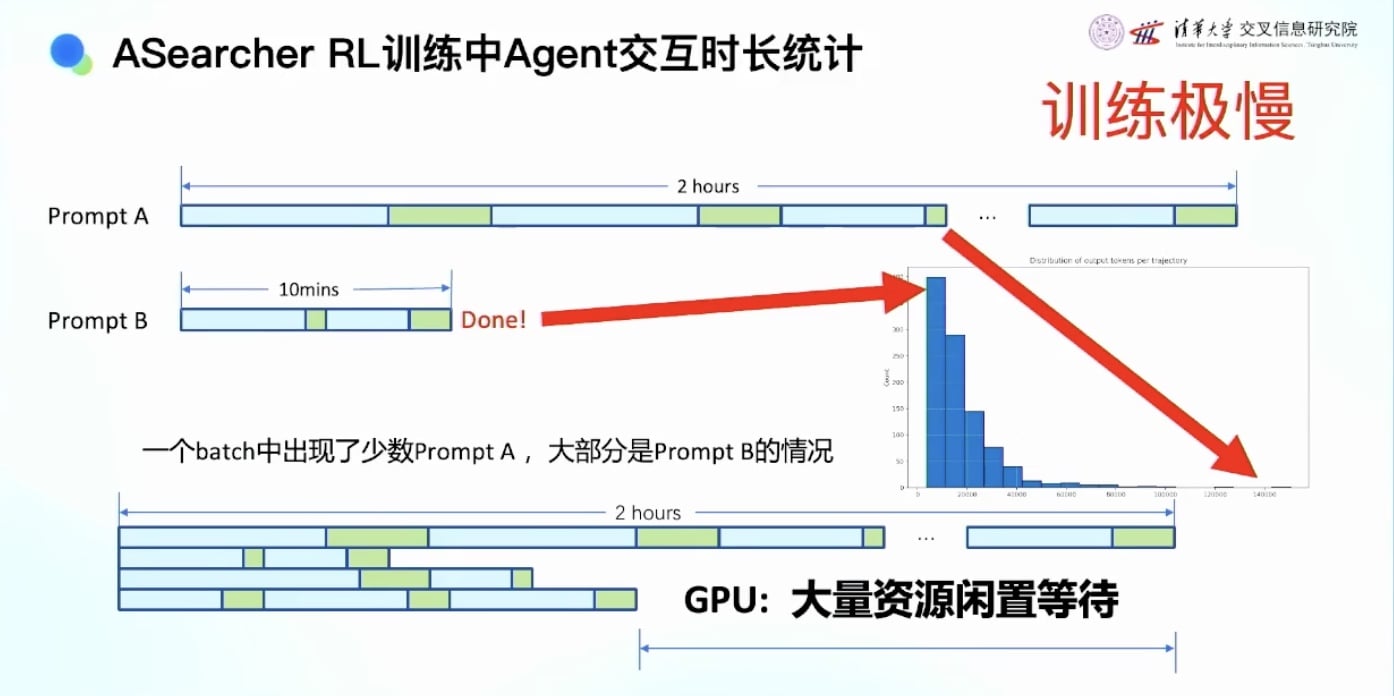
搜索智能体的统计数据:
- 平均搜索时间:要调用 google 搜索引擎, 一个batch 5-10分钟
- 长尾效应严重:特别难的prompt需要1-2小时
- 问题:如果每个batch都要等最慢的那个,一天24小时只能更新12-24次
- 导致大量CPU/GPU等待时间
AReaL的解决方案:异步架构
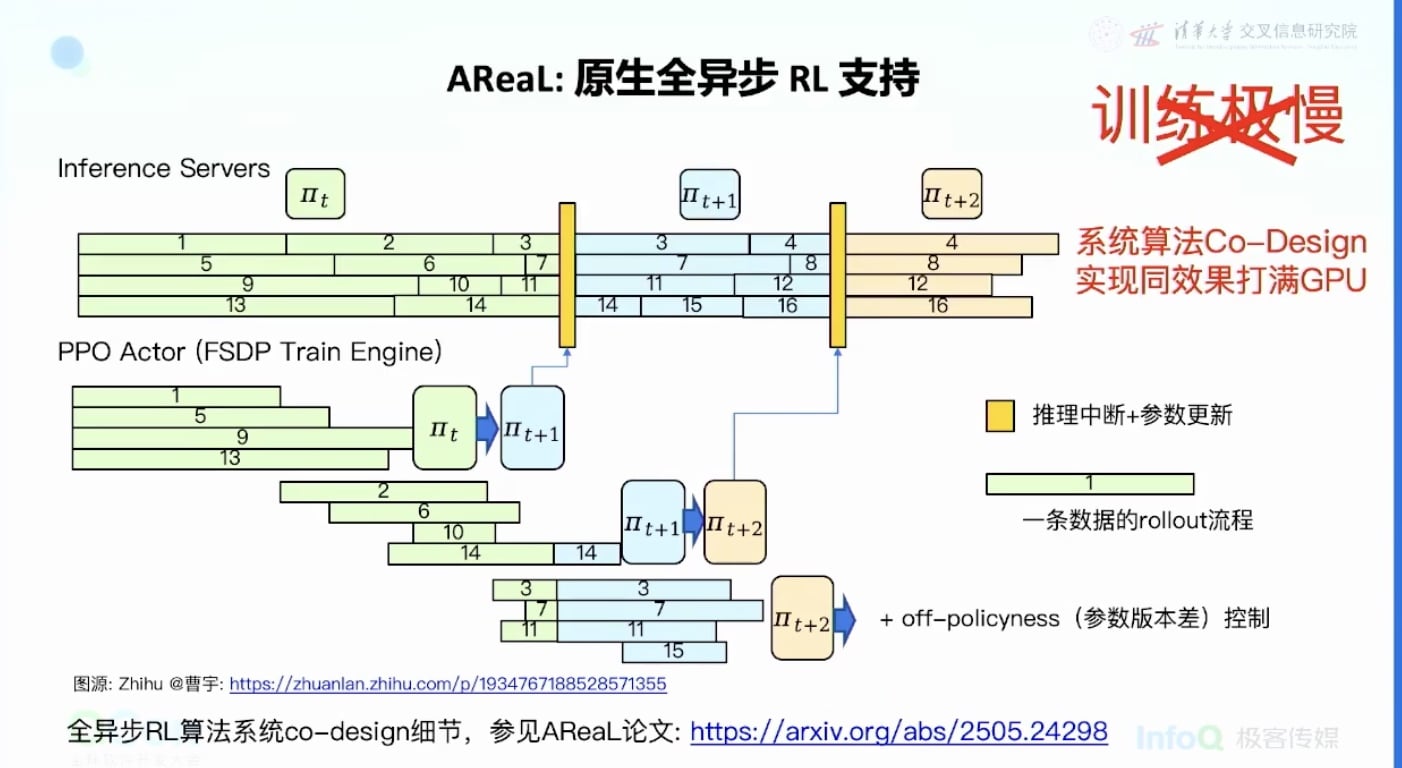
核心思想:推理不能等
- 一部分卡不停地做推理,没有等待
- 训练也没有等待,有数据就训练
- 中间用随时更新参数的方式
- 如果推理到一半需要更新参数,就停下来更新,然后用新参数继续rollout
- 实现完全没有系统资源浪费
技术创新:
- 系统上做异步调整
- 算法上做相应调整以适应异步更新
- 在Agent场景上实现5倍加速,且没有效果损失
训练数据问题

数据稀缺的问题
- 预训练可以直接从网上获取数据
- 强化学习的训练数据不能直接从网上获取
- 一般问题都跟简单, 用户提出的复杂问题很少,难以挖掘复杂问题的测试集
数据合成解决方案
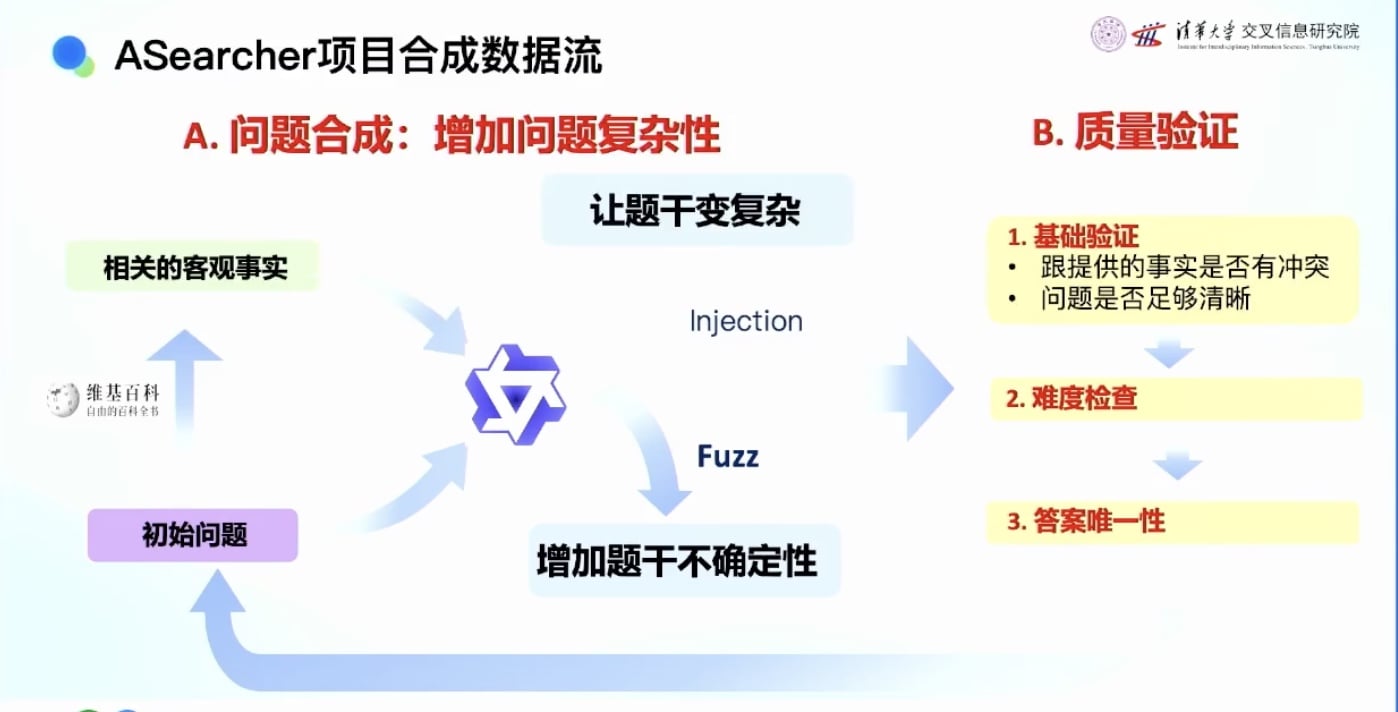
