本文基于 Session 10158 梳理。随着直播互动性增强,对直播延时的要求也越来越高,高延时会严重影响用户体验。本 Session 介绍的 VideoToolbox 低延时编码从编码角度来降低延时,给我们提供了降低延时的新思路。
VideoToolbox 编解码基础
VideoToolbox 简介
VideoToolbox 是苹果提供的一个直接访问硬编解码器的底层框架,可以用来编码、解码和像素格式转换。这些功能都以 session 的形式提供。如果你的 App 中不需要直接访问硬编解码器,那不需要使用 VideoToolbox,可以使用其他框架例如 AVFoundation。

上图为 Apple 视频编解码框架图,我们主要关注 AVFoundation 和 VideoToolbox。
| 框架 | 编码 | 解码 | iOS 编解码类型 |
|---|---|---|---|
| AVFoundation | 直接编码为文件 | 解码后直接渲染播放 | 硬编解码 |
| VideoToolbox | 编码为 CMBlockBuffer | 解码为 CVPixelBuffer,需要自己处理渲染 | 硬编解码 |
VideoToolbox 常用数据结构
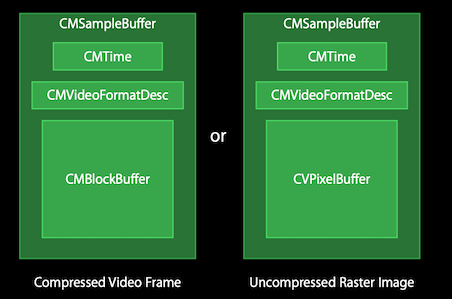
CVPixelBufferPool:CVPixelBuffer 缓冲池,用于管理一组可重用的 CVPixelBuffer
CVPixelBuffer:未编码的原始数据
CMBlockBuffer:编码后的数据
CMFormatDescription:编解码格式信息,包括以下信息:
- Width / Height
- Format Type—(kCMPixelFormat_32BGRA, kCMVideoCodecType_H264,……)
- Extensions—(Pixel Aspect Ratio, Color Space,……)
CMTime:时间信息,表示时间点或者段,value / timeSacle
CMSampleBuffer:编码、解码数据容器,详细结构见下图:
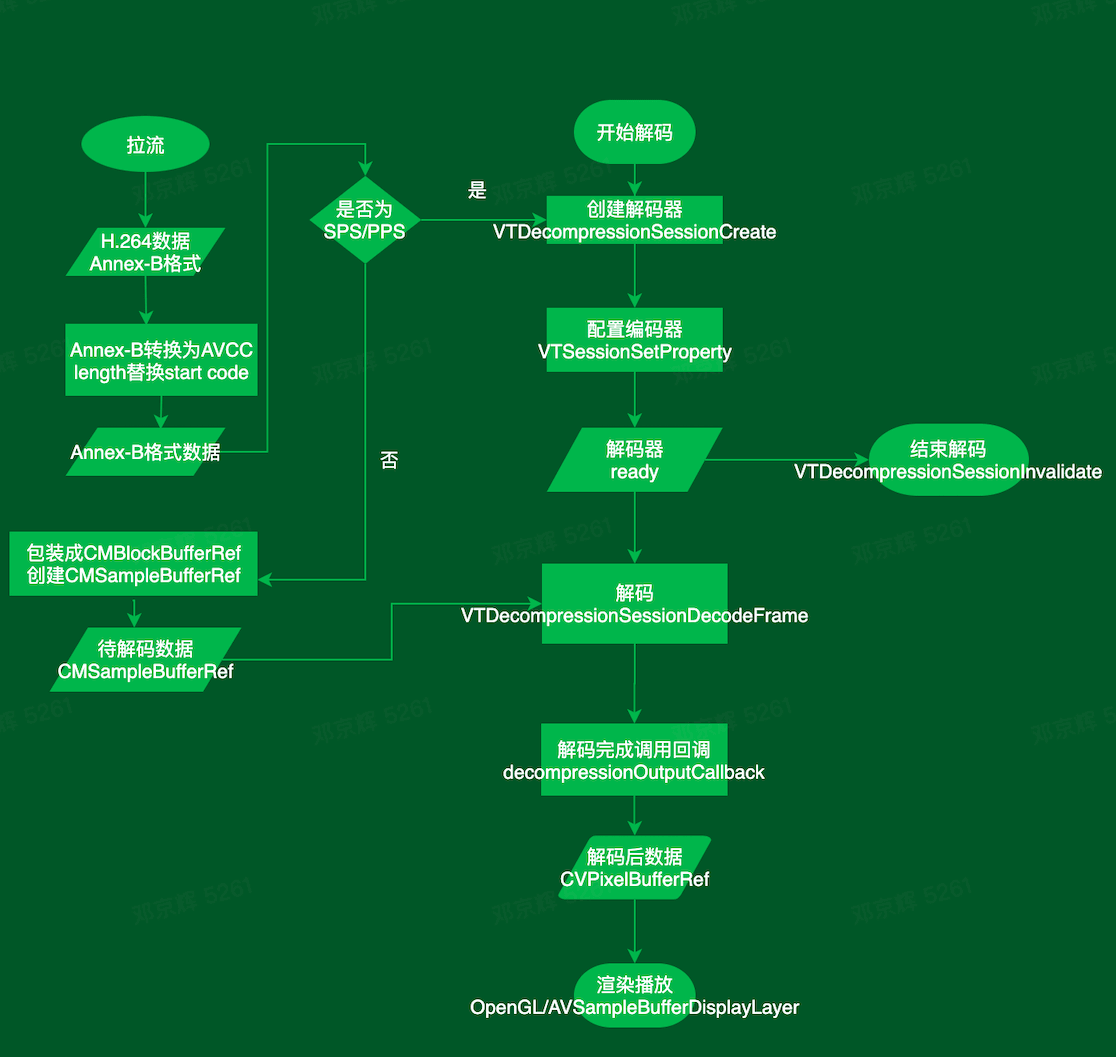
