最新发布的 QQ 9 自上线以来,流畅度方面收获了众多用户好评,不少用户戏称 QQ 9 “傻快傻快”的,快到”有点不习惯了都**”**。
作为庞大量级的应用,QQ 9 从哪些方面做了哪些优化,使得用户能够明显感觉到流畅度的提升?本文将详细介绍
QQ 9 流畅背后的技术实现,以及在全流程做的性能优化探索,为应用提升流畅度提供可复用的经验。
仍有5亿人坚持用 QQ
今年是中国开启互联网时代的第 30 年,也是 QQ 作为”初代互联网产品”的第25年,手机 QQ 的第 14 年。
#仍有5亿人坚持用 QQ # ,正是有这群用户的坚持,督促着 QQ 技术团队不断的自我革新,为了能给用户更好的体验,对性能孜孜不倦的追求。
QQ 9 开始,我们从底层架构自底向上全部重构优化,解决了手机客户端原来启动缓慢、容易卡、转菊花等待时间长、UI
跳变等一系列问题。上线后,收获了用户众多好评,其中有个高频关键词是「丝滑」,在丝滑的背后,其实是技术人吹毛求疵般的打磨。
本文将为大家揭开 QQ 9 背后的技术探索,分享 QQ 匠人们硬核的优化手段。
吹毛求疵的打磨
极致秒开 — 启动速度优化
QQ 的丝滑体验从「启动优化」开始,以 iOS 端为例,启动流程主要分为 3
个阶段:
- T0:点击图标到 main 函数开始;
- T1:从 main 函数开始到 didFinishLaunchingWithOptions 结束;
- T2:didFinishLaunchingWithOptions 结束到首帧渲染完成。
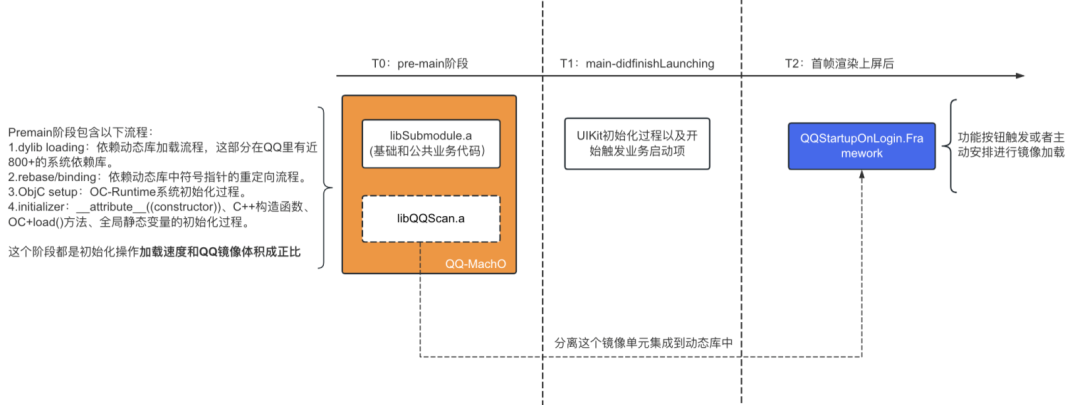
一般将启动过程按阶段分为 pre-main (T0) 和 post-main (T1 + T2)
两个执行阶段:
- pre-main 阶段:系统 dyld 加载 App 镜像和初始化行为,与程序结构和规模关系较大。
- post-main 阶段:App 在渲染上屏前做的业务初始化行为,与具体业务逻辑关系较大。
一般工程上的优化方向:
- pre-main 阶段降低加载和链接的耗时:如动态链接转为静态链接,代码拆分组成动态库并进行懒加载。
- post-main 阶段减少主线程所执行的代码总量:如代码下架,代码执行时机延后或异步子线程化,代码逻辑执行效率优化等。
以下就这两个方向,介绍一下 QQ 本次做的有亮点的地方。
pre-main 阶段 - 按需装载代码
动态库懒加载方案原理图
代码拆分组成动态库并进行懒加载这项技术多应用于业界大型 App(抖音、Facebook、快手)中,但 QQ
的业务复杂度颇高,直接使用业界方案无法满足我们的需求。经过一番探索我们找到了一些创新技术点:
- 使用 attribute((objc_runtime_visible))
- 实现低成本代码动态化改造。
使用 objc_setHook_getClass 实现动态化代码入口收敛,保证了方案稳定性。
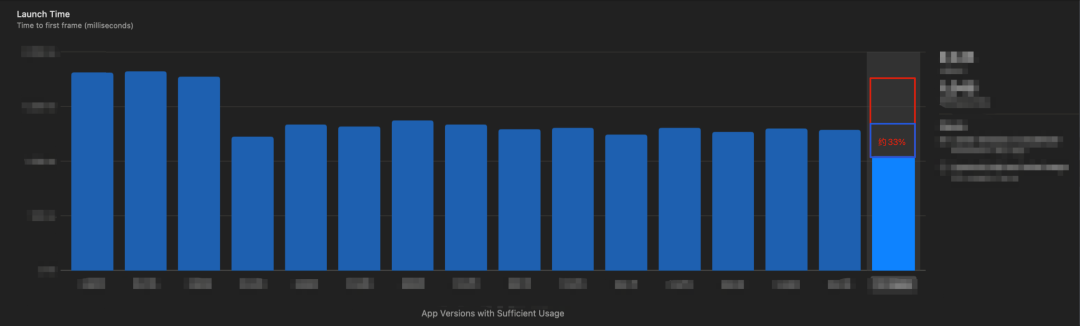
最终在 QQ 9 中大规模的应用实现了对 pre-main 阶段的启动耗时优化(这个技术方案约贡献了33%左右的启动总耗时优化数据收益):
post-main 阶段 - 线程治理
我们防劣化系统监控到主线程抢占的问题越来越严重,通过 Instruments
查看,我们发现一些严重的情况下,温启动过程中主线程有
14%的时间片处于被其他线程抢占的状态。
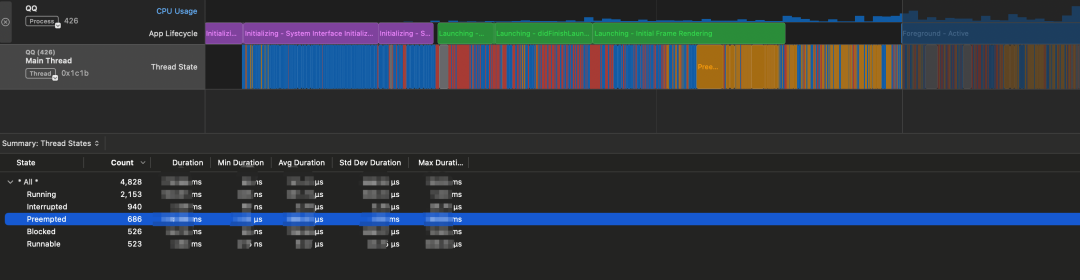
什么是主线程抢占(Preempted)问题?简单来说就是主线程的 CPU 时间片被其他线程抢占,导致主线程得不到 CPU 资源。随着抢占问题越来越严重,也引出一些相关的问题,例如启动总耗时也随着劣化、启动后卡顿、启动耗时波动大、防劣化性能报告误判概率增大等。
为什么会出现主线程被抢占?简单来说有以下几个原因:
- 系统调度行为、系统级线程(比如 PageIn 线程)抢占。
- APP 频繁开辟子线程却不注意管理子线程的数量,可能会出现「线程爆炸」的情况,而且子线程不恰当地设置 QoS,会容易导致主线程被抢占。
- 主线程任务过重,占用时间片过长,会被系统惩罚降级,然后被其他子线程抢占。
了解了原因以后,我们从以下三个方面进行治理:
减少子线程的数量
手 Q 大部分业务广泛使用 GCD,经过查找资料和研究,我们发现频繁使用 GCD
的全局队列,可能会导致线程爆炸,原因是当子线程在 sleep/wait/lock
状态时,会被 GCD
认为是非活跃的状态,当有新的任务到来时可能便会创建新的线程。

Apple 工程师、前 GCD 开发工程师发表言论
苹果官方建议不要创建大量队列,使用 target_queue 设置队列的层级结构,多个子系统就形成了一个队列的树状结构,最后队列底层使用串行队列作为 target_queue 。详情见《Modernizing Grand Central Dispatch Usage - WWDC17》
降低子线程 QoS
如果全局队列 QoS 设置为 DISPATCH_QUEUE_PRIORITY_DEFAULT ,则该任务的
QoS 将继承原来所在队列的 QoS (如果原来队列是主队列,将从 QOS_CLASS_USER_INTERACTIVE 降低为 QOS_CLASS_USER_INITIATED)。开发同学经常在主线程将任务派发到全局队列,并指定 QoS 为 DISPATCH_QUEUE_PRIORITY_DEFAULT ,这将导致存在大量子线程 QoS 为 QOS_CLASS_USER_INITIATED。以下是 QoS 优先级排序:
1 | __QOS_ENUM(qos_class, unsigned int, |
而实际开发中,很多网络请求、写磁盘 I/O,都使用了该 QoS,实际上是可以通过降低 QoS 来降低子线程的优先级。
提高主线程的优先级
QoS 并不完全等价于最终的线程优先级,主线程优先级范围为 29~47 。为什么运行过程中主线程优先级会变化?官方文档 《Mach Scheduling and Thread Interfaces》中的 “Why Did My Thread Priority Change? “ 章节解释了这个原因:如果线程的运行超出了其分配的时间而没有被阻塞,则会受到惩罚甚至被降低优先级,这么做的目的就是为了避免高优先级的线程一直抢占系统资源,导致低优先级的线程一直处于饥饿的状态。
如何避免主线程运行超出 CPU 分配时间,而免除降级惩罚?可以从 RunLoop 层面做减负。
App 启动过程开始的第一个 RunLoop,会执行持续到首屏渲染结束。而首屏的任务一般很重,导致 RunLoop 耗时很长,容易被系统降级。

QQ 启动时第一个 Runloop 耗时示意图
解决方案是对第一个 RunLoop 里的任务做拆分。我们的做法是保留必要的全局初始化逻辑在第一个 RunLoop
中,把主 UI 的创建延迟到下一个 RunLoop 里。这样不仅有效地解决了启动时主线程被抢占的情况,还能够加速启动更快看到主页面。
其实这里还有一些优化空间,我们将第一个 RunLoop 的任务都挪到第二个 RunLoop 了,就又导致第二个 RunLoop 耗时较大,可以按照此思路继续优化。
“众”享丝滑 — 性能流畅度提升
如何定义流畅?
