[转载] JIT真的比解释执行快么——关于JS引擎的一些热门话题
在编程语言的世界中,如何高效地执行代码一直是一个热门话题。随着脚本语言的普及和性能需求的提升,解释执行和即时编译(JIT)成为了两种常见的代码执行方式。本文探讨了这两种技术,通过详细的实例和深入的分析,为我们揭示了它们的工作原理、性能差异以及各自的优缺点。
希望这篇文章能够帮助你更好地理解编程语言执行的技术世界,激发你对高效代码执行的深入思考,并在实践中应用这些宝贵的知识。
什么是JIT和解释执行
要解释什么是JIT,什么是解释执行,我们来看一个简单的例子,就很好理解了:

对于一个语言,一定有一套规定好的行为。执行这个语言编写的程序,就是按照规定好的行为一行一行逐步生效的过程。C语言有这样一套规定,比如 a=b+c; 就代表了:
- 取出变量b内存中的数字
- 取出变量c内存中的数字
- 相加
- 结果放到变量a里
C语言的”规定”本身比较简单,由于强类型,其行为上也贴近机器码的行为。我们通过编译把C代码转换成机器码后,汇编代码和C代码之间的对应关系还是比较清晰的。
但是对于一些更加现代的脚本语言来说,规定就很复杂了。同样以 a = b + c 举例,在JS中,规定可能是这样的:
- 取出变量b内存中的数字
- 变量b是一个闭包, 那么要xxxx
- 变量b如果是一个局部变量, 那么要xxxx
- 变量b如果是一个全局变量, 那么要xxxx
- 变量b如果不存在, 那么要xxxx
- ….
- 取出变量c内存中的数字
- …. (同上)
- 相加
- 相加的值如果都是数字类型, 那么xxxx
- 相加的值如果都是字符串类型,那么xxxxx
- 相加的值如果是xxxxx, 那么xxxxx
- ….
- (如果相加过程抛出了异常)
- 如果异常有catch block, 那么xxxxx
- 如果异常没有catch block,那么xxxxx
- 结果放到变量a里
- 变量b是一个闭包, 那么要xxxx
- 变量b如果是一个局部变量, 那么要xxxx
- 变量b如果是一个全局变量, 那么要xxxx
- 变量b如果不存在, 那么要xxxx
- ….
可以看到,对于复杂的动态类型语言,行为的规定也变得异常复杂。具体到JS的规范中,JS语言的行为定义是多层次的,部分常见的”原子行为”被抽象成了规范中的一个条目:

比如上图的 ToInt16 行为,按照规范有1,2,3,4,5多个步骤,步骤中又会用到一些其他步骤,比如 ToNumber。
自然而然的,我们可以想到,把这些规范中的行为变成一个个函数,规范中行为的步骤就变成了函数的一行行代码,然后函数和函数之间的调用就可以实现这么复杂的语言规范组织了。我们把这些逻辑叫做步骤函数
那么回到最初的问题,什么是解释执行,什么是JIT呢?从上面步骤函数 的概念来理解:
- 解释执行: 把JS脚本转换成一个步骤函数数组存到内存里,然后执行时写一个大的while循环,把步骤函数的地址取出来,然后调用这个函数指针。
1
2
3
4
5
6
7
8Func array[] = {doVarGet, doVarGet, doAdd, doVarPut }
void interpretor(VM* vm) {
while(*array) { // 一步步执行所有步骤
(*array)(vm); // 执行当前步骤
array++; // 准备执行下一个步骤
}
} - JIT: 把一个个步骤函数的调用转换成机器码,不用软件的while来驱动,可以理解成这样的C代码
1
2
3
4
5
6void jit(VM* vm) {
doVarGet(vm);
doVarGet(vm);
doAdd(vm);
doVarPut(vm);
}
从上面的概念上看来不管怎么样都应该是JIT的方式比解释执行的方式快,那么为什么还存在解释执行这种方式呢?有以下几个原因:
JIT生成的代码体积会比 array 数组(在真实情况下一般是字节码)大很多,内存消耗太大。
JIT需要运行时支持将内存页的权限标记为 "executable" 的,这在一些系统上是做不到的:比如iOS和鸿蒙出于安全原因禁止这种行为
对于 步骤函数 比较复杂的语言,while循环往下走一个循环的开销可能比起 doVarGet 来说是微不足道的,这样 JIT 比解释执行也快不了多少,甚至由于过大的可执行内存段,会经常造成 L1 Cache miss拖慢整体执行。这点下文会看到一个通过CPython实现Baseline JIT的例子。
另外,JIT(Just-In-Time) 是和 AOT (Ahead-Of-Time) 相对应的概念。这种从JS源码转换成机器码的过程是在运行时动态进行的,而不是像C语言一样预编译好的。对于很多只要执行一次的代码,进行JIT编译的开销加上执行JIT后代码的耗时,可能比直接用解释执行执行这些代码的要慢。
解释执行为什么慢
从上一节我们已经理解了什么是JIT,但是我们经常听到一个”热门话题”:脚本语言的执行很慢。知其然知其所以然,我们这里要讲一下解释执行到底慢在哪里。
首先这里所说的解释执行一般是指动态类型的脚本语言,正如前一节所说的,动态类型的语言由于其类型的动态性,对于同一个”步骤函数”,在运行时要做大量的if else来处理不同类型的情况。另外由于解释执行对于Interpretor函数来说,while循环中下一次取出来的字节码是不是提前可知的,也就是这时候的对应的机器码中的 br 跳转指令,后面跟的地址是一个动态的地址。这些特点产生了如下问题:
if else和br指令都会造成CPU流水线失效,不能有效的利用指令并行的能力。- 解释执行器中所有其他的逻辑都可以优化到和JIT差不多的水平,但唯独流水线失效的问题是根植于其原理上的,这点是解释执行慢的本质。
JIT到底能多快
当我们认识到解释执行为什么慢以后,自然而然走到了我们的第二个”热门话题”: “JIT真的超快的呢=w=”。知其然知其所以然,我们这里要讲一下JIT执行到底快在哪里。
首先不同于很多人先入为主的认识的是,Java 代码其实也是先解释执行的。Java 的 Class 文件其实就是Java的字节码,在JVM中,class文件会先以解释执行的方式进行执行。然后JVM在发现了一些热点函数之后,会对热点函数进行JIT编译来加速性能。众所周知JVM经常自己去和C++比较性能,然后说自己”甚至有时候比C++性能还好”。刨去其中王婆卖瓜的部分,其实JIT真的在一定条件下可以做到比肩甚至超过静态编译语言的性能的。但这是有一些前提的:
- JIT的语言本身要有静态的类型信息,不然翻译出来的代码又要有很多的
if else类型判断,拖慢产物的执行性能。 - JIT的设计上要能进行和静态编译类似的各类分析优化,比如公共子表达式擦除,数据依赖分析,数据逃逸分析等等。
- VM的设计上要能很好的收集运行时的数据,来决定什么是热点,决定那些函数JIT化,哪些函数在JIT中inline等等。
所以其实做好一个高性能的JIT语言引擎,其难度不亚于实现一套llvm。如果没有体感的话我来举个JIT实际实现方式的例子:
比如Java/JS这样的语言是支持NullPointerException的,遇到a.b中a是null/undefined 的情况,是可以在当场抛出Exception中断执行流程,然后外面可以通过catch这个Exception来防止整个程序崩溃的。
但是对于C/汇编来说,访问一个空指针对象的字段时,是会直接触发sigfault信号造成程序崩溃的。那么我们怎么在JIT的代码中实现Exception呢?
对于解释执行来说,”步骤函数”: GetProperty中会增加一个if判断来专门处理这种情况。但是对于生成jit代码呢?难道也每个属性访问前面都if else?那不是和解释执行一样慢了么?