H.264 码流格式
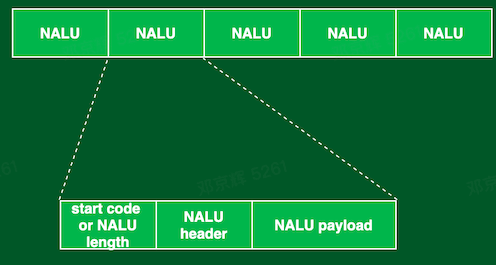
H.264 流是由一系列的 NAL Units(简称 NALU)组成,如下图所示:
NALU 可能包括:
- 视频帧或者视频帧的一个分片(slice)
- H.264 参数集:SPS(序列参数集)和 PPS(图像参数集)
Annex-B 和 AVCC
根据 NALU 的分隔符不同,可以把 H.264 流分为 Annex-B 格式和 AVCC 格式。
| 格式 | 特点 | 常用于格式 | 常用场景 | 备注 |
|---|---|---|---|---|
| Annex-B | 使用 3~4 字节 start code 0x00000001/0x000001 分割,SPS/PPS 为普通 NALU |
ts | 流媒体 | 每个 I 帧前都需要添加 SPS/PPS 信息 |
| AVCC | 使用 4 字节大端序 NALU 长度进行分割,在 extradata 中封装 SPS/PPS |
mp4/flv/mkv | 本地文件 | 只要在文件头添加 SPS/PPS 信息 |
特别需要注意的是:iOS 平台的 VideoToolbox 硬编解码接口只支持 AVCC 的 H.264 数据,而 Android 的 MediaCodec 硬编解码接口只支持 Annex-B 格式的 H.264 数据。
因此对于 iOS 而言,编码后得到 AVCC 格式数据,在推流前需要转为流媒体对应的 Annex-B 格式。拉流解码则刚好相反。
NALU 结构
NALU header
如下图所示,header 占一个字节,分为 3 个部分:
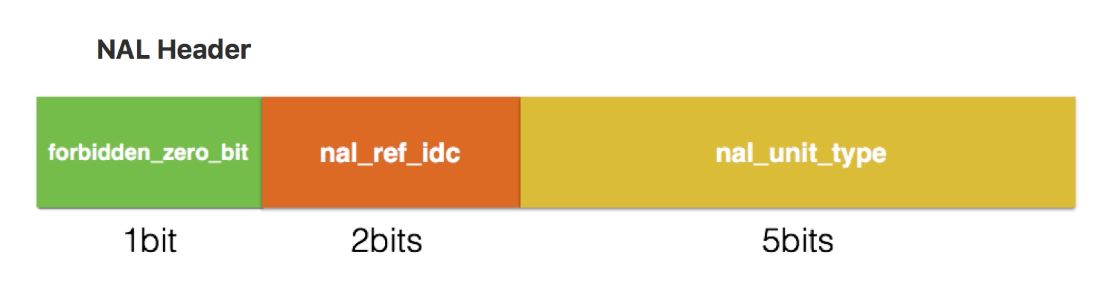
forbidden_zero_bit
禁止位,初始为 0,当网络发现 NALU 有错误时可设置该比特为 1,以便接收方纠错或丢掉该单元。
nal_ref_idc
nal 重要性指示,标志该 NALU 的重要性,值越大,越重要,解码器在解码处理不过来的时候,可以丢掉重要性为 0 的 NALU。
nal_unit_type