流畅(丝滑),体感上的表现是屏幕内容跟随手指操作即时变化,每一次操作都即时地反馈在屏幕上。如图所示,未开启高刷帧率时应保证 16.67ms 内将用户操作更新至屏幕上。
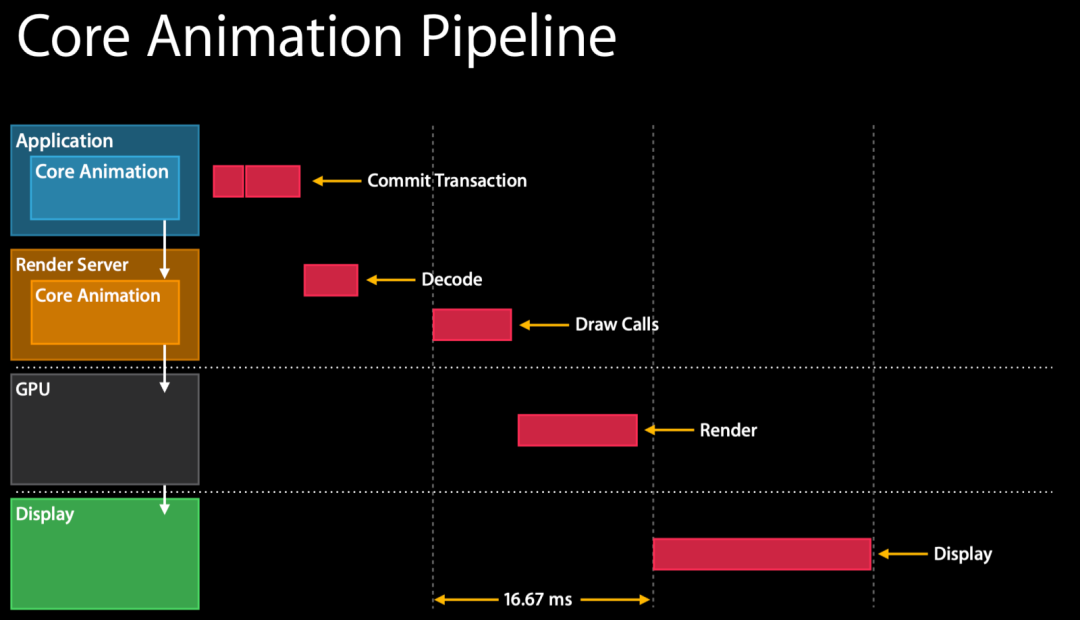
用户每个操作,都需经历图中的4个步骤,任一步骤时间过长,都会无法及时更新画面造成卡顿。来源:《Advanced Graphics and Animation Performance》
让 App 做到每 16.67 毫秒更新一次用户操作很难吗?难,难在这么短的时间内 CPU 和 GPU 需要完成很多事情,更具体的:
屏幕上显示的内容只能在主线程更新(只能单核,无法利用到手机的多核 CPU)。
影响 GPU 的耗时因素多,展示的界面越复杂耗时越多。
主线程的 16.67 毫秒 - 系统需要的耗时 = 开发者可用的时间。如下图所示,蓝色区域为开发者占用的时间,当开发者使用的时间过长即会造成 hang,即卡顿。
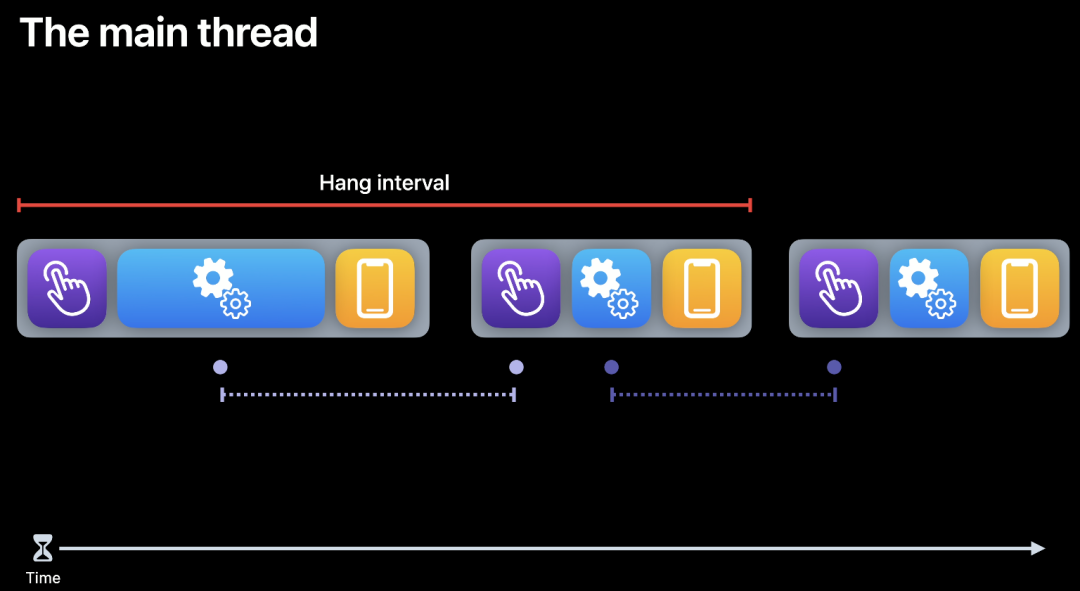
- 紫色区域:系统接受与处理用户手势操作的耗时
- 蓝色区域:开发者转换用户操作为屏幕显示内容的耗时
- 黄色区域:屏幕展示内容的耗时
来源:《Explore UI animation hitches and the render loop》
如此,想要丝滑就必须做到以下两点:
- 善用多线程编程,尽可能少在主线程上做更新 UI 以外的事情。
- 尽可能让 GPU 绘制简单的界面,减少 GPU 耗时。
善用多线程编程,尽可能少在主线程上做更新 UI 以外的事情。
NT 内核架构打好基础
QQ 9 所采用的 NT Kernel(NT:New Technology,此处向 Windows NT 内核致敬),基于尽可能发挥多核 CPU 能效的理念而诞生,如下图所示,最大程度将业务处理逻辑从负责 UI 展示的主线程中剥离,且使用异步调用代替线程锁,提升效率的同时降低死锁的可能。
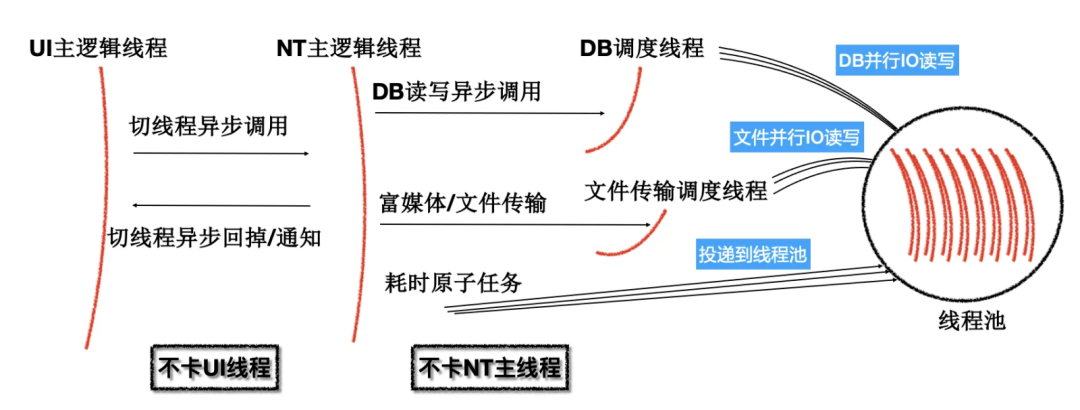
NT Kernel 多线程模型
此外,NT Kernel 采用 C++ 实现 IM 软件的核心基础能力,使其能跨平台使用,保证各平台的性能体验一致,用户交互界面则采用各平台原生语言实现。让用户感受强劲性能的同时保证了各平台特有的体验。