对于V8/JVM来说,他的实现方式是:
- JIT代码中不生成空指针检查的代码,让他触发sigfault
- 引擎监听linux系统的sigfault信号,然后根据信号触发时的地址偏移位置,反向推断出当前是哪一行代码出现了问题,出现了什么问题。
- 根据(2)中的计算结果,进行 de-optimize, 也就是重新回到解释执行模式中,让解释执行来触发
Exception并处理。
那么怎么知道回到解释执行中的哪一个代码位置,回到这个位置有多少函数的状态是需要还原的,其中要有非常复杂的逻辑要处理。大概的类比就是实现一套 dwarf 功能 (C代码编译的调试符号文件)。
那么V8这种在JS这种动态语言上做JIT的引擎,其实比Java做JIT会更加困难,因为Java的输入起码是固定类型的,数字类型的 b+c 真的可以生成对应的机器码来执行。V8的想要做到类似的效果,需要在运行时动态地去收集运行时类型信息,比如一个函数中的 b+c 一直都是数字类型的,那么他可能就假设这个函数大概率是数字类型的,然后按照数字类型去生成一段JIT。后续在使用的时候要检查前置条件(b和c都是数字类型) 来决定是否可以使用这段JIT代码。
至此我们可以看到,JIT真的是可以做到非常快的执行的,在一些特定类型固定的函数上甚至可以生成和
C 代码编译结果一样质量的JIT函数的。但是其中 VM 要做到工作是非常非常复杂的。不妨看一下业界已有的一些带有JIT功能的语言引擎:
- Java/C#: Oracle和微软维护
- PHP: 社区版本没有JIT,Facebook自己做了一个带JIT的版本维护。
- V8/JSC: 谷歌和苹果维护
然后我们再看一下一些社区维护的语言:
- Python: 官方的CPython至今没有一个完善的JIT实现。PyPy可以实现JIT但是工业实践上很少使用。
- Lua: 官方不包含JIT。LuaJIT版本是一个大佬自己维护的,而且已经不再更新Lua最新版本的支持了。
V8的弯路
在V8刚推出的一段时间里,其实是走过一段时间设计上的弯路的,V8团队认为JIT编译应该是JS引擎的一级公民,所以默认把所有的JS代码都做了JIT baseline的编译,然后在挑选其中的热点函数做更高层次的优化编译。然后对比一下隔壁Safari的JavaScriptCore引擎,发现是”benchmark没输过,实际效果没赢过”。在实际打开网页的时候响应速度反而不及JIT做的没那么好的JSC引擎。这是由于JIT本身的启动开销是比较高的,对于网页的首屏正向影响不如编译带来的额外开销大。
所以在现代的V8上,解释执行已经重新成为了执行的第一级方案。
WASM为什么快
WASM的前身是Firefox开发的 asm.js技术。asm.js 技术的思路很有意思,不妨在这里讲一下。
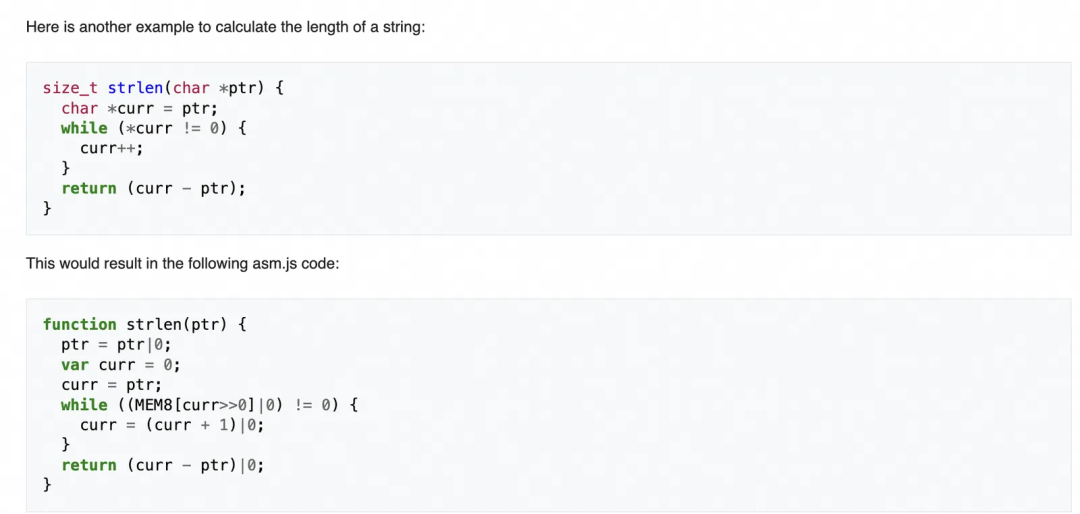
可以看上面的这个例子,这是一个C代码通过asm.js编译器变成JS代码的例子,大家可以看到在这个JS产物里多了很多 |0 这样的奇怪代码,这其实是给JS引擎的JIT一个提示,代表了 (curr+1)|0 的结果一定是 数字类型。当JS引擎在一个确定的类型下进行JIT编译时,JIT产物的确定性和效率会好很多。这点也符合我们之前JIT的部分讲的,动态类型语言的JIT要在运行时收集类型信息,但是如果类型信息能在语法解析时就确定下来,那么对于JIT编译是一个极大的利好。
asm.js 产生以后,创造了一些在当年看起来仿佛神迹一般的效果,比如把 3D 游戏引擎在浏览器上高效的运行起来。顺着这个思路,几家浏览厂商说,既然要让JIT做得舒服,干嘛要JS进来插一脚,我们搞一个强类型的中间语言是不是比用JS更高效?