NALU 类型,NALU 第 5 个字节(前四个字节为 start code 0x00000001) & 00011111(十六进制为 0x1F),即 int type = (frame[4] & 0x1F)。
常用类型:
- 5:IDR(I 帧)
- 7:SPS
- 8:PPS
编码流程
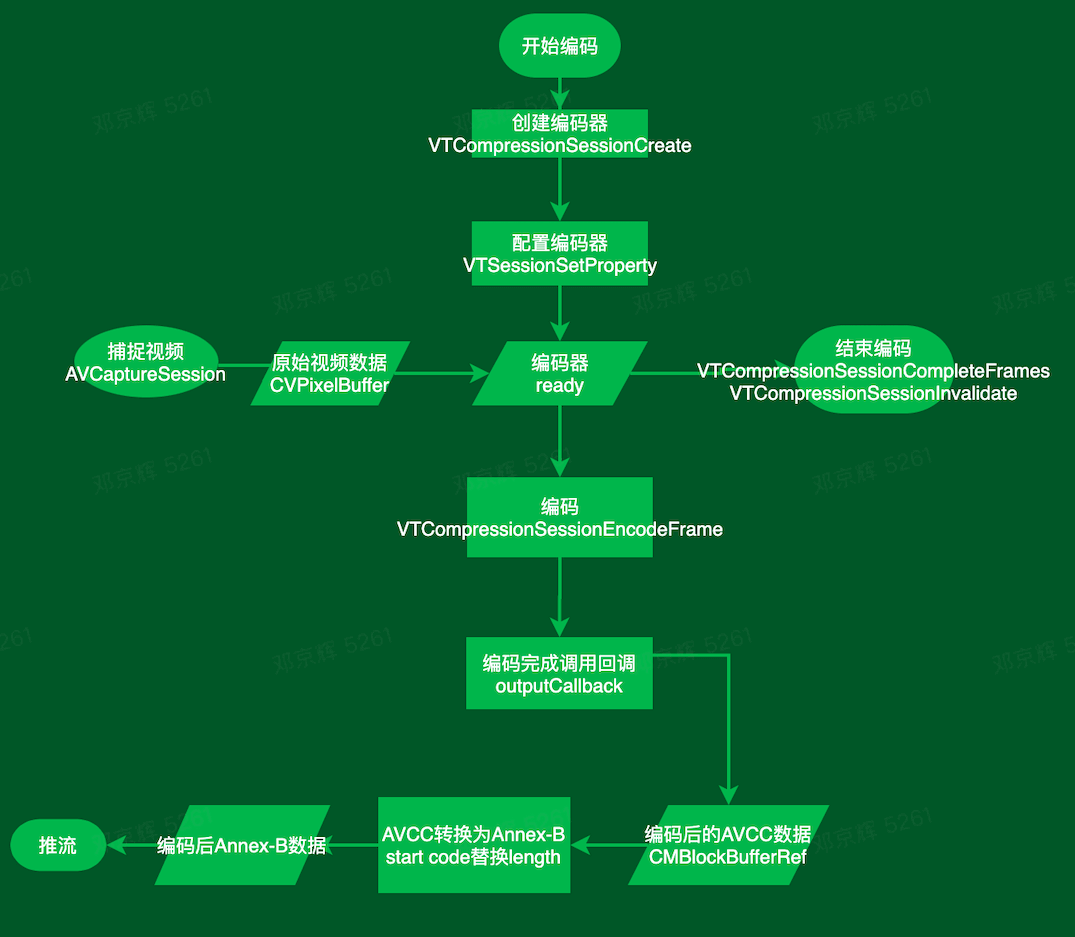
重要的参数、属性:
- CMVideoCodecType:编码类型,kCMVideoCodecType_H264 对应 H.264
- kVTCompressionPropertyKey_ProfileLevel:指定编码比特流的配置文件和级别。直播一般使用 baseline,可减少由于 b 帧带来的延时
- kVTCompressionPropertyKey_RealTime:是否实时编码
- kVTCompressionPropertyKey_AverageBitRate:平均码率
- kVTCompressionPropertyKey_AllowTemporalCompression:是否开启帧间压缩
- kVTCompressionPropertyKey_MaxKeyFrameInterval:设置 GOP 大小,每隔 X 帧有一个关键帧
- kVTCompressionPropertyKey_MaxKeyFrameIntervalDuration:关键帧之间的 duration,每 Y 秒有一个关键帧。这两个属性可以同时设置,满足其中一个即可。
解码流程
重要的参数、属性
- CMVideoFormatDescription:输入视频格式信息,可通过 SPS/PPS 创建。
- destinationPixBufferAttrs:解码输出属性,是 CFDictionary,有如下 key:
- kCVPixelBufferPixelFormatTypeKey:像素格式
- kCVPixelBufferWidthKey/kCVPixelBufferHeightKey:宽高
- kCVPixelBufferOpenGLCompatibilityKey:它允许在 OpenGL 的上下文中直接绘制解码后的图像,而不是从总线和 CPU 之间复制数据。这有时候被称为零拷贝通道,因为在绘制过程中没有解码的图像被拷贝。