NT Kernel 支持多平台架构图
全量刷新改增量刷新
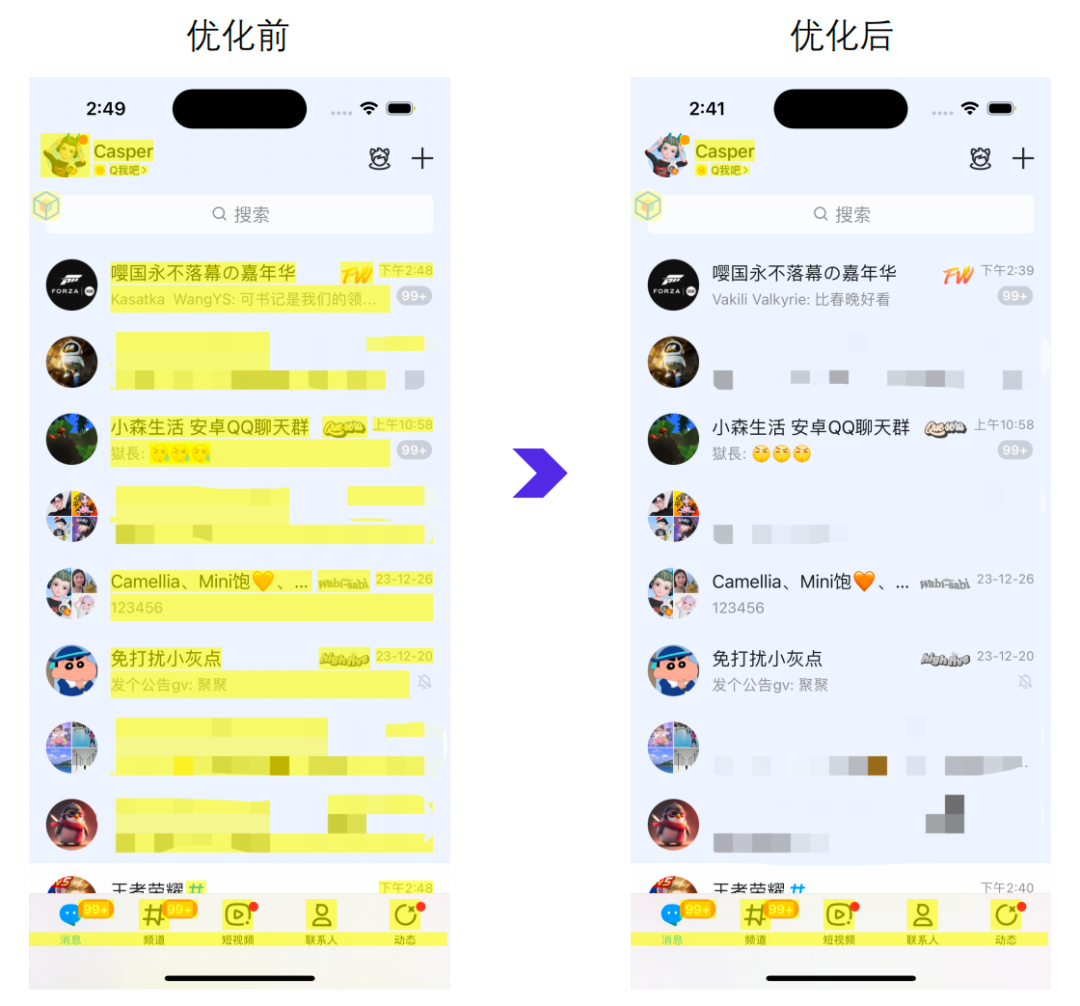
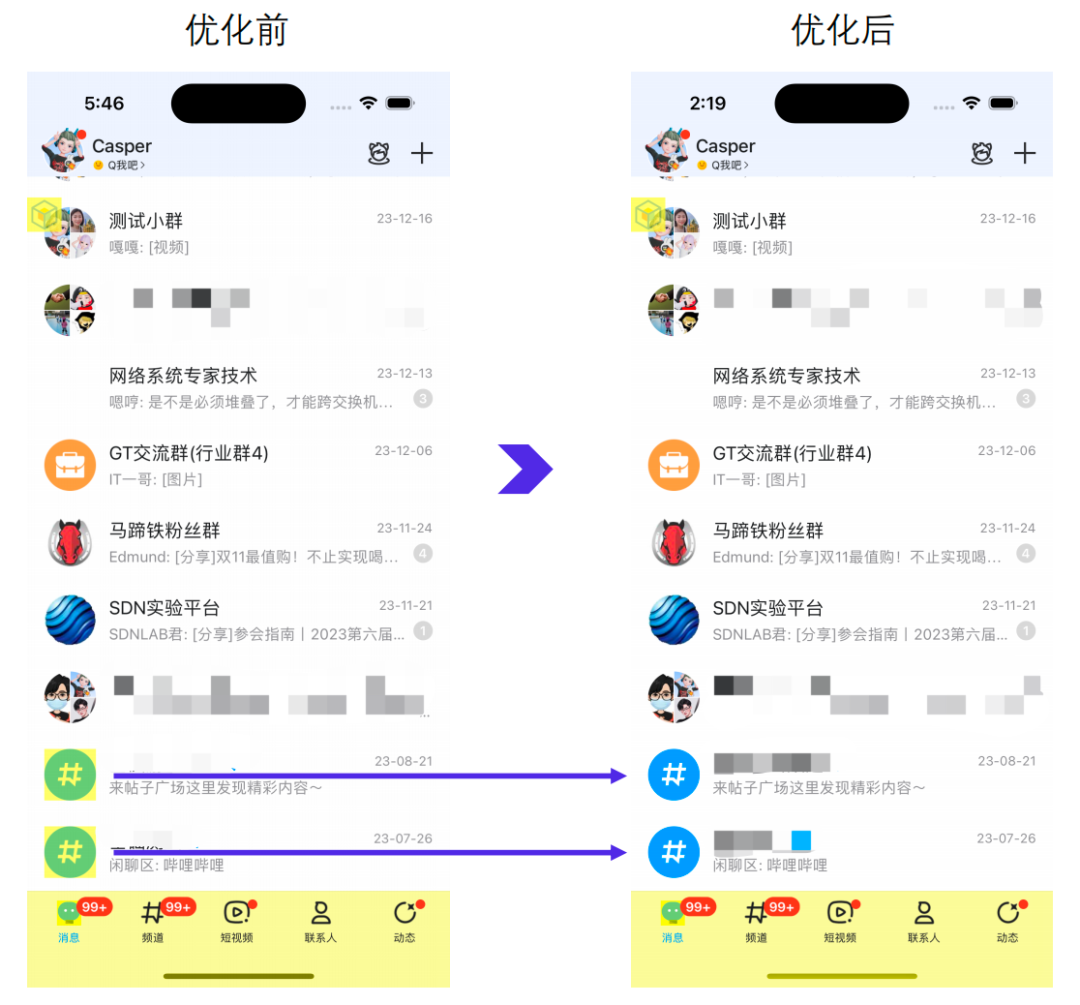
在全新 NT 内核的加持下,耗时业务逻辑都已经挪到子线程,主线程仅剩刷新 UI 的相关工作。那刷新 UI 这个事儿还有进一步优化的空间吗?答案是肯定的,14 年陈的手机 QQ 在屏幕上更新一条新消息,会将当前展示的消息全部刷新一遍,即”全量刷新”机制。滚动时无法刷新消息、资源跳变等坏体验,都是该机制导致的。
为什么滚动时无法刷新消息?并非无法刷新,而是不能刷新。多余的刷新操作很容易使得 UI 更新无法在 16.67ms 内完成,进而诱发卡顿。
为什么会出现资源跳变?全量刷新会触使屏幕上的所有节点回收、重用,并且这种重用还是无序的。如下图所示,全量刷新后节点位置会随机发生改变,例如:尾号1b400(左图第2个)的节点刷新前用于展示2,刷新则展示7(右图第7个)。
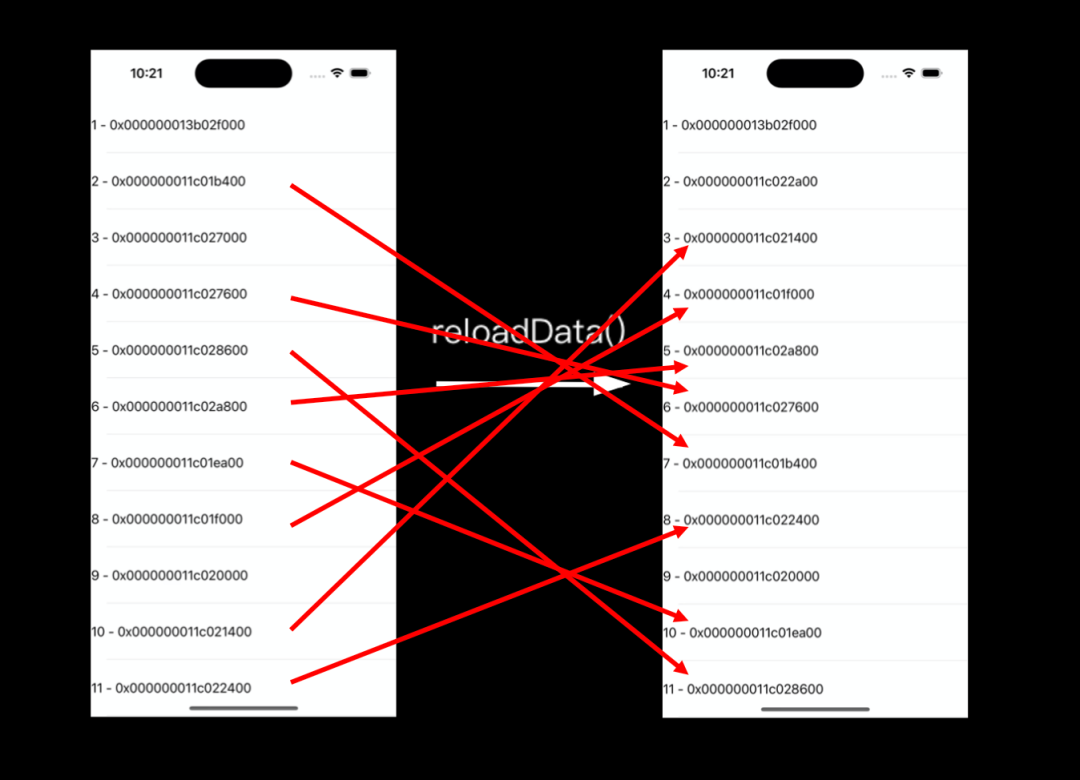
对比左右两张图的节点内存地址可见,全量刷新后会出现随机变化,并无规律可言。
无论是静态或是动态图片,都存在磁盘 I/O、解码等耗时操作,一般都会采用异步加载,避免主线程的卡顿。再叠加这种随机重用的特性,也就造成了”资源跳变”的表现。
根据不同的重用情况会有以下三种表现:
- 恰好是上次所用的节点或者内容恰好相同:相同内容赋值,没有任何变化。
- 没有相关动/静图:内容从无到有,符合预期。
- 有相关动/静图,但与当前 Model 的内容不一致:出现闪烁。如图下图所示。
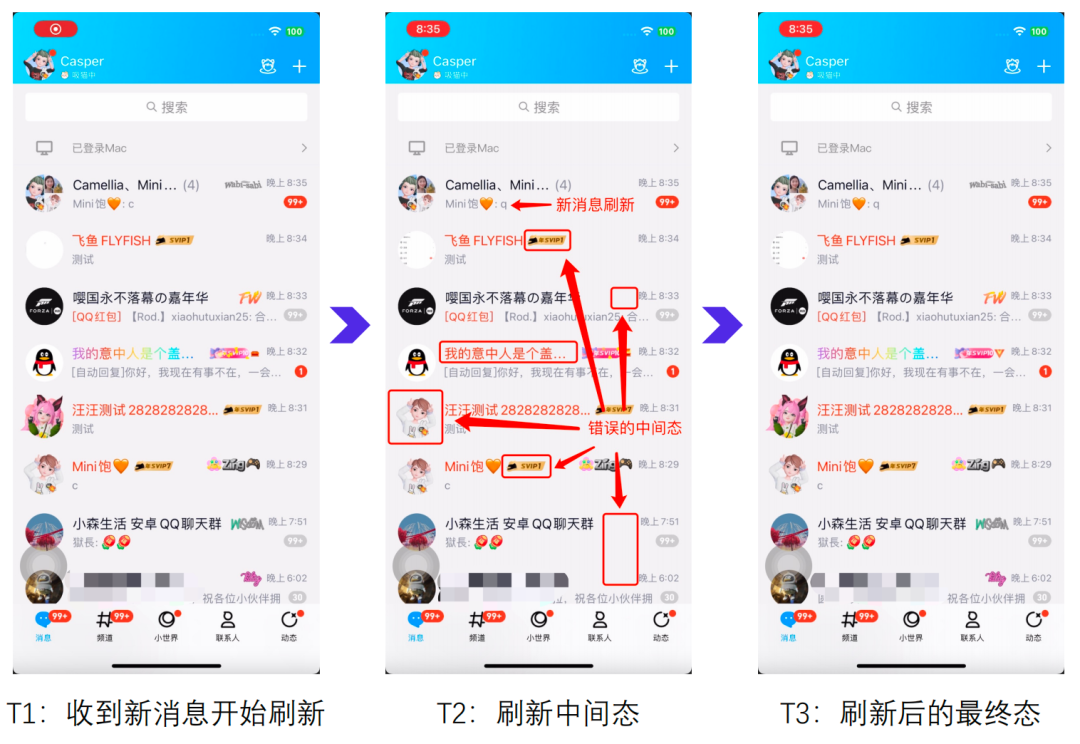
所有异步加载数据的元素搭配全量刷新,在未加载完毕前会展示其他节点的旧信息;即使刷新时重置视图也无法解决,只是从A->A->B改成A->空->B,依然存在明显的跳变。
QQ 9 采用的”增量刷新”就能很好的解决上述两个体验问题。此外,还有一个全量刷新无法实现的隐藏福利:节点动画,如下视频所示。
