踩内存问题分析成本较高,尤其是低概率问题困难更大。本文详细分析并还原了两个由于动态库全局符号介入机制(it’s a feature, not a bug)触发的踩内存案例。
踩内存不仅仅是调皮
进程是资源分配的最小单位,线程是cpu调度的最小单位。在同一个进程中各个线程是共用整个进程的地址空间的。
把进程的地址空间比作一张大画布,大家(各个线程)可以从这张大画布中裁剪出来一张张小画布使用,用完归还。每个人借还都在管理员那里登记好即可。同一张小画布也可以小A用完归还后小B使用。大家都遵守规则的情况下是非常和谐的。但是某一天,小A同学突然调皮了一下,在小B借用的小画布上乱涂乱画,甚至踩了个大脚印——这就是踩内存了!每一块画布除了画图区域外还有边框,小A同学如果对边框踩上几脚,归还的时候管理员也会非常无语的。
可以看到,小A的行为不仅仅是调皮了,简直是”恶劣行径”,很可能导致小B同学或者管理员同学”崩溃”大哭。
堆内存管理结构
malloc的数据结构如下图所示:
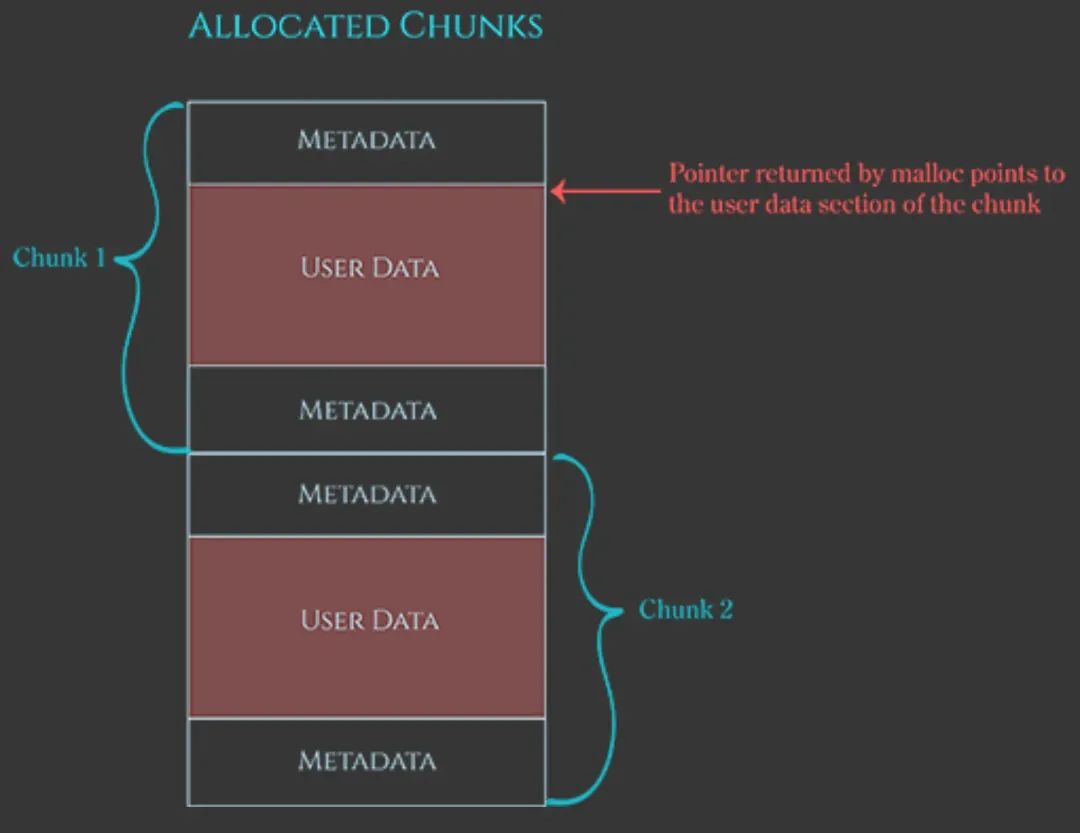
我们申请的内存前后被metadata包裹,这里的metadata就是上文说的”画布边框”,内存释放的时候libc(管理员)是会对其进行检查,如果有问题libc会主动触发abort;申请到的内存可读写区域就是上文说的”画布的画图区域”。
1.2 踩内存后果
内存越界踩踏发生后比较严重的后果可能有如下几种情况:
- 内存释放时崩溃(发生abort而不是segment fault)——画布管理员哭了
- 多次崩溃调用栈不一致(发生segmentfault),具体看谁的内存被踩了——小B或者小C等被踩的同学哭了
这两种表现主要看越界的”步子”有多大(踩到了边框还是踩到了别人)。
相关问题的分析难点在于找到作案第一现场。而通常踩内存的问题导致崩溃后生成的coredump文件只是一个最终现场,从core中看到的触发崩溃的地方并不一定是罪魁祸首。
一个小案例
崩溃栈无法分析原因
版本提测之前总是能遇到一些突发崩溃,core文件解出的backtrace如下:
1 |
|
可以看到是在析构函数中释放内存是libc检测到异常主动触发了abort。难道我们要修改相关变量的内存释放逻辑吗?显然不是。这个core只是展示了进程崩溃的案发现场,但是并没有揭示为什么会这样。
valgrind报告指认真凶
释放内存导致崩溃只是最后的案发现场,内存释放逻辑是无辜的,真正行凶者早已逍遥法外。
运气比较好,这是一个必现问题。我们可以让凶手反复出手来对其实施抓捕。针对内存问题,asan和valgrind都是一把好手。
1 | valgrind --tool=memcheck --leak-check=full --show-reachable=yes |
valgrind日志中看到:
valgrind: m_mallocfree.c:305 (get_bszB_as_is): Assertion ‘bszB_lo ==