- kCVPixelBufferIOSurfacePropertiesKey:使用 IOSurface 来创建 CVPixelBuffer 时,需要为此 key 赋值。赋值为一个空字典表示使用默认的 IOSurface 选项。
- VTDecompressionOutputCallback:解码回调,每次完成解码或者丢帧时都会调用,而且回调会阻塞解码器直到回调 return,因此要避免耗时操作。此外,解码器会以 dts 顺序返回视频帧,B 帧的 pts 和 dts 不一致,需要开发者进行视频帧重排序。
常见问题
VideoToolbox session 后台失效
App 切到后台时,iOS 的 VideoToolbox session 会失效,切回前台后原 session 也不能继续使用,需重新创建 VideoToolBox 实例。
VideoToolbox 低延时编码
概述
低延时编码对于许多视频应用非常重要,尤其是实时视频通信应用。本 session 将介绍 VideoToolbox 中一种新的编码模式,以实现低延时编码,这种新模式的目标是针对实时视频应用优化现有的编码器 pipeline。注意,此模式支持的视频编解码器类型为 H.264,将在 iOS 15.0+ 和 macOS 12.0+ 上引入此功能。
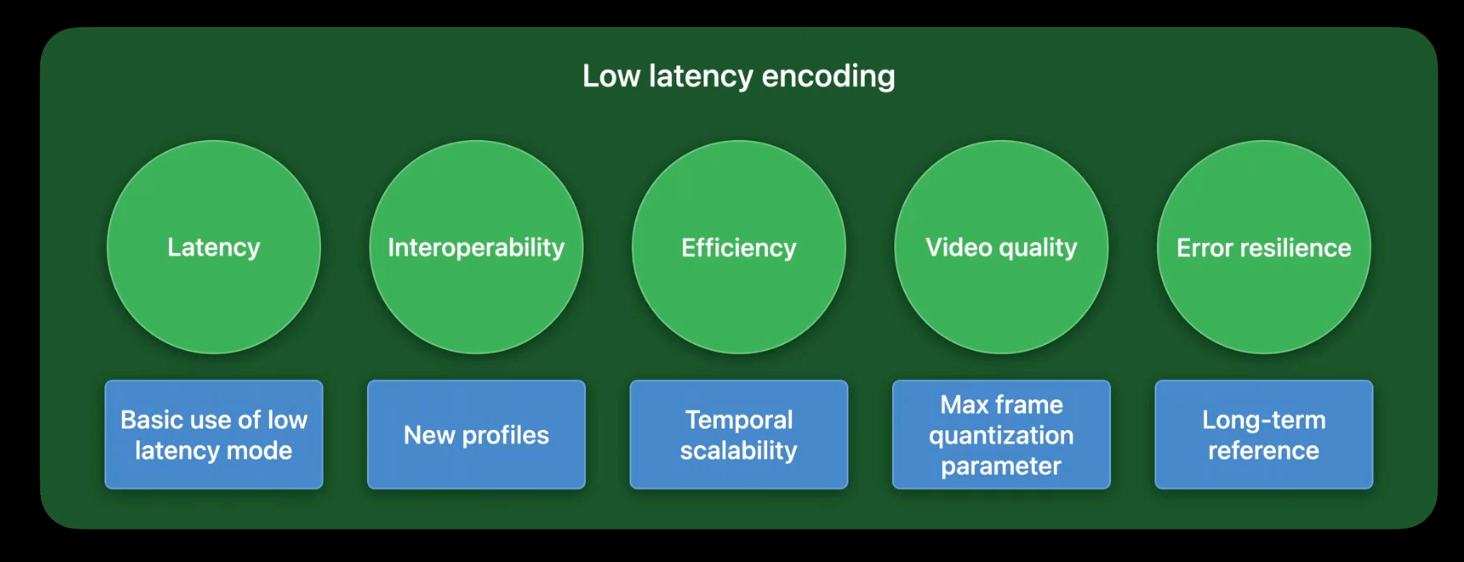
实时视频应用的目标
- 延时:我们需要最大限度地减少通信中的端到端延时,提升交流体验。
- 兼容性:我们需要通过让视频应用能够与更多设备进行通信来增强兼容性。
- 编码效率:当多人视频时,编码器 pipeline 应该是高效的。
- 视频质量:视频应用需要以最佳视觉质量呈现视频。
- 容错能力:我们需要一种可靠的机制来从网络丢失引入的错误中恢复通信。
低延时视频编码将在以上这些方面进行优化,对应的功能为:
- VideoToolbox 低延时编码基础功能
- 新的 profile
- 时间可扩展性(temporal scalability)
- 最大帧量化参数(max frame quantization parameter)
- 长期参考(long-term reference)
低延时编码基础功能
低延时编码是什么?