实现增量刷新需要有个可靠的 Diff 算法,告知系统有变化的节点是需要执行刷新、插入、删除、移动中的哪种操作,一旦给到错误的信息将会直接导致 App Cras。敲定算法过程也是一波三折。
首先,阅读源码发现 Android 与 iOS 系统内置的 Diff 工具都是采用 Myers 算法实现的。
Myers:计算结果保存在changes的数组内,其中只有insert、remove两种类型。(来源:Swift
Diffing)
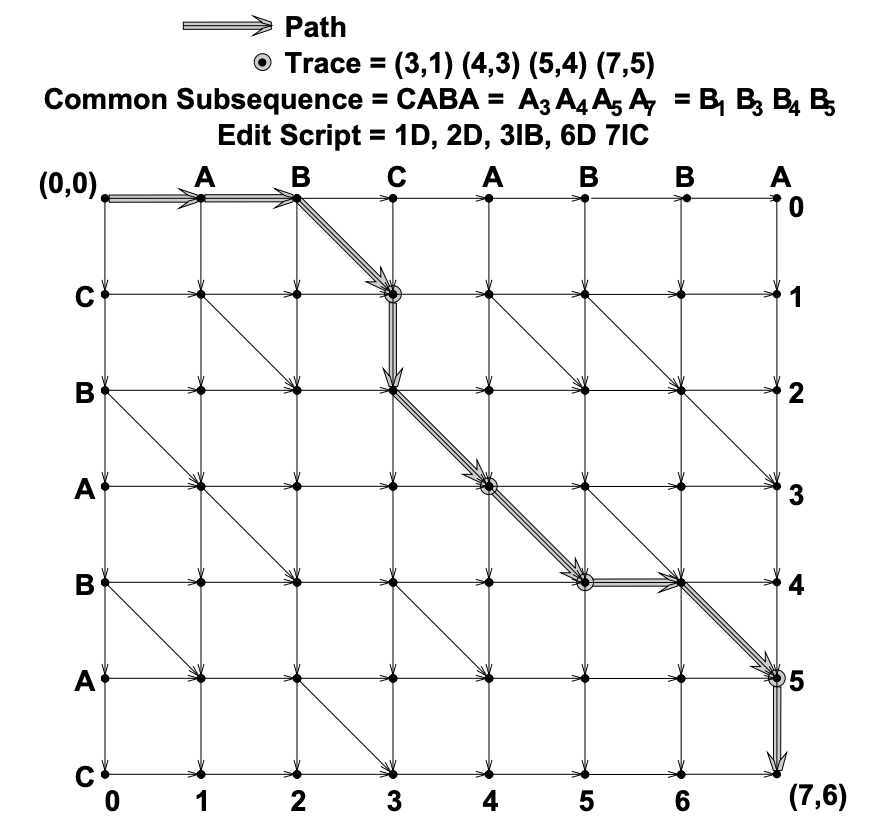
Myers算法求解过程,通过插入、删除求源到目的的最短编辑距离。来源:AnO(ND)
difference algorithm and its variations
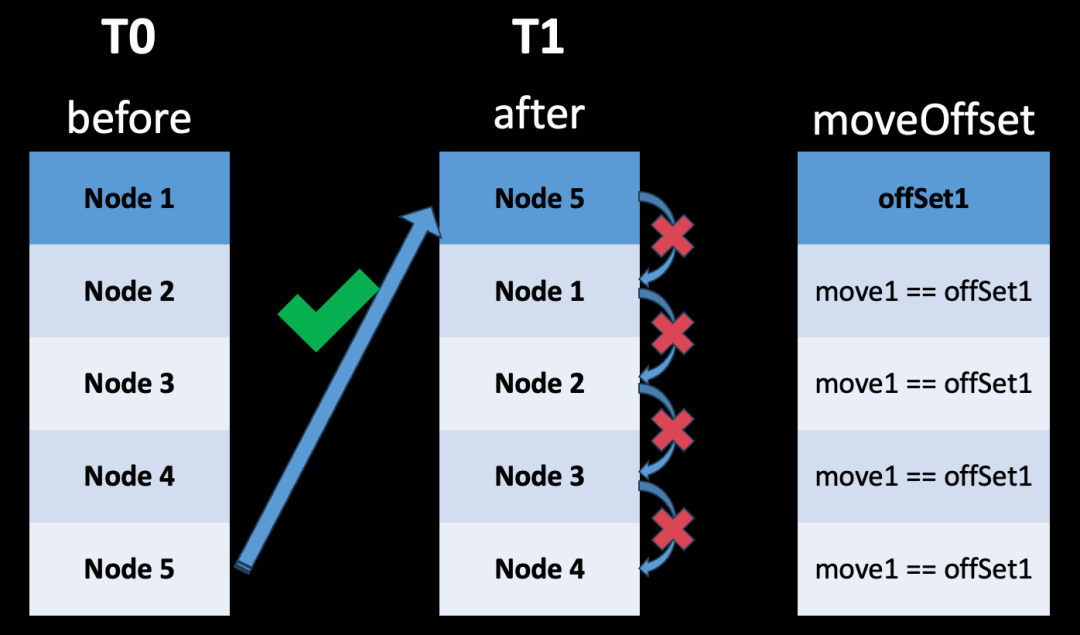
该算法在计算移动时存在”缺陷”,其通过插入+删除行为推测移动,特定场景下移动操作会降级为插入+删除。比如,先删除再移动就会转换为删除+插入,反之则是移动+删除:
- 删 + 移 → 删 + 增:
- 数据集A:[1, 2, 3, 4, 5]->数据集B:[2, 3, 5, 4]。会删除1、4,接着插入4。
- 移 + 删 → 移 + 删:
- 数据集A:[1, 2, 3, 4, 5]->数据集B:[1, 2, 4, 3]。会交换3、4,随后删除5。
经过分析,理想的 Diff 算法应该具有以下两种特质:
- 能够记录节点之间的移动关系,并不是通过插入、删除的联系推断移动。
- 具备较低的时间复杂度与空间复杂度。
对比行业方案后,选中论文《A technique for isolating differences
between files》中描述的 Heckel Diff
算法。该算法的最优、平均、最差复时间/空间复杂度均为 O(m+n),优于 Myers
算法的
O((m+n)*d)。其符号表的实现方式保证所有移动操作均被记录,不会再出现
Myers 中丢移动操作的情况,如下图所示。
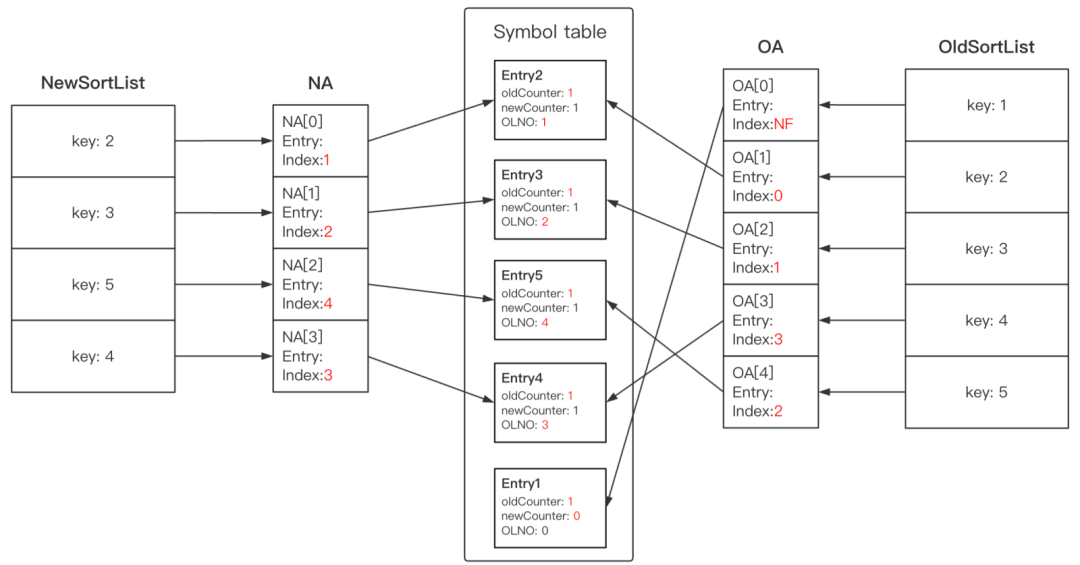
Heckel算法通过6个步骤借助符号表产生新老数据之间的Diff信息
- PASS1. 建立新数据所需新索引数组(NA)与 Symbol Table 之间的关系
- PASS2. 建立老数据所需旧索引数组(OA)与 Symbal Table 之间的关系。
