JPEG 与有损压缩
一张图片通过屏幕展示一般需要解码和渲染两个步骤, 解码将图片原始数据转换为像素点, 渲染将像素点展示在屏幕上. 图片原本就是像素点组成, 展示在屏幕上仍旧是像素点, 为什么还需要解码呢?
我们以常用的 RGB 格式为例, 每一个像素点需要红绿蓝三个颜色各 8bit 来表示, 即一个像素点有 24 bit / 3 字节, 一张 1980*1080 的图片需要存储理论上需要 6.1MB(1980*1080*3/1024/1024=6.1MB), 但是实际一张这样的 PNG 图片大概只有 4MB, JPEG 格式的甚至只有 500KB, 这就是图片压缩的效果.
- 一方面信息的存储有着巨大的冗余, 比如一张纯色图明显没必要存储所有的像素点, 这是无损压缩技术; (PNG)
- 另一方面, 人眼会更在乎一张图的大体轮廓, 对于细节则较为不敏感, 因此保留轮廓信息忽略一些细节纹理可以进一步压缩, 这是有损压缩技术. (JPEG)
为什么颜色描述一般使用 8bit?
8bit 的 RGB 一共可以描述 2^24 个颜色, 大约 1678 万个颜色, 而学术界通常认为人眼能够识别的颜色种类最多有 1000 万种, 这个数字当然是因人而异的, 所以 8bit 实际已经能够匹配人眼的视觉范围. 而近些年有些支持 10bit / 12bit 的设备, 虽然可以形成更加细腻的视觉效果, 同时也会导致存储成本成倍增长, 更关键的是绝大部分屏幕也只支持 8bit 的色彩.
JPG 原理
JPEG 的工作原理大致分为以下几步:
- 颜色空间转换, 从RGB到Y,Cb,Cr
- 采样, YCbCr 可以减少 1/4 的信息
- 图像分割, 分割成8*8的小块
- DCT(Discrete cosine transform) 离散余弦变换
- Quantization(数据量化, 压缩很大一部分是在这里的)
- Huffman coding(对数据进行编码, 进一步压缩)
YUV / YCbCr 有损压缩
首先转换颜色空间, 一般开发中我们会使用 RGB 的颜色, JPEG 会将 RGB 转换为 YCbCr, 颜色空间转换的原因, 在文章How JPG Works这么解释:
JPG converts from RGB to Y,Cb,Cr color model; Which comprises of Luminance (Y), Chroma Blue (Cb) and Chroma Red (Cr). The reason for this, is that psycho-visual experiments (aka how the brain works with info the eye sees) demonstrate that the human eye is more sensitive to luminance than chrominance, which means that we may neglect larger changes in the chrominance without affecting our perception of the image. As such, we can make aggressive changes to the CbCr channels before the human eye notices.