下图为 Apple 平台上视频编码 pipeline 的简图。
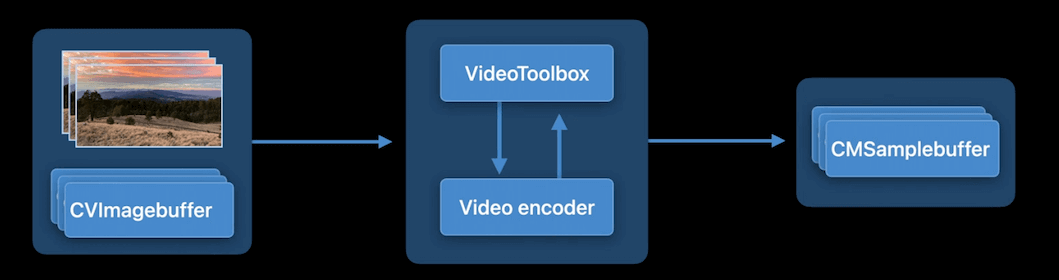
VideoToolbox 将 CVImagebuffer 作为输入,它要求视频编码器执行压缩算法,例如 H.264 以减少原始数据的大小。输出的压缩数据封装在 CMSampleBuffer 中,可以通过网络传输进行视频通信。从上图中我们可以注意到,端到端延时可能受两个因素影响:编码时间和网络传输时间。
为了最大限度地减少编码时间,低延时编码模式去除帧重新排序,遵循一进一出模式。其实相当于把 kVTCompressionPropertyKey_AllowFrameReordering 属性设置为 false:禁用 B 帧,去除因编码 B 帧带来的延时。此外,该模式下的码率控制器对网络变化的适应速度也更快,因此也最大限度地减少了网络拥塞造成的延时。通过这两个优化,我们已经可以看到与默认模式相比有明显的性能提升。对于 720p@30 的视频,低延时编码可以减少高达 100 毫秒的延时。这种节省对于视频会议至关重要。
低延时编码怎么使用?
只需要在 VTCompressionSessionCreate 的入参 encoderSpecification 中设置 EnableLowLatencyRateControl,其他配置和平常的编码流程一样。
1 | let encoderSpecification: [NSString: NSObject] = [ |
低延时编码其他功能
- 新的 profile:新增 2 个 profile 来增强兼容性
- 时间可扩展性(temporal scalability):在视频会议中非常有用,通过降低帧率来满足低带宽网络环境
- 最大帧量化参数(max frame quantization parameter ):可以对图像质量进行细粒度控制
- 长期参考(long-term reference):提高容错能力
新的 profile
实际应用时需要其他端的解码器也支持
Profile 定义了一组解码器能够支持的编码算法。为了与接收方通信,编码后的码流应符合解码器支持的特定 profile。在 Video Toolbox 中,我们支持一系列 profile,例如 baseline profile、main profile 和 high profile。该系列添加了两个新 profile:constrained baseline profile(CBP) 和 constrained high profile(CHP)。CBP 主要用于低码率应用,而 CHP 具有更先进的算法以获得更好的压缩比。