- PASS3. 查找位置没有变化的节点,更新新旧索引数组(NA、OA)中的索引信息。
- PASS4 - PASS5:适用于对两个本文进行比较的 Case(存在 Key 值相同的情况),在 QQ 的应用场景中不允许出现相同 Key 值的情况,可跳过。感兴趣的同学可以直接查阅论文。
- PASS6. 根据现有结果计算差异,如图下图所示:
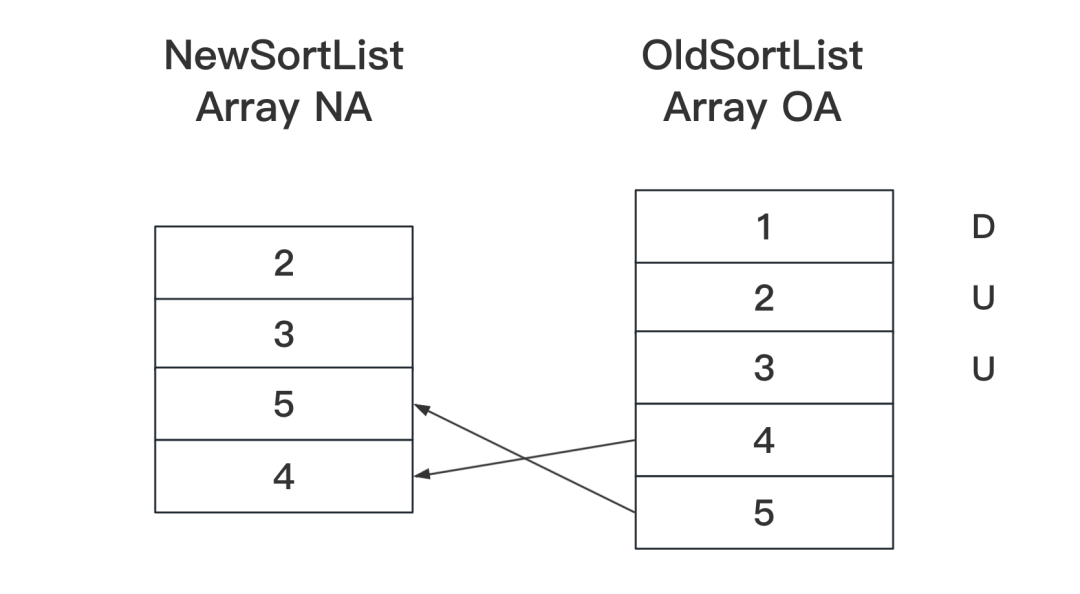
D表示被删除,U表示没有变化,4、5之间存在移动关系。
那么 Heckel 算法是完美的吗?不然,它并没有考虑冗余的移动信息,冗余的移动操作会导致下图中的动画错乱问题。
我们在 Heckel 算法的基础上进行改良优化,追踪记录移动操作,区分出直接移动与间接移动,并将间接移动部分进行过滤删除,最终得到满足 QQ 9 各项指标要求的 Diff 算法。如下图示例,ID5 直接移动到第一行,ID1-4 都是间接往下移动。
记录直接移动的偏移量(move = insert X + delete Y的偏移量都需要记录),修正间接/被动移动的结果(ID 1-4的移动)
并行预布局
异步布局作为业界的最佳实践,自然不能在 QQ 9 上缺席。我们也进一步尝试将异步布局并行化,深挖性能极限。
首先尝试了 N 条消息 N 个线程的方案:用 GCD 派发 N 个并发任务,然后用 DispatchGroup 等待这些任务执行完成。通过并行预布局,将原本一个线程需要几十毫秒的预布局减少到了十几毫秒。这个方案后来发现了
2 个问题:
并行布局 N 条消息的总耗时还是比串行布局一条消息的耗时要大得多,受限于 CPU 核心数,代码中的锁或其他资源竞争导致 N 条消息的参数准备和布局计算没有能充分的并行。
这N条消息的布局任务分别和 N 个 GCD 任务一对一绑定了,GCD 调度这 N 个任务中有任何一个调度慢都会拉长整个预布局的耗时。
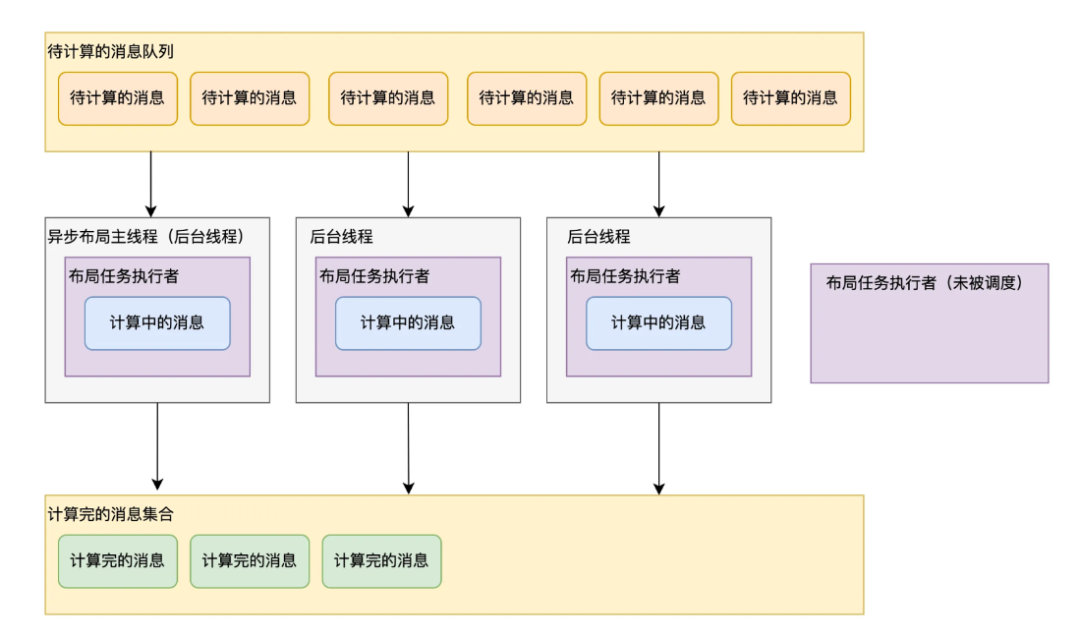
充分利用多核CPU的算力;使用并行计算,布局计算的总耗时减少了约76%。