bszB_hi’ failed.
valgrind: Heap block lo/hi size mismatch: lo = 1360, hi = 3212836864.
This is probably caused by your program erroneously writing past the
end of a heap block and corrupting heap metadata.
valgrind检查到了堆内存访问越界,并指出了发生非法内存写操作的地方–”Invalid
write of size 8”,相关问题出在xxx_define.h:380中的reset函数。
==92== Invalid write of size 8
==92== at 0x50F317C: reset (xxx_define.h:380)
==92== by 0x50F317C: xxxInfo (xxx_define.h:299)
==92== by 0x50F317C: xxx::xxx::xxxData() (xxxDefineBase.cpp:4)
==92== by 0x6089286: ??? (in /root/workspace/test/sdk/xxxResim/libxxxSimulater.so)
==92== by 0x400F8F2: _dl_init (in /usr/lib64/ld-2.17.so)
==92== by 0x4001159: ??? (in /usr/lib64/ld-2.17.so)
==92== by 0x2: ???
这里对struct xxxInfo的各个成员变量进行赋值操作导致了内存非法写入。
问题修复
进一步确认是因为回放工具(A.so)与定位模块(B.so)共用了相同的结构体定义,但是头文件却是各自维护一份,本次新需求定位模块在结构体中新增了字段,但是回放工具使用的结构体中未新增。
既然是两者代码不一致导致问题,我们只需要把两个头文件代码改成一样的不就解决问题了吗?
刨根问底
代码一致性问题解决后问题修复了,如果只是为了解决一次崩溃问题到此结束的话总感觉少了点什么。因为我们心中的疑问还没有解决——到底为什么会越界呢?
凶手找到了,但是他的动机是什么?又是什么让他产生了这样的动机?如果这些疑问不搞清楚的话我们只能结案一起凶杀案件,无法彻底解决其背后反映的社会问题。
深入分析
疑点重重
为什么valgrind的调用栈里显示的行号那么奇怪?明明是回放工具的库里面出的问题,但是行号看着更像是定位库最新代码,难道回放工具调用到了定位模块的代码(两个仓是隔离的,没有依赖关系)?
回顾本次问题,回放工具越界的原因是申请了一块小内存(按照老结构体定义size),但是赋值操作时却按照新结构体定义进行赋值,导致越界。两部分代码不在一个仓里,它是怎么用上新结构体定义的函数的呢?
