动画方案
概述
在目前的视频直播行业,礼物动画效果越来越酷炫。但由于动画方案和设备性能的原因,动画设计师的好多想法并没有得到很好的还原。YY的动画方案在近10年的时间也是经历了图片序列帧、SVGA、MP4、到现在的支持动态插入元素的YYEVA(YY Effect Video Animate)方案。目前已经基本能够实现设计师所见即所得,充分解放了设计师的想象力,同时能够在体积和性能上取得平衡。
在这篇文章中,我会从原理上去讲解目前市面上和YY的动画方案。也提供对比,以及分析各自的优缺点,方便开发者进行方案的选择。
动画原理
作者在这里把动画方案的实现原理分为三种。
- 第一种是纯面向过程的动画记录方式,目前市面上主流的有Airbnb 的Lottie和腾讯最近开源的PAG,原理是通过记录动画设计师制作动画的每个元素,还有每个元素的运动过程,然后开发者再还原这些元素的运动。这个方案的优点是文件体积小,能实现大部分基础特效和变换下的动画。缺点是不支持比较复杂的特效(如3D效果等),播放性能也比较差,因为记录过程就必然有一个还原动画的计算过程,在渲染的同时还需要计算每个元素的变化过程,对比其他方案就多了一项计算的性能损耗。