调整后的方案如上图所示,使用了 M 个执行者来执行N条消息的布局任务(N>=M>0)。当前线程(异步布局主线程)来执行 1 个执行者,然后再由 GCD 额外调度(M-1)个线程来执行(M-1)个执行者。 首先将待计算的消息放入一个队列中,每个执行者都会循环从待计算的消息队列中取出一条消息执行布局计算,直到待计算的消息队列为空。因为消息的布局任务没有和任何一个执行者绑定,即使有执行者较长时间没有被调度也不会导致布局计算迟迟无法完成,大部分情况下这 M 个执行者会被 M 个线程并行执行。
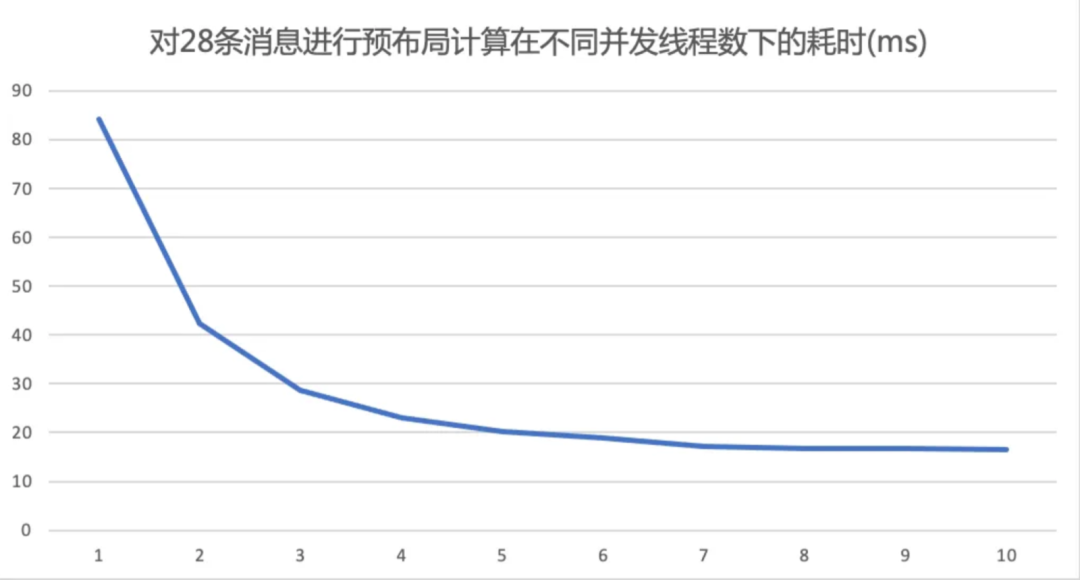
并行布局的总耗时会随着并发线程的增加而减少,当增加到5以后耗时就基本没有怎么减少了。
看上去目前布局计算的工作已经从主线程挪走了,现实是很多时候计算出来的坐标与大小并没有与屏幕的像素点大小吻合,此时系统会在主线程再做一次”像素对齐”。在”异步布局”时也不能忽略该细节,才能确确实实减少主线程的负担,如下图所示。

OLED屏幕的1个像素R:G:B比例为1:2:1,显示时DDIC(Display DriverIC,显示驱动芯片)会进行次像素渲染从其他像素借元素使显示更饱满。但代码并不能直接控制该行为,系统需要保证提交的内容与屏幕像素完全对齐,即不能出现类似使用0.5个像素的情况。
标黄区域为坐标、大小结果与屏幕像素未对齐
其他的优化还有:智能预加载、消息回收、图片资源异步解码等。如下图所示,根据屏幕比例得到一级缓存
display ,二级缓存 preload ,超出的部分则被回收释放。
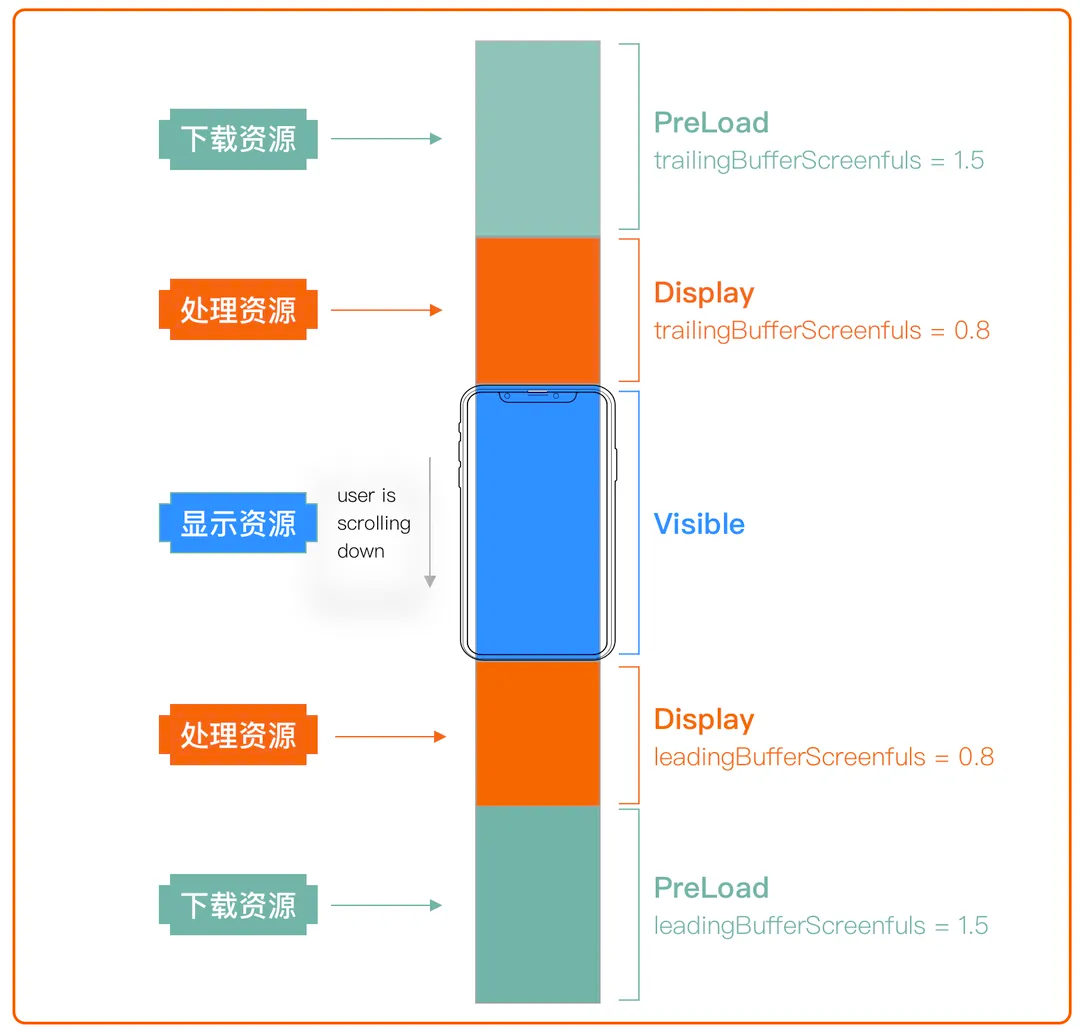
资源预加载策略图
尽可能让 GPU 绘制简单的界面,减少 GPU 耗时。
除了布局可以异步计算,复杂的图像也能使用”异步渲染”的方式降低 GPU 的耗时;特别是面对需要叠加裁剪的图形时, GPU 的绘制任务无法在一个 Frame 内完成,就需要再额外开辟一个 Frame Buffer 进行绘制,并在全部完成后将两个 Buffer 的内容进行合成,这被称作”离屏渲染”。离屏渲染对于性能的损耗非常大,主要在于 GPU 的上下文切换所需的开销很大,需要清空当前的管线和栅栏。原话在这:A Performance-minded take on iOS design | Lobsters。对于这种情况,苹果的工程师给出的建议是用 CPU 绘制来给 GPU
分担一部分工作。如下图所示:
标黄区域为GPU离屏渲染,不可否认GPU的off-screen比CPU的off-screen代价高很多;在无法避免mask的场景下,使用多核CPU进行异步渲染性能更好。
我们在渲染消息时利用了多核 CPU 进行异步渲染,降低 GPU 部分的耗时。这里面临的难点在于:在可快速滑动更新的列表场景使用时会出现”闪白”的问题;如著名第三方开源框架 YYKit 也存在此类问题,我们通过 LRU 缓存+增量刷新的方式很好的解决了此问题。
叠满 buffer 的丝滑体验
基于上述 CPU 与 GPU 维度的各项优化,我们在消息 Tab 上实现了国内头部同类应用目前也不具备的滚动中实时接收消息的能力,且不会出现卡顿;此外,也扩展了老版本 150 个会话的限制,与聊天界面一致以分页的形式加载用户所有的会话节点,如下所示:
滚动中接受消息,且不卡顿
进入群、好友聊天界面的速度也得到了质的提升,在加快进入动画的同时,依然能够保证即刻就能看到最新的聊天内容。如下图所示 —— 同一个帐号进入同一个聊天页面。左边是优化前的效果,聊天页面都快全部展示了,内容还在加载中;右边是优化后效果,聊天页面只展示了一点点,就已经能看到发送方头像和消息内容了。
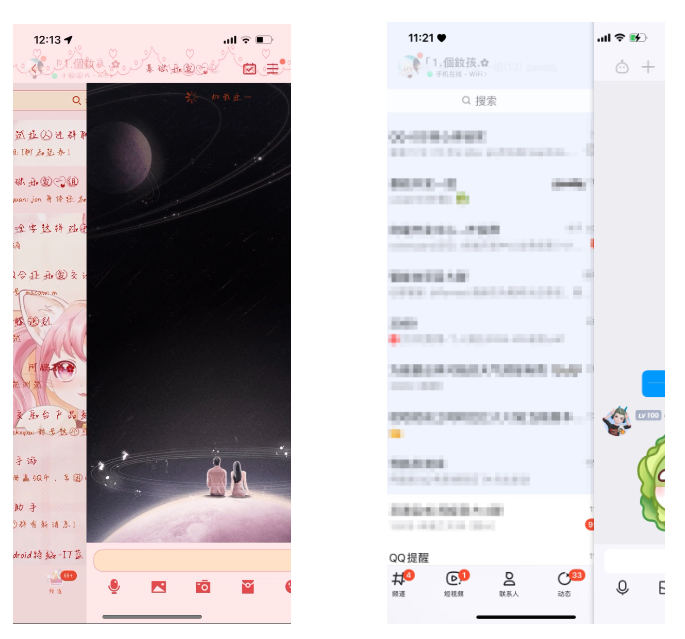
进入聊天页面加载速度对比图(左为优化前,右为优化后)
除了进入速度的提升,聊天内容翻页的速度也达到了业内顶尖水平:超越国内头部同类应用,对标 Telegram。不论用户有多少消息,都能够通过不断上拉看到,并且用户感知不到 loading 态。
聊天页面优化前后对比图(上为优化前,下为优化后)
青春常在 — 防劣化系统
打江山易,守江山难。防劣化是所有达到一定规模的技术团队都会头疼的问题,面对复杂的业务和技术债,手 Q 团队投入了 3 年的时间迭代优化,现在手 Q 的防劣化系统已经达到了业界先进水平。作为手 Q 质量的守门员,我们将其命名为 Hodor(Hold the door)。
防劣化目标:提前发现部分主路径问题,通过门禁防止性能劣化。
- 主干合流门禁:对于较稳定的性能指标,合流前自动检查。
- 日常自动提单:针对偶现的性能问题,开发阶段提前发现。
- 性能数据看板:常态化详细数据看板,上帝视角观测性能。