JPG 将 RGB 转换为YCbCr 颜色空间, 包括亮度 (Y)、色度蓝 (Cb) 和色度红 (Cr)。原因是心理视觉实验(也就是大脑如何处理眼睛看到的信息)表明人眼对亮度比对色度更敏感, 这意味着我们可以忽略较大的色度变化并且不影响我们对图像的感知。因此, 我们可以在人眼注意到区别前对 Cb Cr 两个通道进行较大的更改。
YUV 和 RGB 是不同的色彩空间, RGB 是采用三种基本色为基础进行叠加, 从而产生不同的颜色; 而 YUV 是通过亮度和色差来描述颜色的颜色空间, Y表示明亮度(Luma), 也就是灰阶值, U 和 V 表示的则是色度(Chrominance)和浓度(Chroma), 作用是描述影像色彩及饱和度, 用于指定像素的颜色。因此对于黑白显示设备, 只需要去除色度分量, 只显示亮度分量即可。YUV细分的话有Y’UV / YUV / YCbCr / YPbPr等类型, 其中YCbCr主要用于数字信号。在流媒体领域中, YUV 其实就是指 YCbCr。
YCbCr的Y与YUV中的Y含义一致, Cb和Cr与UV同样都指色彩, Cb指蓝色色度, Cr指红色色度
RGB和YUV的换算公式如下:
1 | Y = 0.299 R' + 0.587 G' + 0.114 B' |