灵光乍现
发现这部分回放工具复制过来的代码没有增加自己的命名空间。即回放工具模块和定位模块都有自己的xxx_define.h,这里面定义了结构体xxxInfo,并且包含了它的reset函数的实现(对结构体成员变量赋默认值),在xxxInfo构造函数中调用reset函数。
看到这里,一个专有名词突然闪过——“全局符号介入“!豁然开朗。是全局符号介入导致的A.so的代码用到了B.so中的函数定义!
拨云见日
下面验证下我们的猜想:
1)两个动态库中存在相同符号定义
回放工具的so为libxxxSimulater.so,定位模块是静态库,打进了libxxxSDK.so中,查看这两个库的符号,发现他们都有xxxInfo::reset()这个函数的符号。

并且这两个都是弱符号(“W”),根据全局符号介入的原理,运行时按照动态库链接顺序查找调用函数的符号,然后加入全局符号表中,这之后的动态库中如果有相同的符号将被忽略。而动态库链接按照什么顺序则由不同的链接器内部实现,通常是广度优先遍历的顺序。
2)定位模块所在动态库先于回放工具库加载
使用ldd查看可执行程序xxxMap依赖库如下:
这里从上到下的顺序就是运行时动态库的链接顺序。但是ldd官方接口说明并没有看到类似承诺。为了明确运行时各个库的装载、链接过程,我们可以使用LD_DEBUG功能更直观得查看。相关命令如下:
1 | LD_DEBUG=files ./Map /data/ /data/short.loc |
输出如下所示:
1 | 560: file=libxxxSDK.so [0]; needed by ./Map [0] |
由此可见,可执行程序Map先链接的libxxxSDK.so,后链接的libxxxSimulater.so。
ps:
LD_DEBUG是linux的一个环境变量,通过设置它我们可以看到链接器背后的很多操作,如果我们把它设置成symbols,即LD_DEBUG=symbols,则更能直接看到链接器是怎么查找到符号定义的。
真相大白
回放工具代码中分配内存使用的是自己的结构体定义大小(sizeof是编译时行为),而运行时由于全局符号介入跑到了定位模块定义的新结构体构造函数,以及reset方法,导致堆内存越界写。
所以,真相只有一个——事件还原如下:
step1.
定位模块和回放工具代码中各自有一份自己的xxx_define.h,大家各自include自己的头文件到各自的cpp中,而include的操作其实可以翻译成复制.h内容到cpp中。相当于大家各自定义了自己模块内部的struct xxxInfo以及它的构造函数和xxxInfo::reset()方法。
step2. 回放工具使用new xxxData()操作对xxxData进行了实例化,这一步new其实做了两件事。第一件事,在堆上分配了sizeof(xxxData)大小的内存,而xxxInfo是xxxData的成员,因此对sizeof(xxxData)的大小亦有贡献,sizeof是编译时行为,因此得到的size大小为回放工具代码中定义的老的xxxInfo的size;第二件事,调用了xxxData的构造函数。
step3.
xxxData构造函数执行时会先构造它的成员变量xxxInfo,而reset就是xxxInfo的构造函数中调用的函数。程序运行时链接器找到了libxxxSDK.so中xxxInfo::reset()函数的符号并加入全局符号表中,待libSimulater.so加载时其内部的xxxInfo构造和reset方法都被忽略了(参考《程序员的自我修养——链接、装载与库》中的介绍)。因此运行时回放工具执行的是libxxxSDK.so中定义的新结构体构造函数和reset函数。由于新结构体的reset函数里额外的成员赋值导致了写入内存超过了老结构体的size,堆内存越界!