于是WASM诞生了。WASM提供了一个带有类型的IR,让C或其他静态编译的语言来生成。然后V8这种引擎可以利用IR进行高效快速的JIT编译,来获得接近C静态编译的运行时性能。
但是如果只是解释执行WASM代码,其效果就不会像JIT后一样对比JS有数量级的差异了。
WASM真的快么
这引出了我们的第三个热门话题: WASM真的快么?答案是确定也是否定的:
- 对于可以都做JIT的场景,
WASM不一定能比JS快很多,必然JS在JIT做得够好的时候也可以很接近静态编译的效果。 - 但是WASM想要把JIT做好比JS要容易太多了。就拿
de-optimize的事情来说,WASM里空指针是真的可以让WASM引擎进入不可恢复的状态的。这比起JS还要还原代码位置做退优化不知道简单了多少倍。 - 对于都不可做
JIT的场景,WASM比JS快一点但不多。大家都是解释执行,不会有太大本质性差别。 - 对于WASM要嵌入到JS里,还要通过JS来访问各种外部API时,WASM和JS之间的通信成本甚至会导致严重的性能瓶颈。
那么 WASM 如果没有快很多,那么他真正的价值到底是什么?其实 WASM 最核心的不是一个面向性能的接近方案,他的最大贡献在于让以前很多C的代码可以不怎么改动就跑到浏览器上。这就极大扩展了浏览器的功能边界。
JIT实现例子
CPython的JIT实现例子
在2023年年末的时候,CPython的社区版本得到了一个JIT的提交,实现了一种基于copy-and-patch技术的JIT实现,这种JIT的实现很类似我们前面举例的这种例子:
1 | void jit(VM* vm) { |
也就是说,他本质上还是把一段段的步骤函数组装起来,并没有在其中做更进一步的分析优化。所以在这个提交中作者自己也提到,现在的性能表现没有非常大的正向作用:

这里我不太同意他说这是后续一系列优化的基础。copy-and-patch这种方式丢失了比较多的结构信息,做各种分析类的优化时不太适用。但是一个开始总是好的。
LuaJIT的实现例子
LuaJIT的实现中包含了一个典型的动态语言引擎做JIT所需要的各类手段,可以从作者的这封邮件中看到
LuaJIT相比起CPython copy-and-patch的JIT实现明显正规的多。包含了IR,优化,退优化,寄存器分配等关键概念。想要自己实现JIT,LuaJIT应该是一个合适的参考对象。
解释执行真的慢么
有趣的是LuaJIT的作者写过另一个邮件,探讨了关于解释器为什么需要用汇编去编写:

如果我们去看V8 和 JSC的解释器,会发现他们利用了很复杂的汇编&代码生成机制来生成自己的解释器。其中的原因和上面邮件中提到的应该是很一致的:
- 现代编译器是为 “普通”的软件设计的,不能很好的处理 Interpretor这种特殊软件。具体表现在:
- 不能很好的分配寄存器。
- 不能很好的区分解释器中的fast-path 和 slow-path。造成流水线失效。
这篇JSC关于为什么要设计 “Low-Level Interpreter” 的文章中,也提到了类似的观点.
使用汇编代码维护解释器确实可以带来最优的执行效率,使得JSC这种JS引擎即使在没有JIT接入的情况下,解释器效率也是QuickJS的20%以上。但是引入汇编又会带来很大的维护性难题。后续的改造都会受到影响。那么有没有在保留C语言和编译器的前提下,实现一个也”差不多好”的解释器的方式呢?