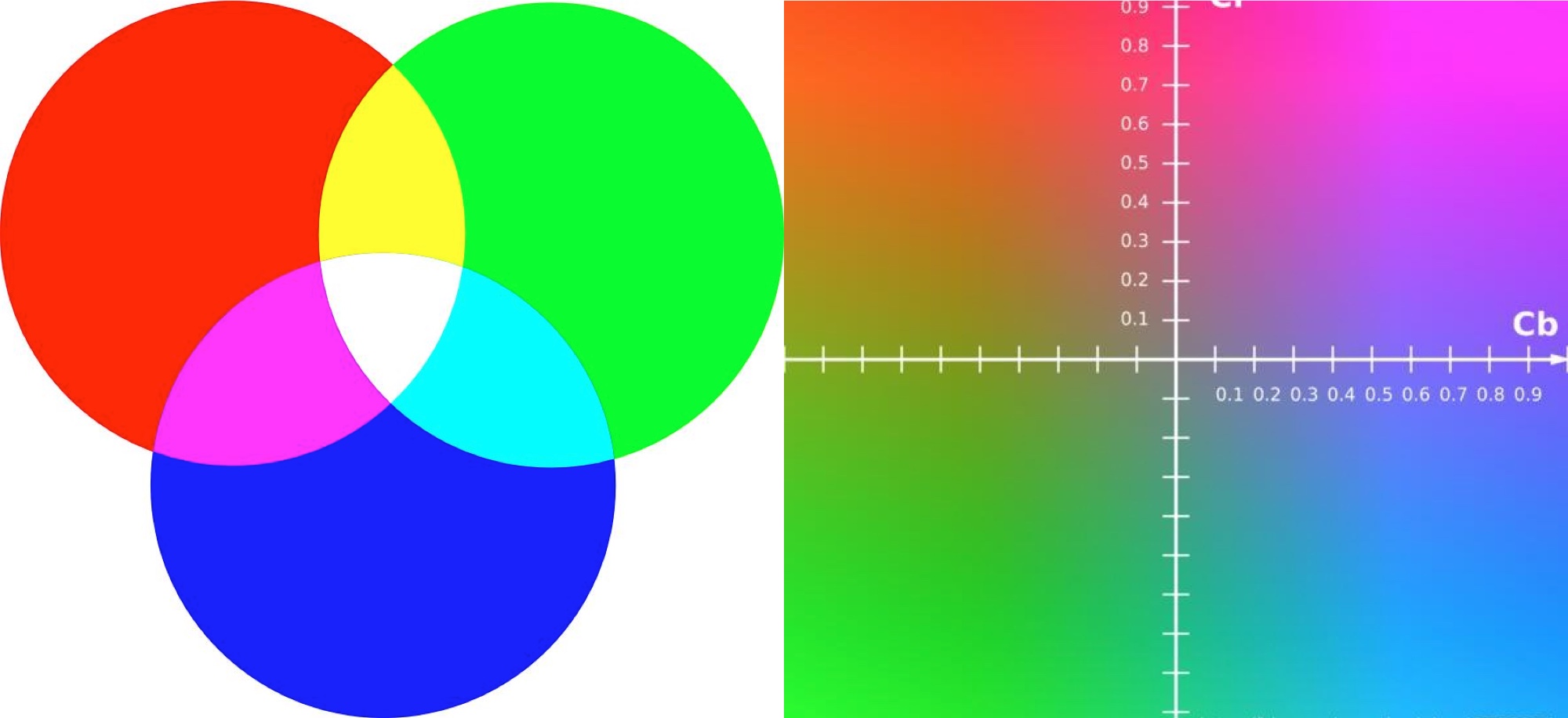
对于不同明亮度, UV 的表现如下: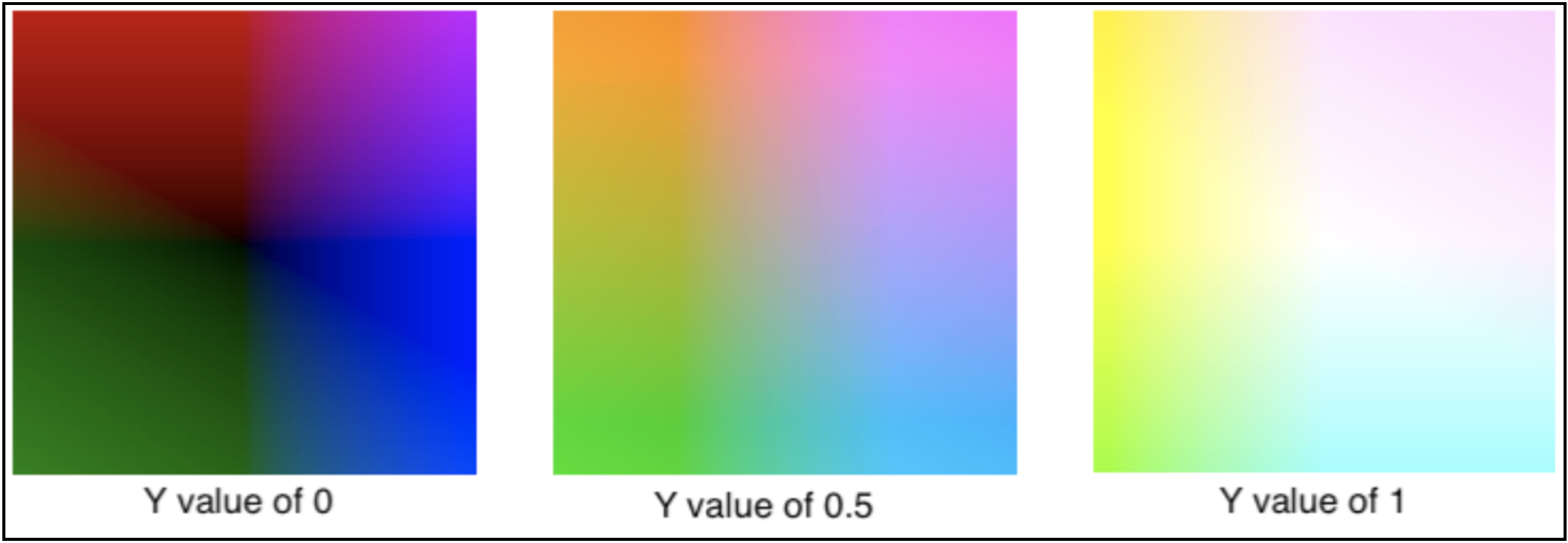
YUV采样方式(即YCbCr)
YUV 码流的存储格式其实与其采样的方式密切相关, 主流的采样方式有三种, YUV4:4:4, YUV4:2:2, YUV4:2:0,
4:1:1含义就是:在2x2的单元中, 本应分别有4个Y, 4个U, 4个V值, 用12个字节进行存储。经过4:1:1采样处理后, 每个单元中的值分别有4个Y、1个U、1个V, 只要用6个字节就可以存储了。
- YUV 4:4:4采样, 每1个Y对应一组UV分量, 消耗 3*4 = 12byte
- YUV 4:2:2采样, 每2个Y共用一组UV分量, 邻近4个像素点的亮度分量是被完整保留, Cb/Cr分量分别进行了下采样只保留了1/2, 而人眼看起来几乎不会察觉到变化. Y: 4byte, U: 2byte, V: 2byte, 共 8byte, 就这样简单粗暴的操作我们就节省出了1/3的存储空间
- YUV 4:2:0采样, 每4个Y共用一组UV分量, Y: 4byte, U: 1byte, V: 1bit, 共 6byte, 对应地可以节省出 1/2 的空间.