Agenic合成数据方法:
- 从网页上获取答案(搜索比较简单,从答案开始)
- 从答案构造问题
- 不断让问题变得更加复杂
- 评估问题,保证问题和答案匹配正确
- 难度检查:问题不能太难也不能太简单,需要适合强化学习自我提升的难度
- 构造出适合的训练数据
开源贡献:
- 数据、代码和脚本都已开源
- 帮助社区训练更好的Agent产品
环境构建 - Aworld 项目
- 主要是Sandbox等执行环境的构建
- 未来会开源更多的Sandbox项目
- 帮助大家训练更好的Agent产品
让更多人用 RL 训练更好的 Agent
AReaL团队发展历程与经验总结
团队发展时间线

- 2020年:开始做开源学术项目,多智能体强化学习框架
- 2022年:第一个大规模游戏场景可用的强化学习分布式训练框架
- 2023年:当时最快的RLHF框架
- 2024年:开始做AReaL,专注Agent AI
技术循环的有趣观察
回到原点的循环:
- 2025年的强化学习与当年打游戏很像
- 有个大模型在”玩游戏”(Sandbox可以是浏览器或电脑)
- 遇到的问题与打游戏类似:有黑盒环境,很慢,不能修改游戏规则
- 五年后技术回到了当年的原点
- 系统设计和算法技术都有循环