我在研究CPython的copy-and-patch的文章过程中发现,这里有两篇文章描述了一种使用尾递归实现解析器来精确控制寄存器分配的方式。
- https://blog.reverberate.org/2021/04/21/musttail-efficient-interpreters.html
- https://github.com/wasm3/wasm3/blob/main/docs/Interpreter.md#m3-massey-meta-machine
总结来说很简单:
- 根据calling-convention,函数的参数总是会使用寄存器。这确保了寄存器分配的确定性。
- 编译器的尾递归优化会重用当前栈,使得尾递归调用的执行效果就是进行了一次没有sp操作的跳转。这模拟了解释器的while-switch循环行为。
- clang高版本的 [must-tail] 标记可以强制使用尾递归来优化,确保了编译产物的确定性。
利用这种手段,我们可以进一步提高解释器的效率。附加上诸如inline-cache,跳转地址内置,减少解释执行中的函数调用,增加各种fast-path的指令等方式,不失为一种优化解释执行器的好方案。
端上业务是否需要JIT
看你的业务类型,如果要在客户端上运行普通的页面,那么有没有JIT对性能影响并不大。这点从我们之前的benchmark上,以及业务的实际测试结果上都能确定。JS代码的执行速度对于首屏时间影响并没有那么大。
但是如果你的业务类型是执行一些复杂计算的,比如 three.js,比如一些矩阵计算代码,那么有 JIT 和没 JIT的差别就很大了。此时最好还是选用支持JIT的引擎。
扩展
扩展1:动态语言是否可以AOT
还记得我们最开始文章中说的V8的弯路么,在没有运行时信息收集的情况下对动态类型语言做全编译,效果并不好。编译的产物会非常大,而且效率上相比解释执行没有大的提升(类似于CPython的copy-and-patch JIT,可能就各位百分数的提升,反而需要付出巨大的内存代价)。
这也是为什么鸿蒙的ArkTS必须要在TS的基础上进一步做限制。因为TS的类型并不是强制的,在一个不强制类型的基础上做预编译效果会差非常多。
扩展2:多语言引擎真的可行么
另一个热门话题是能不能做一个VM来适配多种语言。不妨把已经存在的几种多语言引擎拿出来看看有什么特点。
- JVM: 在JVM上支持了Java, Kotlin, Groovy等多种语言。
- WASM: C Rust等静态编译语言都可以生成WASM。
既然上面这些多语言引擎都存在,那么是不是我们可以做一个引擎,”JJVM”,让他支持Java和JavaScript,那可真是太美好了,JavaScript真的变成 “Java”Script了。
你别说真有这种引擎 GraalVM。但是这里我们先按下不表来唱唱反调。
还记得上文提到的”步骤函数”概念么,JVM上的这些语言本质上共享了相同的”步骤函数”。他们在一些基础的原子操作上都是一样的,比如Java和Kotlin的int和Int的本质,都是JVM中对jint的使用。而WASM的”步骤函数”则是一批贴近于机器操作的指令,这也是由于静态语言门面向的目标本来就是机器码,而不管是arm64 还是x86,对于贴近硬件层面的数据处理方式都是类似的。
当”步骤函数”是相同的时候,共享一个VM的多语言就很好实现。但是如果你要实现的是Python和JS的共享引擎,他们的”步骤函数”行为上完全不一样。这时候怎么办?用更细粒度的”步骤函数”来实现各自的行为?这样性能会非常糟糕,要很多条字节码才能实现专有引擎中一条字节码做到的事情。把各自的”步骤函数”都实现一遍?那这样和把多个引擎重新实现一遍有什么区别。
那是不是这条路就走不通呢?我们来看看Graal是怎么做到”JJVM”的。
扩展3:GraalVM是怎么实现多语言引擎的
不熟悉GraalVM的同学可以看下这个介绍。这其实就是一个实验性的新的JVM,设计上具有更好的JIT能力来取代现有的JVM。但是GraalVM上有一个神奇的功能叫Truffle,他可以在JVM上实现各种动态语言比如Ruby,比如Python,比如JS。然后这些语言都可以JIT后以比肩V8这种原生引擎的效率来执行。同时又保持了和Java良好的可互操作性(毕竟运行在Java的VM上)。
那这种神奇的能力是怎么实现的, 我们刚才的介绍里不是说过 “步骤函数” 不一样不能共享实现么?
写代码中没有什么问题是加一个中间层解决不了的。
如果步骤函数不能一样,那我们在另一个层次上共享代码是不是就好了?