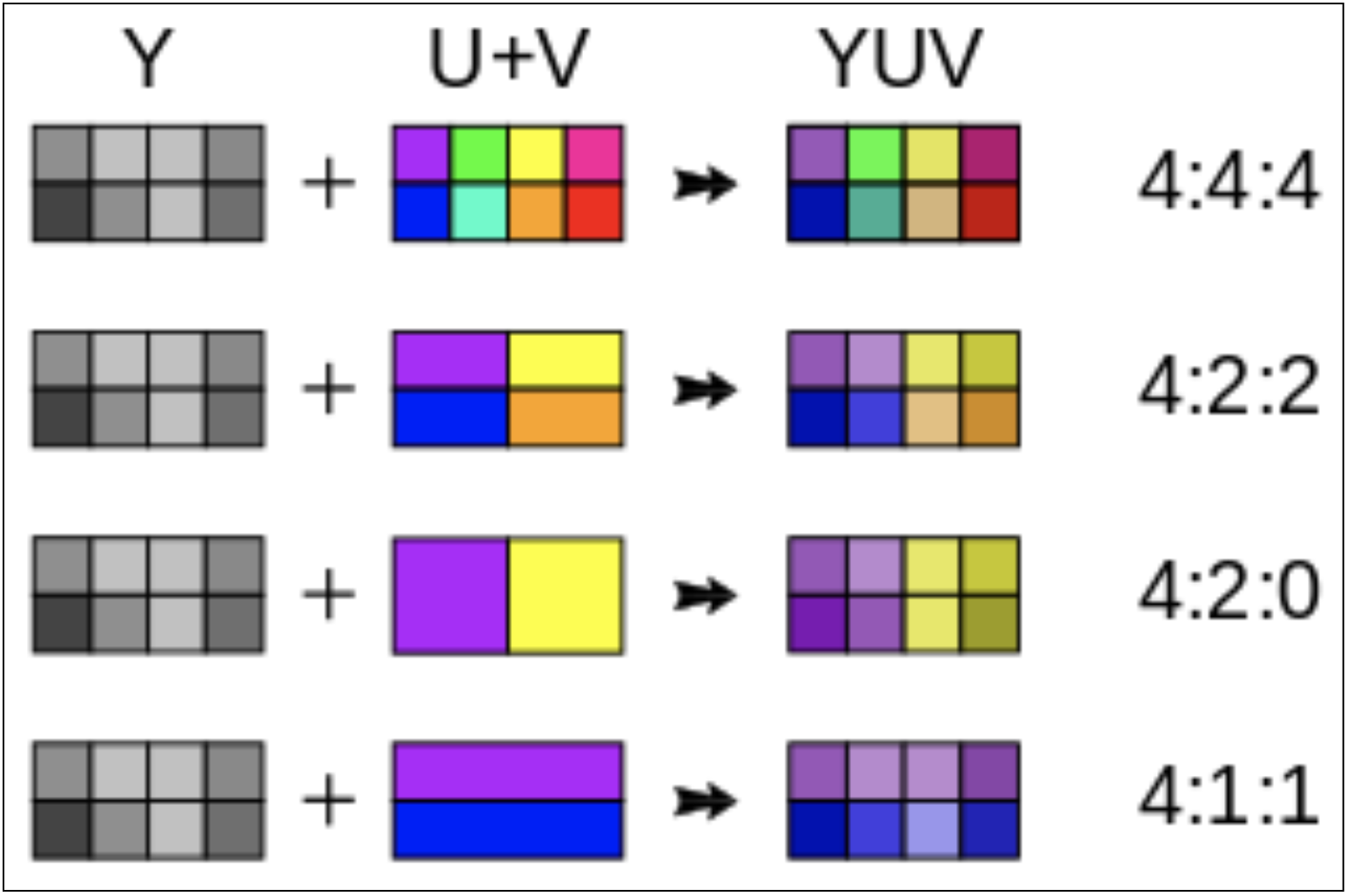
但是这种通过色彩空间的压缩太过于简单粗暴了, 接下来我们看下 JPEG 是怎么通过数学工具做压缩的.