附Lottie动画示例:
第二种是半面向过程半结果的动画记录方式 目前市面上主流的方案有YY的SVGA和Y2A方案,原理是记录动画设计师制作动画时用到的每一个元素,然后记录元素在每一帧的特征(形状,大小,位置,alpha等)。SVGA的优点是能支持更复杂的动画,同时播放性能也比第一种方案好许多。缺点是体积会大一些,同时也不支持复杂的特效(如3D效果等)。为什么第二种方案相比第一种方案性能上比较好,也能够支持更复杂的动画呢,这是牺牲了一部分文件体积,从而减少了计算这一环节的因素。SVGA的文件经过zlib压缩和base64编码后,压缩率能达到85%~90%,所以体积上并不会比第一种方案多多少,相对而言是综合性能比较好的方案。
举个例子,要记录一个人从广州开车到北京的动画过程。Lottie记录方式是:有一辆长宽高为xxx的汽车,30天(帧)匀速开到北京。SVGA的记录方式是:有一辆长宽高为xxx的汽车,第1天在广州,第2天在韶关,第3天在赣州…第30天在北京。还原动画的时候,Lottie的方案需要计算每1天(帧)汽车走到哪个位置了(通过广州和北京的距离,再除于总天数来计算当前所在城市),而SVGA因为已经记录好了每一帧的信息,省去了计算的过程。这个例子中SVGA体积会比Lottie文件大,但播放性能上会比较好。