1 | VTSessionSetProperty( |
时间可扩展性(temporal scalability)
使用该特性可以提高多方视频通话的效率。
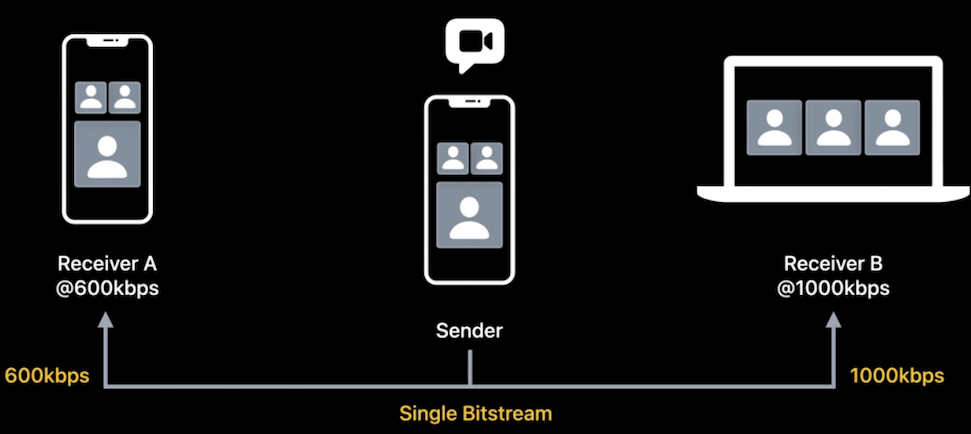
下图为一个简单的三方视频会议场景:在此模型中,接收方 A 的带宽较低为 600 kbps,而接收方 B 的带宽较高为 1,000 kbps。通常,发送方需要对编码输出两路码流,以满足每个接收方的下行带宽(ps:实际现在一般是主播推一路流,cdn 进行转码),这可能不是最佳的方案。
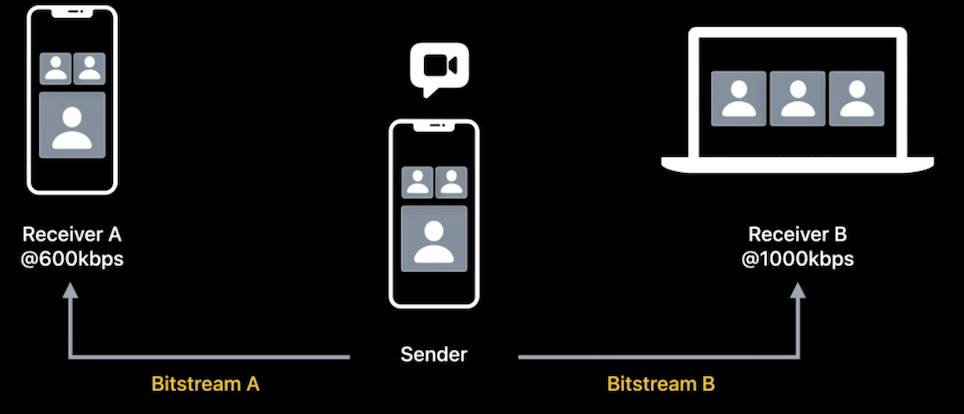
当使用该特性时,编码会更高效,模型如下图:发送方只需要编码输出一路码流,然后根据接收方进行分层。
实现原理
下图为一组视频帧,其中每一帧都使用前一帧作为参考帧。可以将一半的帧放入另一层,更改参考帧,以便只有原始层中的帧用于参考帧。原始层称为 base layer,新构建的层称为 enhancement layer。enhancement layer 可以作为 base layer 的补充,以提高帧率。对于接收方 A,我们可以发送 base layer 帧,因为基础层本身已经是可解码的。更重要的是,由于 base layer 仅包含一半的帧,因此传输的码率将很低。接收方 B 可以享受更流畅的视频,因为它有足够的带宽来接全部视频帧。


收益
通过降低帧率来满足低带宽网络环境:base layer 可以用 60% 的码率来达到 50% 的帧率。
增强容错能力:enhancement layer 中的帧不用于预测,因此对这些帧没有依赖性。这意味着如果在网络传输过程中丢失了一个或多个增强层帧,其他帧不会受到影响。

API
1 | // 创建并开启低延时编码器 |
长期参考(long-term reference,LTR)
LTR 可用于错误恢复。下图显示了 pipeline 中的编码器、发送方和接收方。假设视频通信的网络状况不佳。由于传输错误,可能会发生帧丢失。当接收方检测到帧丢失时,它可以请求刷新。如果编码器收到请求,通常它会编码一个关键帧(I 帧)以用于刷新。但关键帧通常相当大。大的关键帧需要更长的时间才能到达接收方。由于网络条件已经很差,关键帧可能会加剧网络拥塞问题。
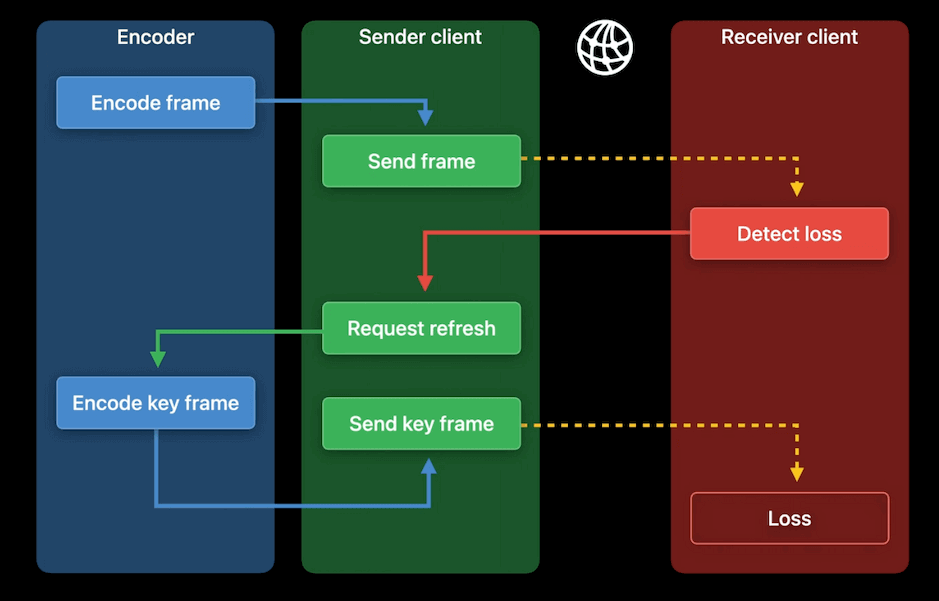
实现原理