图像分割
然后将图像分成8*8的小块, 分成这么大是有原因的:
- 我们通常认为8x8像素块里没有太多的差异
- 太大的话进行矩阵操作复杂度上升
- 太小的话包含的信息太少, 在 DCT 中不能实现很好地压缩
JPEG编解码
上面的步骤都还是很常规的, 接下来才是 JPEG 关键的地方.
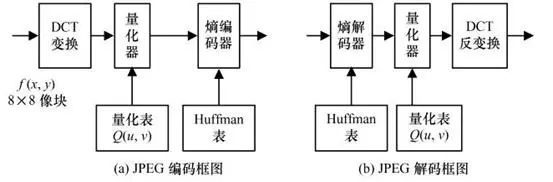
上图是 JPEG 简要的编解码框架, 其中熵编码是无损的, DCT变换理论上是无损的, 当然计算机计算过程存在着精度损失。真正的“有损压缩”步骤在于量化表进行量化这一步。
离散余弦变换(DCT)
离散余弦变换的原理是, 任何的复杂信号, 都可以透过傅里叶转换分解为基波和许多频率不同、幅度不等的谐波的叠加。
将它扩展到二维就可以对图像进行处理。其思想是, 任何8x8块可以表示为不同频率上加权余弦变换的和。
通俗点讲任何 8*8 的图像都可以由这64幅图像乘以不同的系数并叠加而得到。
像下面这张图, 转换为 YUV 后, YUV 的某一个分量的划分的小块, 有 8 行 8 列.为了 DCT 变化需要的定义域对称, 矩阵中数组需要减去 128, 得到一个 -128~127 的数字范围的新的矩阵, 然后开始 DCT 变换, JPEG 中使用的是 DCT II 的公式, 根据上图 64幅图像的叠加, 得到了 64 幅图系数, 即新的矩阵, 可以看到左上角的系数比较大, 即图像大体的轮廓这样的低频信号, 右下角数值比较小接近于 0, 表示图像的细节纹理等高频信号.
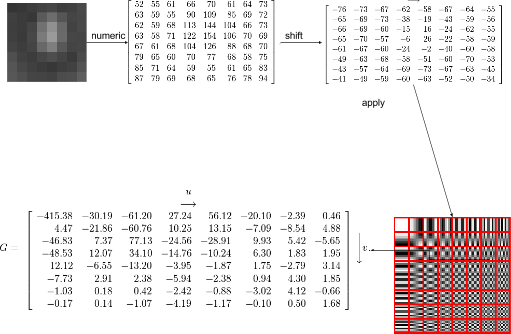
人眼一般对细节不敏感, 更注重图像的大体的轮廓, 因此可以将高频信号舍弃, 以达到压缩的目的, 及接下来的量化阶段.