再举个例子,冬奥会的花样滑冰运动,Lottie记录的是运动员x左边飘移y米,转体四周半,落下后来个蟹步,然后再反向转体四周半。要还原这个动画,Lottie的计算过程就相当复杂了,要通过转体几周来计算每一帧运动员的特征(形状,大小,位置等)再渲染,播放这种复杂动画的时候就会卡,因为计算量太大了。而SVGA记录的还是运动员x,第1帧特征(形状,大小,位置等),第2帧特征……第n帧特征。因为记录的是运动员每一帧的特征(形状,大小,位置等),相比第一个例子并没有变复杂,省去了这些复杂的计算,就能够更顺畅的播放复杂的动画。

- 第三种是记录结果方式,目前主要有PNG序列图和带透明通道的MP4方案。原理是记录每一帧每个像素点的像素值来渲染,优点是所见即所得,充分解放设计师的思想,能够支持所有设计师能设计出来的动画,包括3D动效等。其中PNG序列图由于体积大,性能较差等原因基本已很少开发者使用,而带透明通道的MP4能够在体积和性能、效果上取得较好的平衡,特别是h265编码的MP4体积更小。这也是目前YY播放复杂动效采用的技术方案,YY自研的YYEVA支持通过AE插件一键导出h265编码的视频,并能够动态插入元素,支持播放时动态替换元素,有一套完整的工具链,涵盖了设计侧和开发侧。
- 这种方案体积上一般会比前两种方案大一些,但使用h265编码就能够在牺牲一点性能情况下减少体积,对于中高端机型是很值得的。MP4方案主要的难点在于怎么样支持动态插入或替换元素,因为MP4只记录了结果,设计师设计的动效有哪些元素和每个元素的运动轨迹都没有记录下来,就很难去替换具体的元素。YY的方案是从设计师设计动画时着手,让设计师在设计动效时指定哪些元素是需要动态替换的。因为设计师目前主要使用AE进行动效设计,我们就通过AE插件,记录设计师指定的需要动态替换的元素,然后将这些信息存入MP4文件的Metadata数据。客户端在播放时取出Metadata信息,再根据这些信息动态替换指定位置的元素并还原元素的运动过程。大体原理是这样,整体方案细讲起来需要比较长的篇幅,我们会在另一篇文章中详细的给大家分析我们的YYEVA方案。
总结
三种方案依次能实现的动效复杂度是越来越高的。
- 第一种方案 支持一般的动效,比如UI动画,场景切换动效和一些进场、得分等动效。