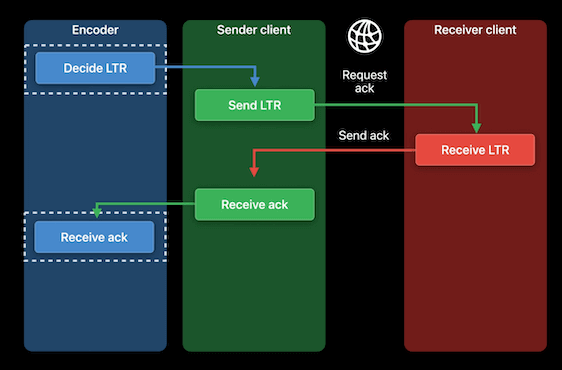
那么,我们可以使用 P 帧而不是关键帧进行刷新吗?答案是肯定的,如果我们有帧 ack 机制。原理如下图所示:
- 首先,我们需要确定需要 ack 的帧。我们称这些帧为长期参考帧或 LTR 帧。这是编码器的决定,编码后的 LTR 帧附加信息中有 AcknowledgementToken,用来标记该 LRT 帧。
- 当发送方传输 LTR 帧时,还需要接收方 ack。如果接收方成功接收到 LTR 帧,则需要返回 AcknowledgementToken。
- 一旦发送方收到 ack,并在编码时把收到的 AcknowledgementTokens 发送给编码器,编码器就知道对方收到了哪些 LTR 帧,就可以用这些 LTR 帧来生成 P 帧。由于一次可以收到多个 ack,需要使用一个数组来存储这些 AcknowledgementTokens。
- 当编码器收到接收方刷新请求时,由于编码器有一堆已确认的 LTR 帧,它可以从中选取一帧作为参考帧进行编码得到一个 P 帧,以这种方式编码的帧称为 LTR-P。与关键帧相比,LTR-P 大小通常要小得多,因此更容易传输。如果没有确认的 LTR 可用,编码器将生成一个关键帧。
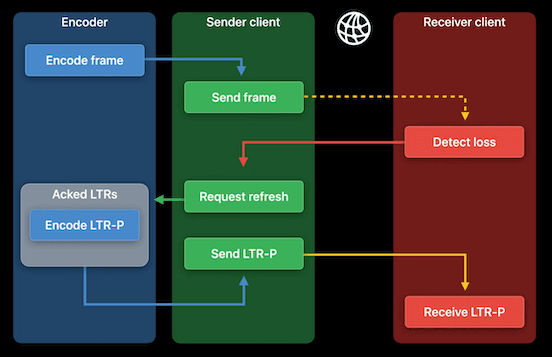
LTR API
帧 ack 需要由应用层处理。它可以通过 RTP 协议中的 RPSI 消息等机制来完成。这里只关注编码器和发送方在这个过程中是如何通信的。
API
1 | // 创建并开启低延时编码器 |
业界降低延时的方法
优化播放器缓冲区配置
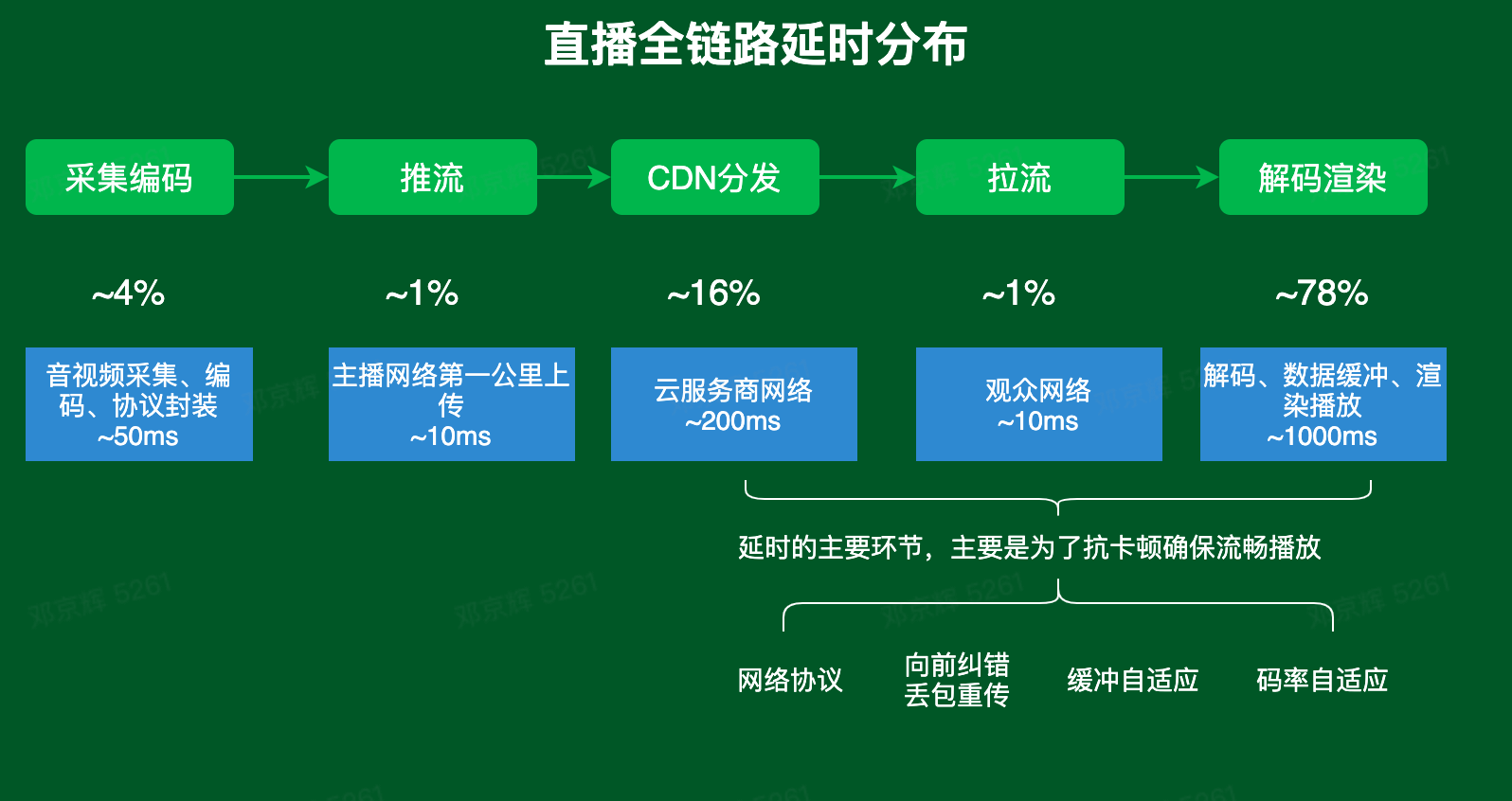
下图为直播全链路延时分布图,这里重点关注解码渲染时播放器的数据缓冲区,为了抗卡顿确保流畅播放,播放器必须要缓冲媒体数据。缓冲区引入的延时在全链路比重占据较大,因此优化缓冲区配置是一个降低延时的常用手段。
选择合适的协议
目前国内外主流的音视频直播协议多种多样,国内使用比较多的是 rtmp 推流 flv 拉流方案,国外使用比较多的有 hls/dash 等。可以根据不同的直播场景和不同的延时要求选择合适的协议,具体如下:
| 协议 | 传输方式 | 封装格式 | 延时 | 数据分段 |
|---|---|---|---|---|
| http-flv | http | flv | 3~7sec | 连续流 |
| rtmp | tcp | flv-tag | 2~4sec | 连续流 |