量化
量化的实质就是将 DCT 转换后的系数除以一个整数, 当系数矩阵经过量化之后, 将系数由浮点数转变为整数, 并且在右下角出现大量连续的 0, 这才便于执行最后的编码, 这一步是有损的, JPEG 有两份量化表可供选择, 分别为亮度量化表和色度量化表(基于大量实验得出这个量化表视觉上的损失最小):
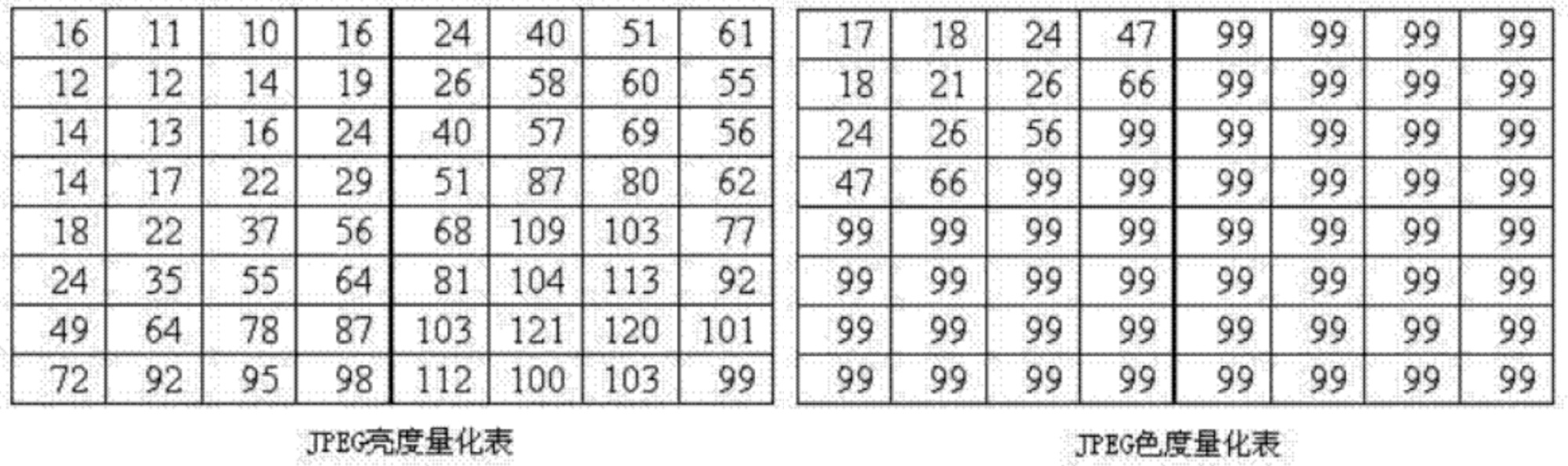
由于人眼对亮度更敏感, 左边的亮度量化表数值较小, 而色度量化表的数值比较大, 保证了色度量化后, 在右下角会出现大量 0, 进一步提高压缩比.
量化表会被保存在 JPEG 文件中, 一般会使用上述的标准量化表, 部分软件如Photoshop使用了自定义的量化表, 也即量化系数由他们自己实验得到的。
zigzag scan & 霍夫曼编码 (熵编码)
得到量化后的矩阵就要开始编码过程了, 首先要把二维矩阵变为一维数组, 这里采用了 zigzag 排列, 将相似频率组在一起:
在JPEG实现的时候, 对于DC系数(左上角的那一个元素)和AC系数(剩下的的63个元素)采用了不同的处理。
对DC系数使用DPCM(差分脉冲调制码), 用当前的DC减去前一个子图的DC, 然后使用Huffman编码。
对AC系数, 则使用Zig-Zag方式扫描, 然后使用Huffman编码。
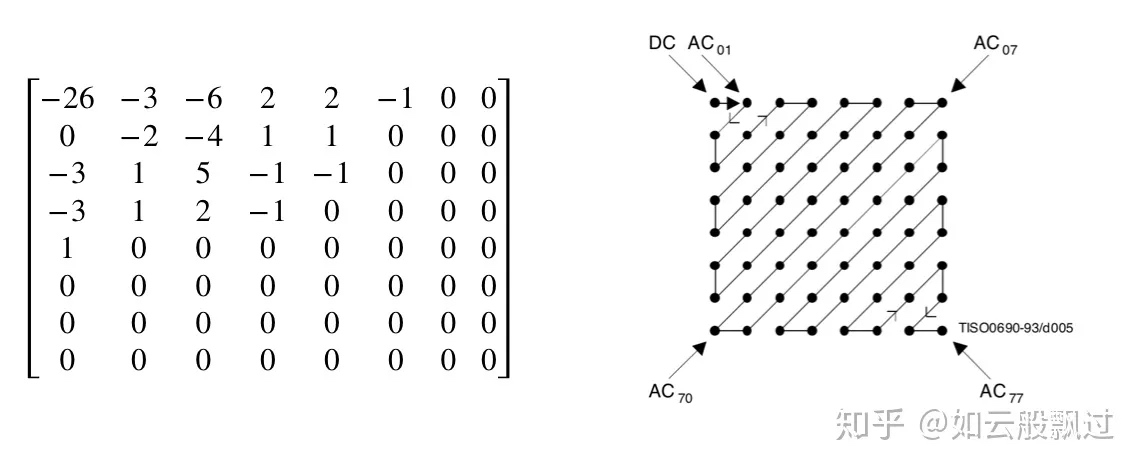
得到序列之后再使用霍夫曼编码进一步压缩

EOB(End Of Block) 字段表示从字段开始后面全为0.