- 第二种方案能支持第一种能支持的所有动效,且能够支持更复杂的动效,例如复杂的礼物动效,酷炫的坐骑动画等。
- 第三种方案能支持所有的动效,只要设计师能设计出来的动效都支持。在体积上,也是依次递增的,第一种方案体积最小。但是在性能上刚好反过来,第一种方案性能最差,CPU和GPU占用较高。
所以具体使用哪种方案,要看自己的应用场景,如果是简单的动效多,可以考虑采用Lottie和PAG方案,如果是比较复杂的礼物动效,建议是采用SVGA方案或者MP4方案。
作者在这里提到的方案,包括Lottie、PAG、SVGA和YYEVA,都支持设计师预览效果,在客户端播放器还原设计出来的效果,所见即所得,不需要额外开发。比起传统的设计师出效果图,开发自己写代码去还原动态效果的方案,效率是非常高的,不需要开发和设计重复对齐返工。为什么能做到完整的还原设计师的效果,这里要提到一个PC时代动画界的王者Flash,不管是Lottie、SVGA、PAG还是YYEVA,这些方案的作者都有Flash相关的设计和开发经验。因为Flash是为数不多既能用来设计动画,又能开发应用或游戏的软件,Flash动画设计师和Flash程序员使用的都可以是Flash这个软件,所以产生了一些既是设计师又是开发者的角色,转行移动端开发以后,创造了这些移动端的动画方案,这些方案的原理都与Flash有共通之处。
看到这里,可能读者会问,那我应该怎么进行方案选型呢。我的建议是能用SVGA实现的动画尽量用SVGA来做,SVGA实现不了的动效(例如带3D效果和复杂滤镜的动效),就采用YYEVA的方案来实现,目前YY也正是采用这种方案,SVGA和YYEVA搭配使用,不管在性能和效果上都能够达到要求。这个方案还有个好处,对于设计师而言,SVGA和YYEVA都有一套完整的工具链,都可以直接预览效果,通过AE插件可以一键导出SVGA文件和MP4文件,YYEVA支持自己设置编码参数以及使用h264或h265编码,可以在性能和体积上取得更好的平衡。
YY透明MP4礼物
本章是对目前直播行业比较成熟的播放透明MP4礼物实现方案的一些理解,内容全部来自个人对整个工具链的认识,如果有理解不到位的地方,希望可以在评论区和我一起探讨。
1.MP4的简单理解