| hls | http 文件 | ts | 8~15sec | 切片文件 |
| dash(cmaf) | http 文件 | mp4/webm | 3~10sec | 切片文件 |
| quic | udp | flv-tag | 3~10sec | 连续流 |
| rts | udp | rtp | 0.6~1.2sec | 连续流 |
| srt | udp | ts | < 1s | 连续流 |
- RTMP(Real Time Messaging Protocol)是基于 TCP 的,由 Adobe 公司为 Flash 播放器和服务器之间音频、视频传输开发的开放协议。
- HLS(HTTP Live Streaming)是基于 HTTP 应用层的以 Apple 公司主导开发的音视频传输协议。
- HTTP FLV 则是将 RTMP 封装在 HTTP 协议之上的,可以更好的穿透防火墙等。
- CMAF (通用媒体应用格式 Common Media Application Format) 是利用的 ISOBMFF,fMP4 容器,同 HLS 类似,将视频流分段进行传输。
- QUIC(Quick UDP Internet Connection)是谷歌公司制定的一种基于 UDP 协议的低时延传输协议;它将很多可靠性的验证策略从系统层转移到应用层来做,更适合现代流媒体传输的拥塞控制策略。iOS 15+/macOS 12+ 的 Network 框架已经支持了 HTTP3/QUIC,并可以将自有协议转换至 QUIC 之上。更多细节请参考 Accelerate networking with HTTP/3 and QUIC。
- RTS (Real Time Streaming via WebRTC)是基于谷歌 webRTC 的一种实时音视频传输技术,底层构建于 UDP 之上,浏览器通用兼容标准。
- SRT(Secure Reliable Transport)是一种能够在复杂网络环境下实时、准确地传输数据流的网络传输技术,它在传输层使用 UDP 协议,具备 UDP 速度快、开销低的传输特性,支持点对点传输,无需中间进行服务器中转。SRT 的更多信息请查阅 Secure Reliable Transport (SRT) Protocol。
总结
–
本 session 介绍了 VideoToolbox 中新引入的低延时编码模式,从编码角度来降低直播延时。但是该模式只支持 H.264 编码,而且实际应用时需要考虑到多端兼容和应用层协议的支持,更多是苹果在 H.264 低延时编码方面的一些探索。