- 告警机器人:自定义各性能维度告警规则,第一时间反馈问题。
整体方案是基于 Instruments 动态追踪技术采集 diagnostic 诊断数据;xctrace 自动解析 trace 文件,翻译堆栈精准归因;每次提交构建均执行防劣化检测,精准定位问题;还有数据可视化看板 + 自动提单派发,将质量左移到开发阶段。最终实现了性能报告、数据分析、智能调度、提单告警、设备管理、用例管理等一系列能力。一图以蔽之:
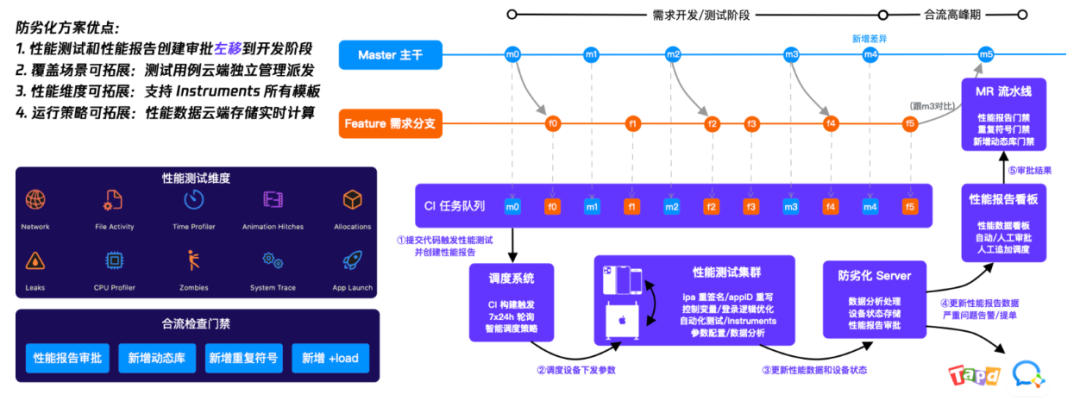
防劣化系统方案简介
Xcode 12 开始提供了 xctrace,其 Release Notes 中解决的很多 issue 也来自于手 Q 团队在防劣化开发过程中发现与反馈。在性能优化方面 QQ 与 Apple 性能团队交流紧密,大家也会加班克服中美时差。
整个手 Q 防劣化系统上线以来,有效地保证了开发主干的稳定性,也检测到了大量的性能和崩溃问题,同时拦住了很多新需求引入的性能问题。
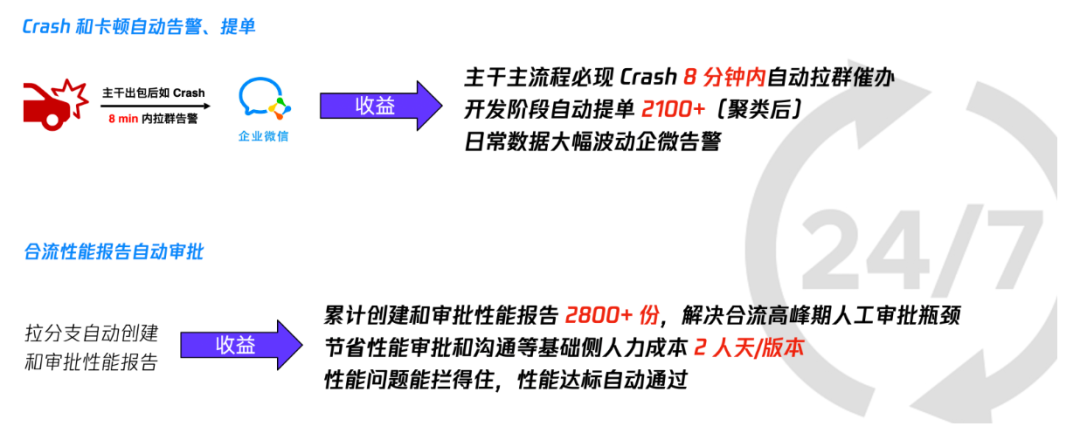
防劣化成果图
目前 Hodor 已经覆盖数十个场景,并落地 iOS/Android/Windows/macOS/Linux 五个平台。
轻盈焕新的 QQ 9
经过上述全方位优化,QQ 9 在各场景的性能都较历史版本较大的提升,如下图所示:
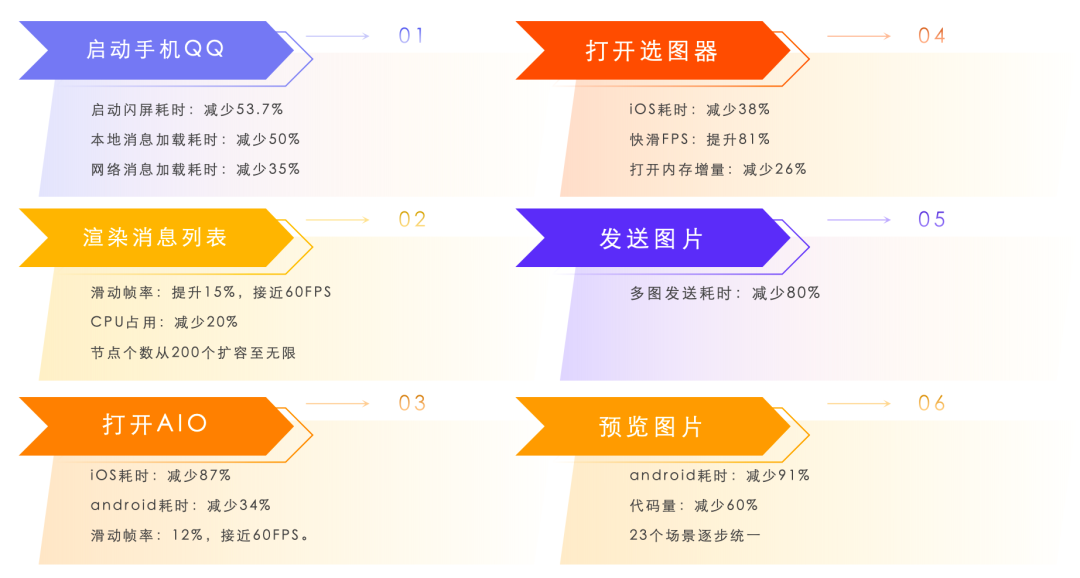
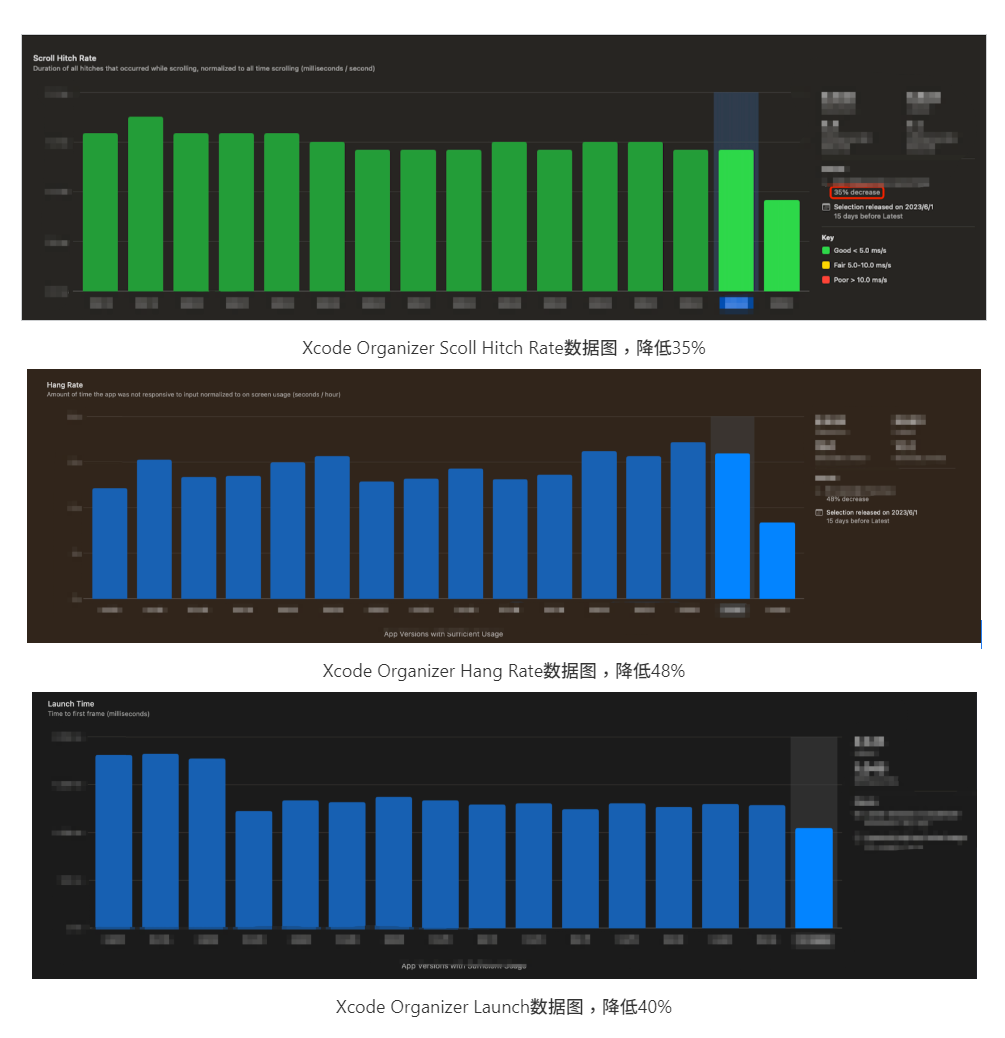
使用苹果官方的工具:Xcode Organizer 可以看到 QQ 9在流畅度上较之前的版本 50 分位提升35%,卡顿率降低48%,启动耗时降低40%。如下图所示。
总结和展望
本文我们介绍了 QQ 9 丝滑背后的技术实现,从启动速度,页面刷新,差异算法,预加载和回收,异步布局和渲染等方面介绍了我们在性能方面做的全流程优化,并介绍了几个用户体验提升的场景表现。
其实技术领域深入复杂,每一项优化点都可以单独拎出来好好地展开说明,因为篇幅问题,只能留到以后慢慢和大家分享。
希望 QQ 技术团队做的这些打磨,可以给用户带来切实的体验提升;也希望 QQ 能越来越好,因为我们每一位也是坚持使用 QQ 的 5 亿分之一。
-End-