MP4是一种流媒体的封装格式,内部常使用 avc作为视频轨道的编码方式,aac作为音频轨道的编码方式,在编码avc的时候,使用的颜色采样标准是YUV,YUV是一种色度+亮度的颜色采样格式,可以通过公式转换成RGB。
1 | MP4 = (Video Track) + (Audio Track) + (Other Track) |
具体MP4的一些概念,大家可以自行去google查询相关资料,本章就不重点论述了。之后有时间,再写一遍文章来展开谈这部分相关概念,
2. MP4礼物特效
对于设计师来说,MP4礼物特效,是一种所见即所得的动画方案,充分解放设计师的思想,能够支持所有设计师能设计出来的动画,包括3D动效等。并且充分利用了avc的高压缩率的优点,在客户端解码的时候,使用硬解充分发挥GPU的能力,减轻CPU的压力。是一种很好的动画实现方案。但是,由于使用YUV颜色采样标准,因此不具备alpha通道,在播放全屏礼物的时候,会遮盖住整个屏幕,这对于产品来说,是不可接受的。
3.透明MP4礼物特效
早在去年的时候,各大直播软件 就推出全屏的MP4礼物动效,作者也通过分析sandbox的方式,发现抖音,YY等app也是通过透明MP4礼物特效的方案,来实现全屏MP4礼物。