可以看到这个代码是使用Truffle框架在GraalVM上实现一个自制语言的方式。是不是很像 AST树,然后在 AST树上增加了求值函数?没错GraalVM实现语言的方式就是,你不需要定义自己的字节码,你只需要用Java实现AST和AST的求值方式就可以。
这时候你从远古的记忆中想起,AST求值不是性能最烂的语言实现方式么?GraalVM用这种方式怎么能做到比肩V8的性能的?
说实在最初我也想不通这个,直到我看到了这个关于Truffle介绍的PPT。


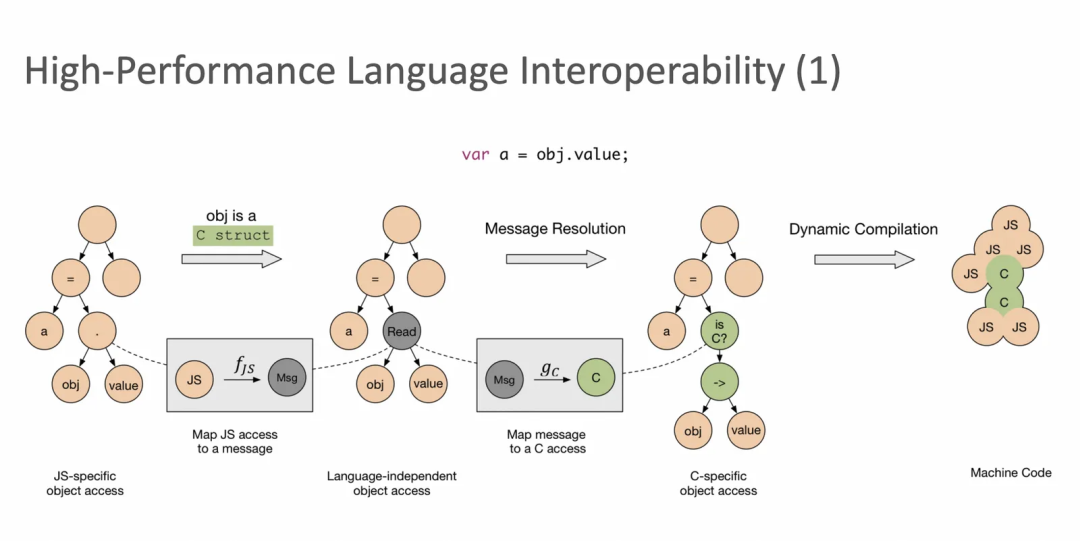
这个思路上有点难懂,但是真的搞明白了以后只感觉惊为天人。大概的意思是通过定向的JIT来不断对Truffle Node的方法做inline化(JIT/静态编译的一种常见优化手段),使得最终生成的机器代码中的逻辑被deduce到符合语言规范的最简代码。本质上来说是利用了宿主语言 JIT 来实现的动态语言生成器。
这是Oracle将近10年前发布的东西,领先程度令人惊讶。
另一个有趣的是前端时间在研究copy-and-patch的方案时候,
还发现有个大佬在研究通用语言引擎的生成器。本质上来说也是和Graal一样的方式,让用户通过编写基础块(“步骤函数”)的方式来搭建引擎,剩下的高效解释器,高效的JIT等功能,都由中间生成器生成。这和Graal的模式也很类似。
扩展4:汇编是否解决问题
看完了前面烧脑的东西,再回到我们的一些热门问题上,是不是上了汇编性能就会变好?
要看我们的汇编解决的是什么问题,现在的C编译器对于大部分的优化任务已经能做的比人还好了,要手写汇编的地方一般是要有特定的需求的,比如对 SIMD 的需求,比如对精确控制寄存器的需求。
那么这些需求到底存不存在,是要去看现有C编译产物的结果是否是最优解来确定的。如果看了编译器的结果,然后自己想不出比编译器更好的解决方案,那么用汇编就没有意义了。
抛开JIT不谈,动态语言解释器部分确实有一些可以应用汇编优化的地方。但是如上文我说的 tail-call模式的优化,其实已经可以解决绝大多数汇编需要解决的问题了,而且有更好的可维护性。那么不妨先把这部分做了再来观察编译器汇编的结果。再看有没有优化空间。