用实践来检验真理**
实践是检验真理的唯一标准,下面我们写一个小demo来印证我们的分析结论。
/* a1_def.h */
1 |
|
/* a2_def.h */
1 | struct A { |
/* b1.h */
1 | void b1(); |
/* b2.h */
1 | void b2(); |
/* b1.cpp */
1 |
|
/* b2.cpp */
1 |
|
编译动态库:
1 | g++ -fPIC -shared b1.cpp -o b1.so |
/* main.cpp */
1 |
|
生成可执行程序,先链接b1.so:g++ main.cpp b1.so b2.so -o main_b1_first_link
生成可执行程序,先链接b2.so: g++ main.cpp b2.so b1.so -o main_b2_first_link
执行结果如下:
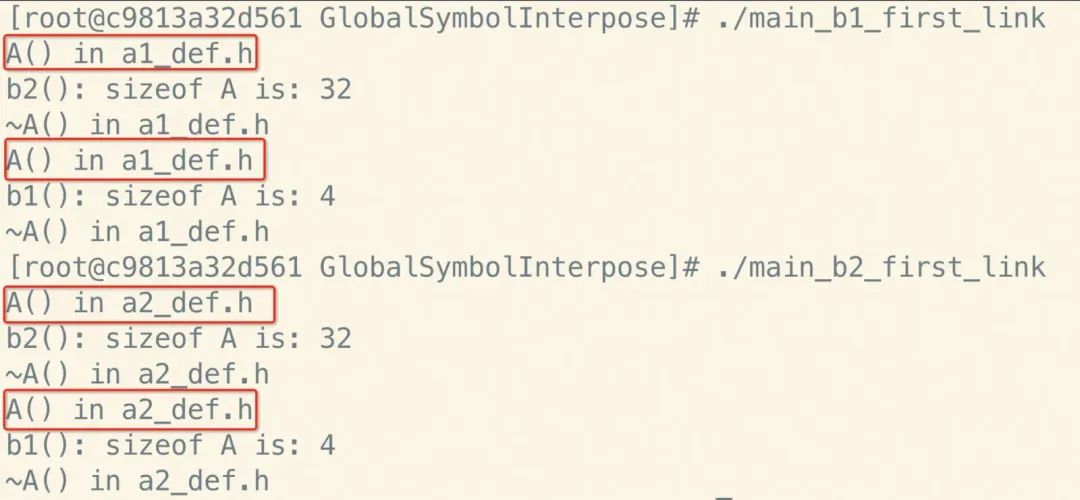
可以看到,当先链接b1.so时,函数b1() b2()中调用的都是a1_def.h中定义的struct
A的构造函数;当先链接b2.so时变成了调用的都是a2_def.h中定义的struct
A的构造函数。但是函数b1() b2()中的sizeof是编译时处理的,与链接无关,得到的都是各自include到的struct A的size,与动态库链接顺序无关。
至此,印证了本次的问题分析:malloc时使用sizeof得到的size分配了较小的内存,但是运行时使用的却是新定义的大结构体构造函数,导致内存越界写。
似曾相识
多数情况下,我们不会故意做类似上文这种相同代码拷贝两处的事情,或者说上述问题我们可以通过”小心”、”谨慎”来避免。但是有些时候类似问题却还是能在不经意间发生。
最近商用客户上报了一例全局符号介入导致的踩内存问题,但是其触发原因更加隐晦。
熟悉的配方–奇怪的崩溃栈
客户反馈新增模块加载后发生崩溃,崩溃栈很奇怪,在一堆客户模块调用流程中夹杂了一行高德动态库中STL模板类的调用。且最终崩溃的位置没有道理,怀疑发生踩内存。
一样的味道–全局符号介入
本次崩溃backtrace中,客户代码没有调用高德的API,但是backtrace中却出现了高德库中的stl模板类函数符号。有了第一个案例背景,我们自然会想到全局符号介入的原因,所以这个backtrace并不奇怪(it’s a feature, not a bug),但是问题是它发生了崩溃!