影响JPEG图片质量与文件大小因素总结
与图片的质量相关的因素有
- Quality factor
- 色度抽样, 即 YUV 的采样
- 图像处理, 包括平滑以及锐化,
- 平滑主要应用在噪声比较多的图片, 看起来更平滑一些, 噪声明显减少, 带来的问题是图片的细节会丢失
- 锐化主要是增强图片的细节, 让图像看起来更加清晰
与图片的大小相关的因素有
- Quality factor
- 色度抽样, 即 YUV 的采样
- 图像处理:上面提到的平滑与锐化操作也会带来文件大小的变化, 一般情况下平滑会减少文件的大小5%-10%;而锐化则会增加文件的大小, 比例约为5%-15%。
- Exif信息:Exif信息所占文件大小的比例有限, 但对于小图片来说, 这个占比是很高的, 有的甚至能达到60%, 如果业务不需要这些信息, 还是将其去除吧。通常在移动端的图片, 更适应这样操作。
- Huffman编码优化:这是编码优化的问题, 通常进行Huffman编码优化会带来0%-5%压缩率的提升。
其他图像压缩格式
GIF
GIF在头部信息中规定了一个调色板, 里面最多可以预先填充256种颜色, 但是8位真彩色可以表达的颜色范围有1670万种, 这里就涉及相近颜色的合并问题, 通用的图像处理库通常会采用八叉树结构对RGB数据进行统计和管理。
8位RGB颜色构成的八叉树共拥有8层,理论上八叉树最多可拥有19173961个结点。相近颜色合并的前提是需要定义颜色之间的“距离”。关于距离的定义我们这里不详细描述,直接给出颜色归并的原则:
- 首先归并深度最大的子树
- 深度相同则频度较小的子树先归并
- 取被归并子树结点的均值作为代表色
通过颜色归并操作,图像中会产生诸多颜色相同的块状区域,这非常有利于发挥GIF中LZW压缩算法的特点:对于连续重复出现的字节和字符串,LZW算法有着很高的压缩比(这部分属于熵编码即无损编码的范畴)。
由于颜色合并操作对于带宽节省作用非常明显,而且人们以前通常不会对GIF动图的单帧细节要求很高,针对GIF的降色操作已在现网应用多年。但现实是总会有一些bad case会让人觉得不太满意。
在将这张Thompson的GIF图降色至50色的时候,可以明显的发现Thompson的手臂和球衣肩部处已经呈现出非常明显的带状和块状失真。那么问题来了,在不增加颜色数的前提下有什么补救效果的办法呢?
Dither 抖动图像处理
这里需要提到名为Dither(抖动)的一类算法,这里利用了人眼视觉的错觉。据说这个名称来源于二战时期用于导航和轨道计算的计算机。当时的工程师发现这类机器在飞行甲板上运行的比在地面上更为准确,结果发现是甲板上震动降低了机器部件精度截断导致的错误,于是后来专门在这些计算设备中安装了震动马达,同时把这种马达的震动称为dither。
下面这张图清晰地演示出dither技术的视觉效果,当我们使用红色和蓝色两种色彩互相间隔地排成国际象棋似的方格盘时,随着方格被切分的越来越小,我们惊奇地发现我们看到了原来不存在的颜色-桃红色!