重要的经验教训
技术需要两个条件才能发挥价值:
- 技术需要对的时间
- 强化学习如果在2022年以前,大家很难感知到价值
- 不是大家的错,而是技术没有在对的时间被感知
- 技术需要好的产品承载
- 强化学习技术如果不是因为ChatGPT、RLHF、Agent model,大家可能也感知不到
- 技术本身可能没有价值,需要好的产品去承载才能发挥更大价值
团队理念:
- 技术一定要产品化, 所有技术同学都应该尽可能把技术产品化
- 希望创造能够实现AGI的Agent产品, 成为支持产品持续进化的平台
总结与展望
核心观点回顾
- Agent是AGI时代最重要的事情:从产品发展趋势和技术演进可以看出Agent的重要性
- 强化学习是Agent的最关键技术:能够统一解决Agent面临的复杂问题,让AI涌现出复杂能力
技术发展趋势
- 从简单的对话模型到能够主动行动的Agent
- 从Reactive到Proactive的转变
- 从规则驱动到强化学习驱动的智能涌现
- 算法与系统协同设计的重要性日益凸显
未来展望
- Agent产品将越来越智能和主动
- 强化学习技术将在Agent领域发挥更大作用
- 需要更好的基础设施、数据和环境支持
- 技术产品化是实现价值的关键路径