又一次真相大白
我们和客户共用相同版本的gcc编译工具链,各自对stl模板类的使用都是通过include头文件的方式完成的。大家include了一样的代码,那么即使出现全局符号介入,最终用哪个库的符号应该都是一样的才对。既然源码和工具链都一致,那么最终导致不一致的只有编译参数了。经排查,我们的编译参数跟客户的果然不一致!其中最危险的就是我们使用了-fshort-wchar而客户未使用。这将导致我们编译的代码中wchar_t类型大小是2字节,客户的代码中是4字节!进而导致发生踩内存,引发不可思议的崩溃。
show me the code
如下是最近客户上报问题的等价demo代码。
1 | void funcA(); |
1 |
|
将A.cpp编译成A.so(高德提供)。
1 | g++ -fPIC -std=c++11 -fshort-wchar -shared -g A.cpp -o A.so |
注意,此处编译参数添加了**-fshort-wchar**这会把wchar_t类型的size变成2字节,即funcA中打印的sizeof(wchar_t) = 2。
1 | void funcB(); |
1 |
|
编译B.so(客户内部模块):
1 | g++ -fPIC -std=c++11 -shared -g B.cpp -o B.so |
注意B.so编译时未使用-fshort-wchar。
由于stl中有很多模板类(本demo以vector为例),源文件中include相关模板类头文件后会将相关代码编译到当前so中,我们查看A.so中vector相关符号。
1 | [root@4bad734105ec stl_template_demo]# nm A.so |grep vector |
使用c++filt翻译一下,这些被修饰的符号。
1 | [root@4bad734105ec stl_template_demo]# c++filt _ZNKSt6vectorIwSaIwEE4sizeEv |
发现这些正是我们demo源码中用到的vector相关函数:vector
注意nm的结果中显示,这些符号类型都是”W”,即弱符号(Weak),说明相关符号定义在A.so中存在一份,但是是否会真正使用要看链接结果,最终全局只会指定一份生效。同理,B.so中也存在一组vector相关的弱符号的定义。
接着看调用方代码(客户集成可执行程序)。
1 |
|
我们调整链接顺序,生成两个demo可执行程序。
1 | // 先链接A.so |
ldd查看链接顺序,如下图:

有了上文的基础,我们可以预测,如果可执行程序先链接A.so,那么funcB()中vector相关的符号使用的就是A.so的了,我们可以通过gdb更清晰的明确这个结论。
1 | Starting program: /root/workspace/test/stl_template_demo/main_A_link_first |
在单步调试中我们使用info symbol查看pc对应符号位置,果然B.so中的funcB中使用的vector构造函数来自A.so的代码段。
1 | (gdb) i symbol 0x7f312b8f62f8 |
可是别忘了,A.so和B.so的编译参数不一致!!A.so中的wchar_t是2字节,B.so的wchar_t类型是4字节呀!!
1 | [root@4bad734105ec stl_template_demo]# ./main_A_link_first |
这就会导致引发踩内存问题。例如,分配的内存小,但是写数据是偏移的size大(这就与案例一类似了),导致踩坏到了别人的内存,触发崩溃。
整理回顾
本示例中,A.so来自高德团队,B.so和可执行程序由客户完成。A.so中的对外接口void funcA();非常简单,但是却不经意间额外导出了stl相关的符号,导致客户so中的符号被我们替换,而更为致命的是两个团队编译参数不一致导致wchar_t类型的size不一致,进而引发踩内存的稳定性问题。
该案例暴露了两个问题:
- 我们的SDK额外导出了一些符号,更好的做法应该是使用编译参数-fvisibility=hidden默认隐藏所有符号,只针对性导出对外接口符号。
- 同一个进程中的多方提供的动态库编译参数不一致。
针对本案例,拉齐多方编译参数是最佳解决方案。
默认隐藏其他符号是解决不了问题的,因为我们对外导出的接口可能也会使用stl模板类,例如void funcX(vector<wchar_t> data);但这并不是我们不使用-fvisibility=hidden的理由。
小结&感悟
踩内存问题分析成本较高,尤其是低概率问题困难更大。本文详细分析并还原了两个由于动态库全局符号介入机制(it’s a feature, not a bug)触发的踩内存案例。
之前老说不同库定义相同符号危害如何如何,这次看到了活生生的例子。以前看书的时候对全局符号介入、运行时绑定等装载、链接的各种概念没啥感觉,这次的案例真是书本知识的完美应用。问题想明白本质后感觉真是酣畅淋漓!
写在最后:
- 不一致,是万恶之源。
- 工程标准化,是解放生产力的良方。