Dither使用效果前后对比图
然而利用dither的代价是比较大的,dither算法会显著提高GIF压缩的时间消耗,一般不建议在线服务使用这种技术,在异步服务中是值得考虑的选项。
Guetzli
Guetzli,这不是一个新的编码器。
Google瑞士研究院开发的Guetzli在开放之初通过自媒体的宣传,容易让人误以为Google开发了新的编码方法,但实际上单就编解码技术而言,Guetzli采用的就是标准的JPEG编码方法,没有任何创新。它的技术点在于它基于人眼的视觉特性定义了一个新的色彩空间XYB以及基于该色彩空间定义了一套自己的图像质量评价标准(IQA)Butteraugli。
Guetzli的压缩过程可以简单描述为两个阶段:阶段一,使用质量越来越低的量化表依次对原始JPEG重新量化编码,重编码的结果转化到XYB色彩空间并使用Butteraugli进行评价;阶段二,根据Butteraugli定义的图像质量评价标准,把标准所认为不重要的细节信息进行丢弃。这是一个不停迭代的过程,很像互联网产品的开发节奏,有一个小的想法,快速验证之后再回炉重造。通过不同数据集来源的测试,在同SSIM条件下,Guetzli与普通JPEG相比,可以带来大概0%~8%的带宽节省,与butteraugli条件下号称29%的节省相比,有着明显的缩水。
Guetzli在图像压缩领域的作用可以类比为初代小米之于手机市场,网易严选之于电商市场,傻瓜相机之于相机市场。“抛开庞杂的选项,快速给你一个还不算坏的选择”这就是Guetzli存在的意义。业务方经常遇到的难题其实是想在图像存储上节省存储费用和带宽费用,但是伴随而来的是众多图像压缩的参数选择困难,这对非专业人士来说会带来很大的困扰。这时候Guetzli站出来说,“你不用管这些了,给我一张图,我可以还给你一个虽然不算特别好,但是还不错的结果”,就问你用不用?
其他图片压缩格式
JPEG是九十年代制定的图片压缩格式,面对越来越大的图片和带宽压力,JPEG压缩越来越难以满足使用要求。因此,WebP和HEVC等压缩格式应运而生。其中WebP是Google在2010年发布的一种新型图片格式,其是基于视频编码标准VP8,支持无损和有损压缩。在有损压缩方面,同质量的WebP图片比JPEG小25-34%。
WebP相对于JPEG主要增加了预测编码,即在DCT变换之前进行预测编码,DCT变换和熵编码等和JPEG无明显差异。WebP 将图片划分为两个 8x8 色度像素宏块和一个 16x16 亮度像素宏块。在每个宏块内,编码器基于之前处理的宏块来预测冗余动作和颜色信息。通过图像关键帧运算,使用宏块中已解码的像素来绘制图像中未知部分,从而去除冗余数据,实现更高效的压缩。
而HEVC是最新一代的图片压缩格式,其基于视频编码标准H.265,比WebP有着更高的压缩率,HEVC的压缩率比WebP高31%,比JPEG高43%。HEVC与WebP的差异在于HEVC有更加灵活的宏块划分和更多种类的预测编码模式(WebP只有四种预测编码模式),常用的HEVC编码器包括HEIF、SharpP和WXAM,其中SharpP和WXAM是自研的HEVC编码器。
参考文章
JPG图片的编码与解码JS代码实现
JPG的工作原理
How JPG Works
PNG图片压缩原理解析
JPEG 图片压缩原理(一)
影像算法解析——JPEG 压缩算法
关于离散余弦变换(DCT)
从零开始手写jpeg编码器