各个公司实现的技术方案都大同小异,只是 rgb+alpha区域的位置排放有所不同而已。下面我们以AE作为资源导出工具,从设计侧的资源输出和客户端测的渲染 2个方面,来对该方案做个简单的介绍。
3.1 效果演示

3.2 资源输出
设计侧在使用AE制作完特效后,导出的渲染队列是一个如下图的MP4视频,该视频在全屏播放的时候,整个直播间背景都会遮盖住,体验不好。
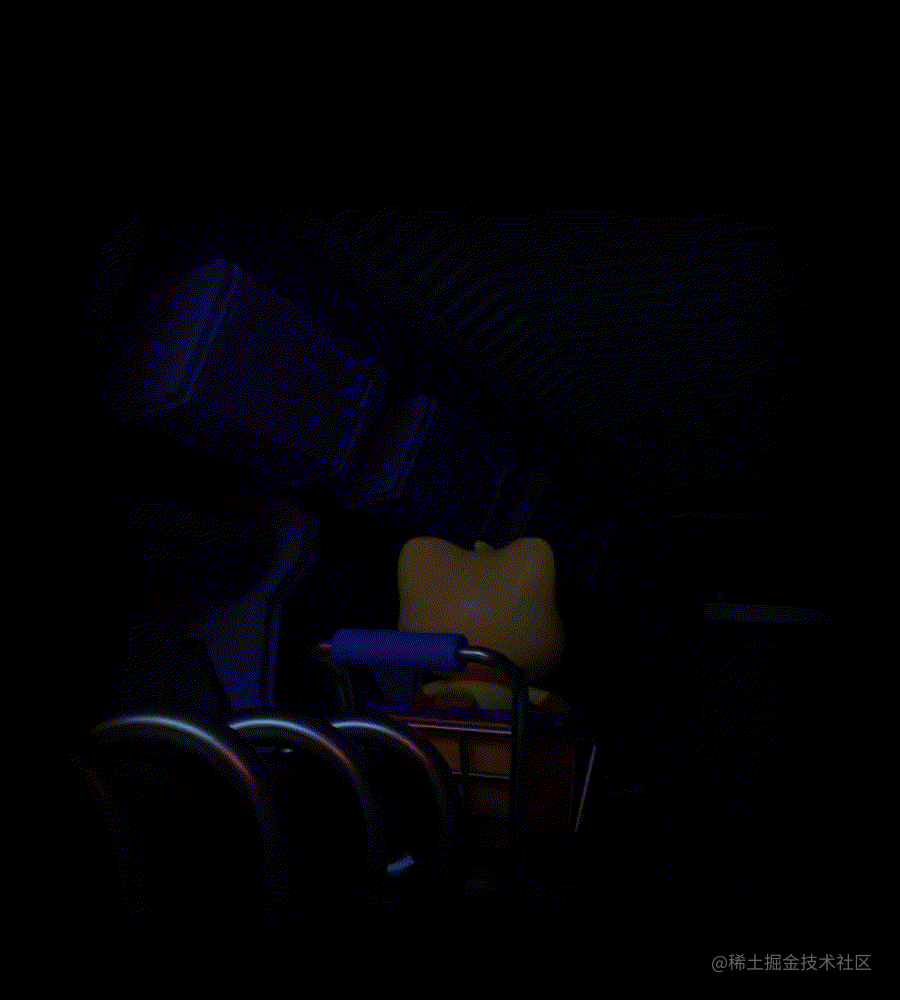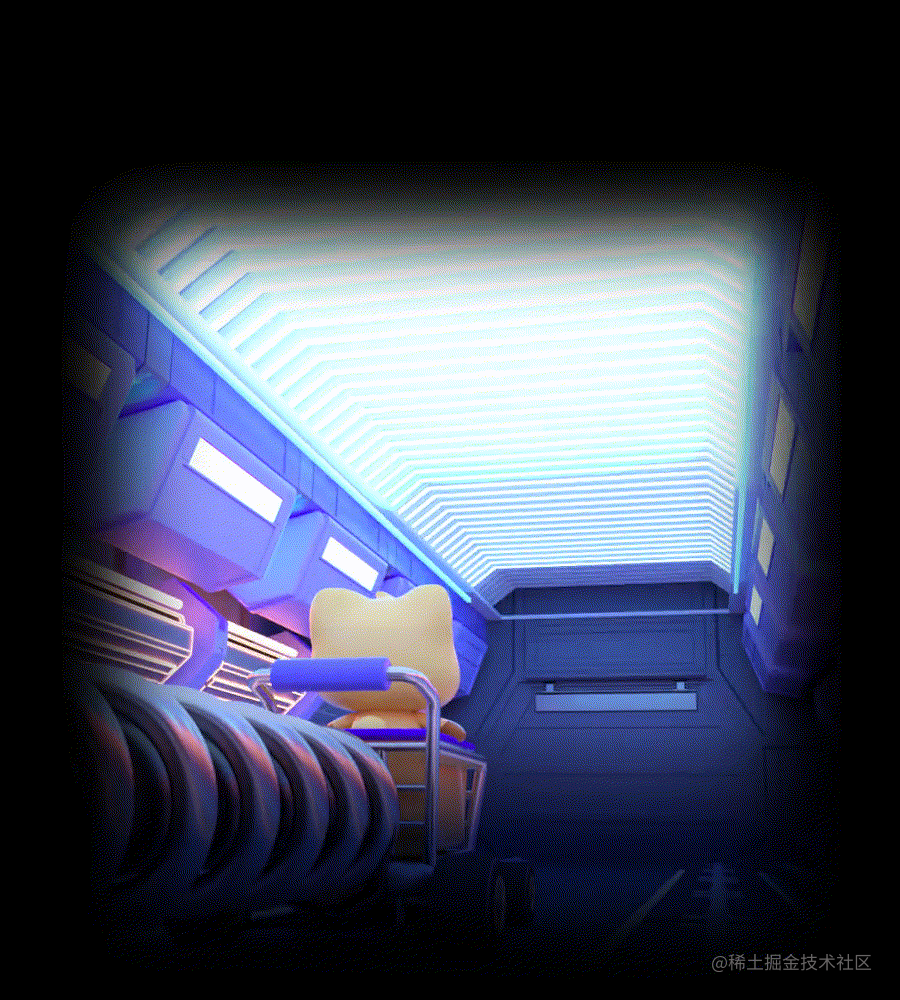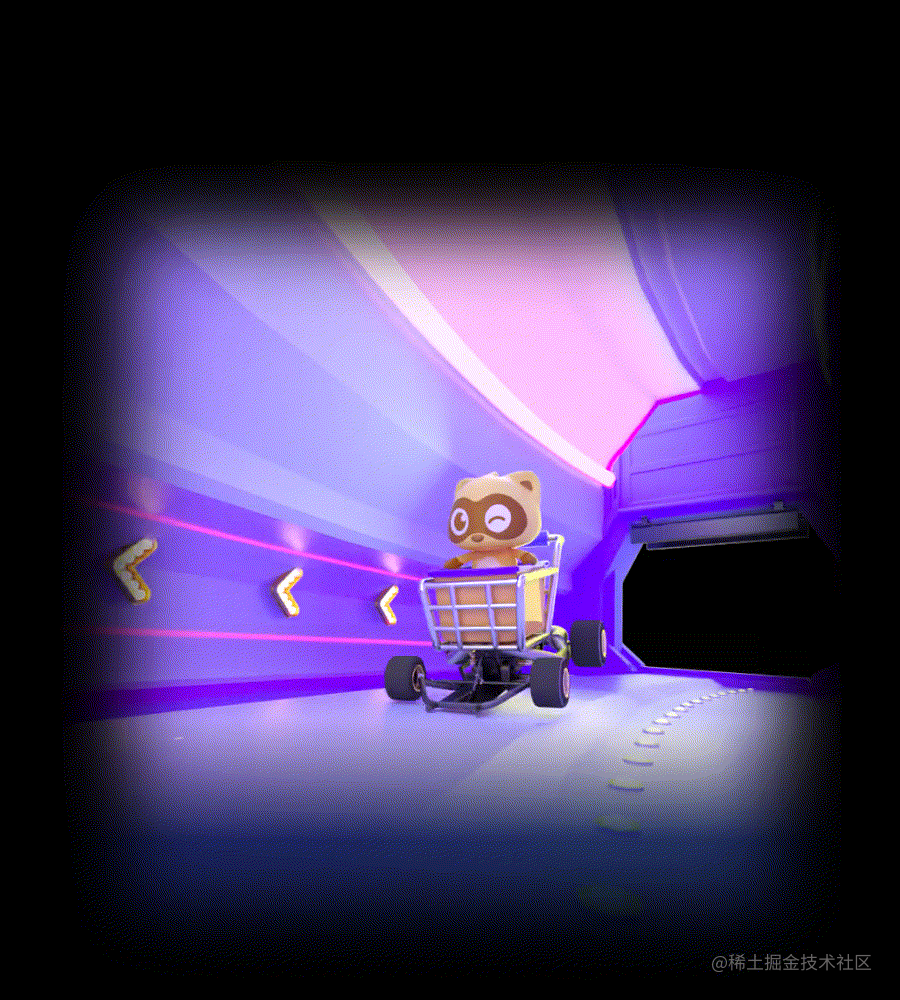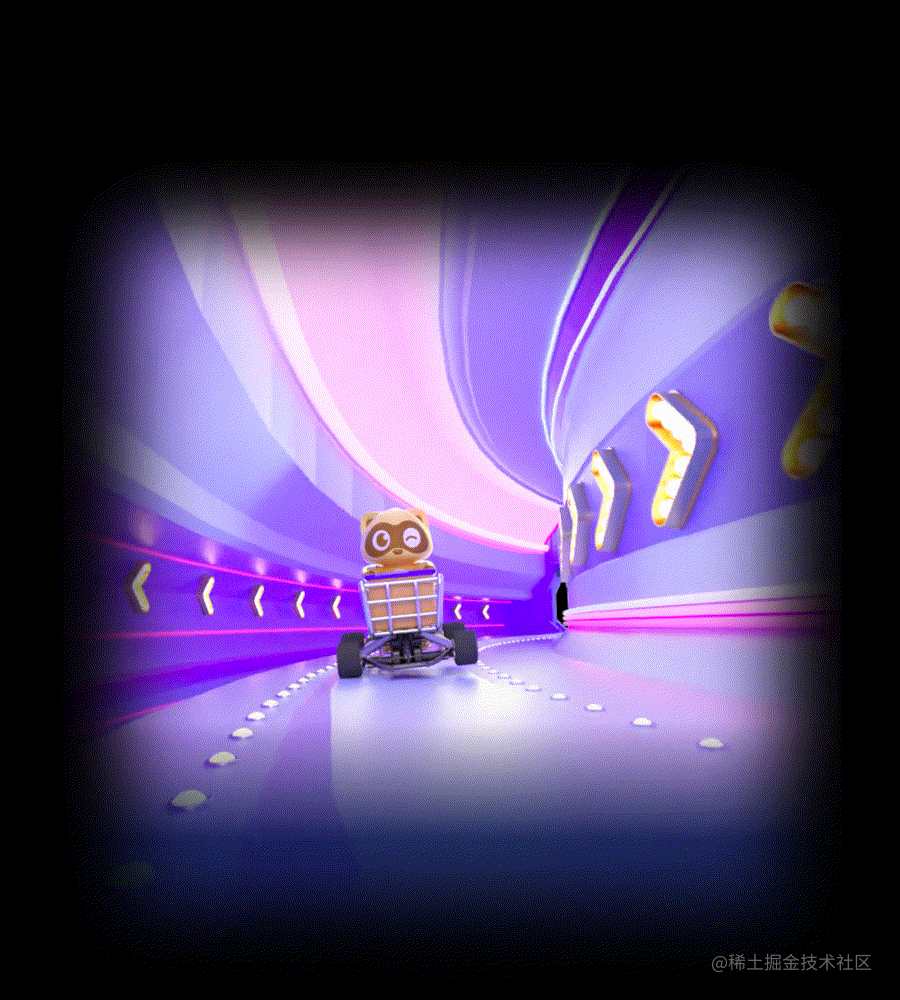
设计侧制作的透明MP4特效:导出的渲染队列是一个如下图的MP4视频,该视频在全屏播放的时候,整个直播间背景不会遮盖住,体验很好。
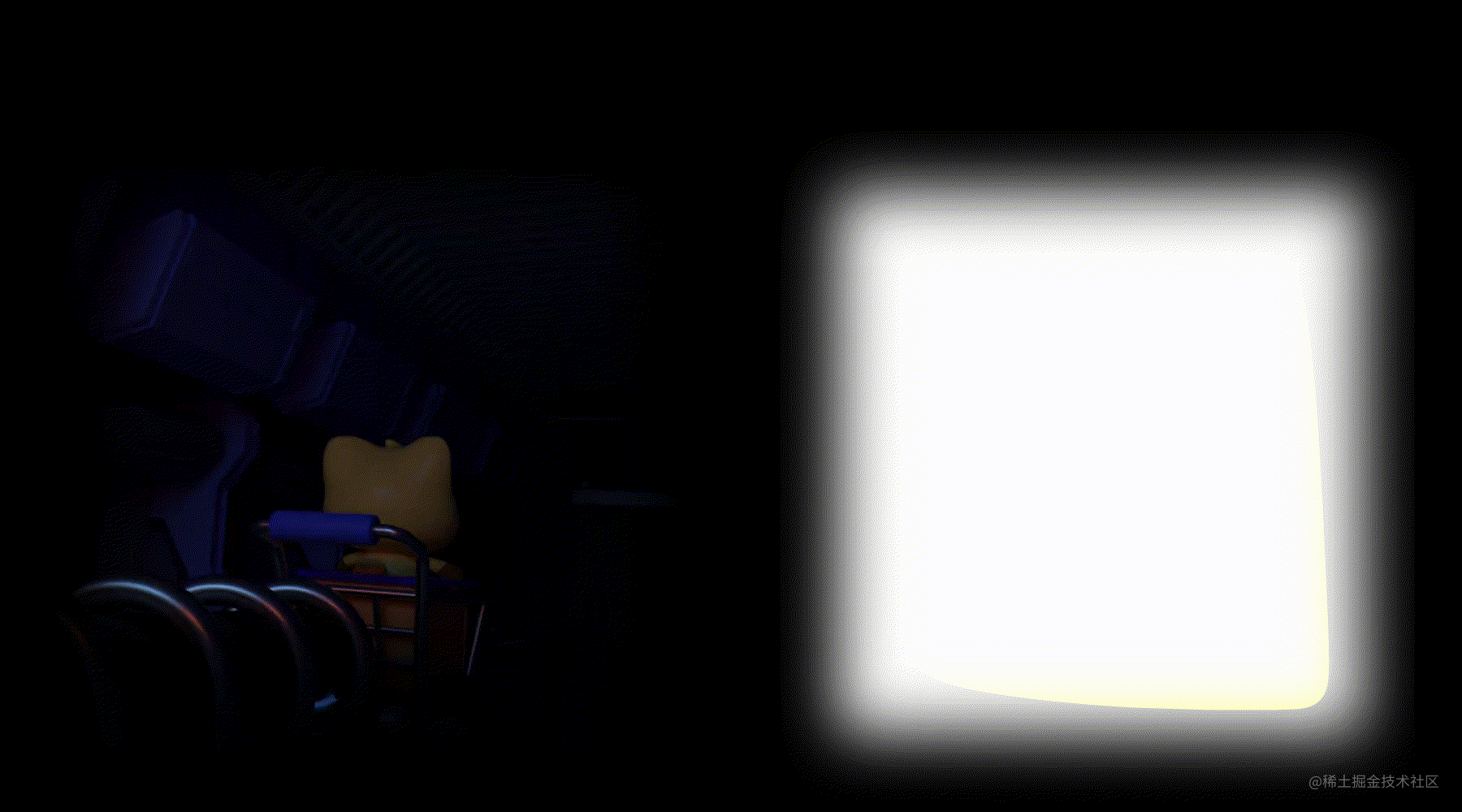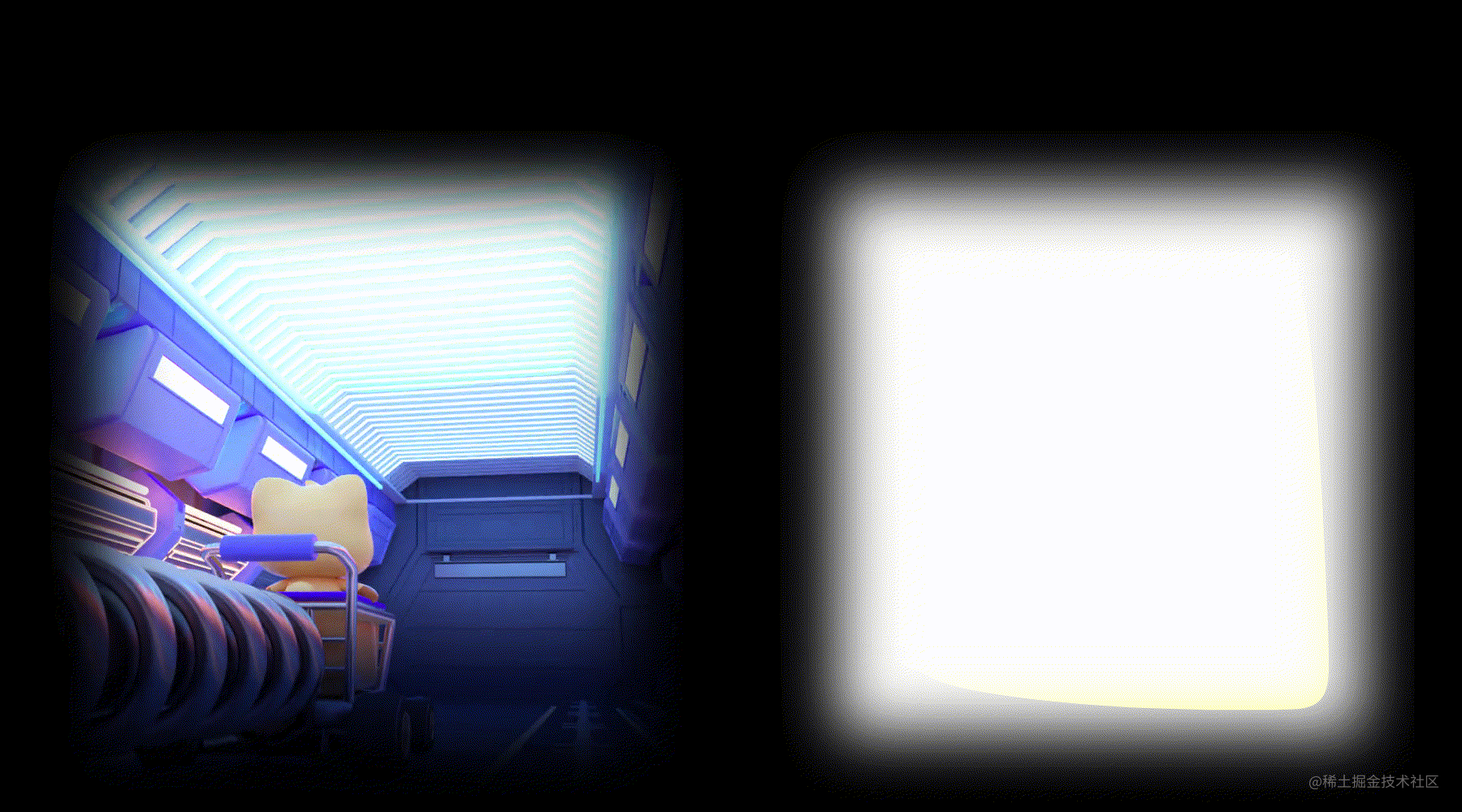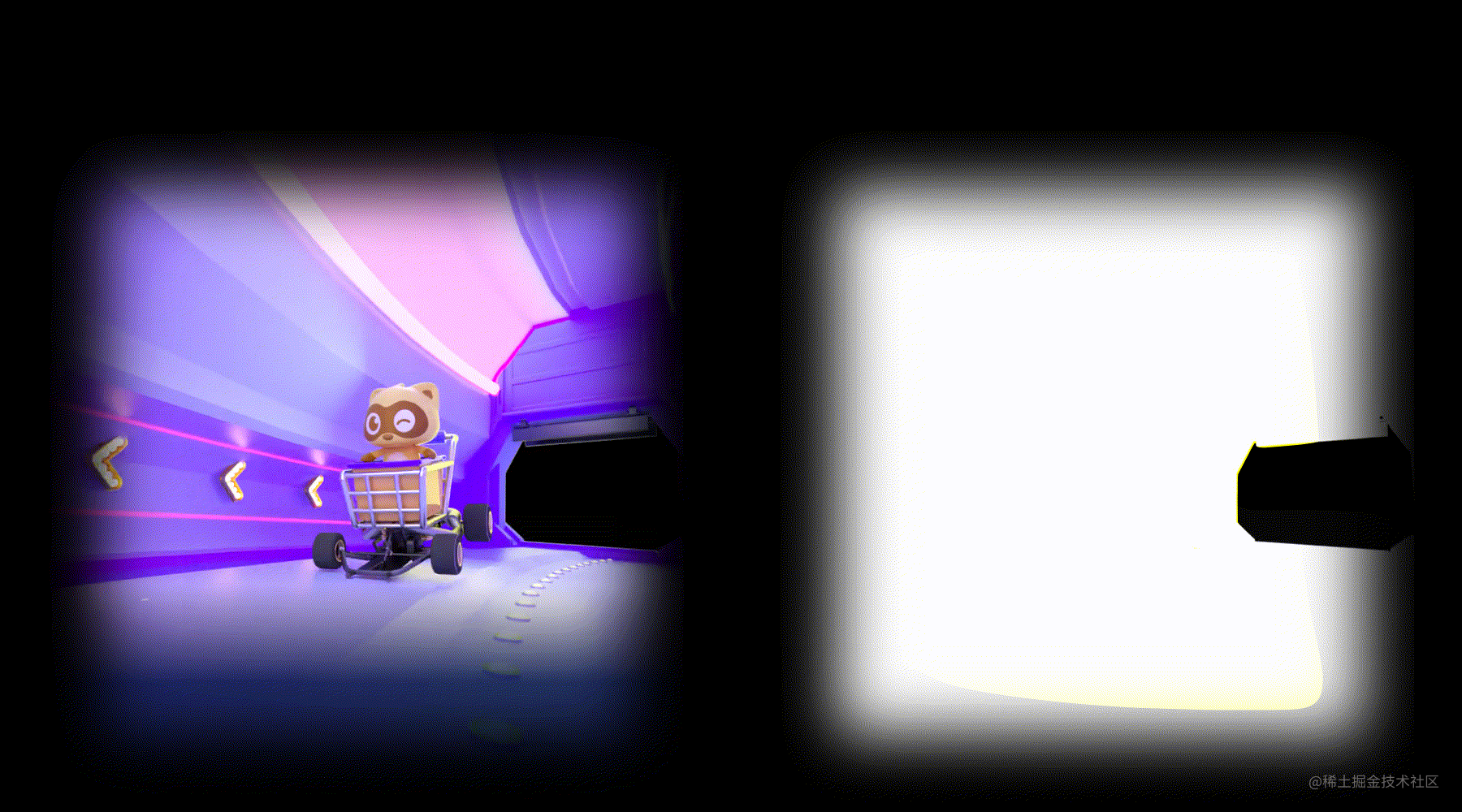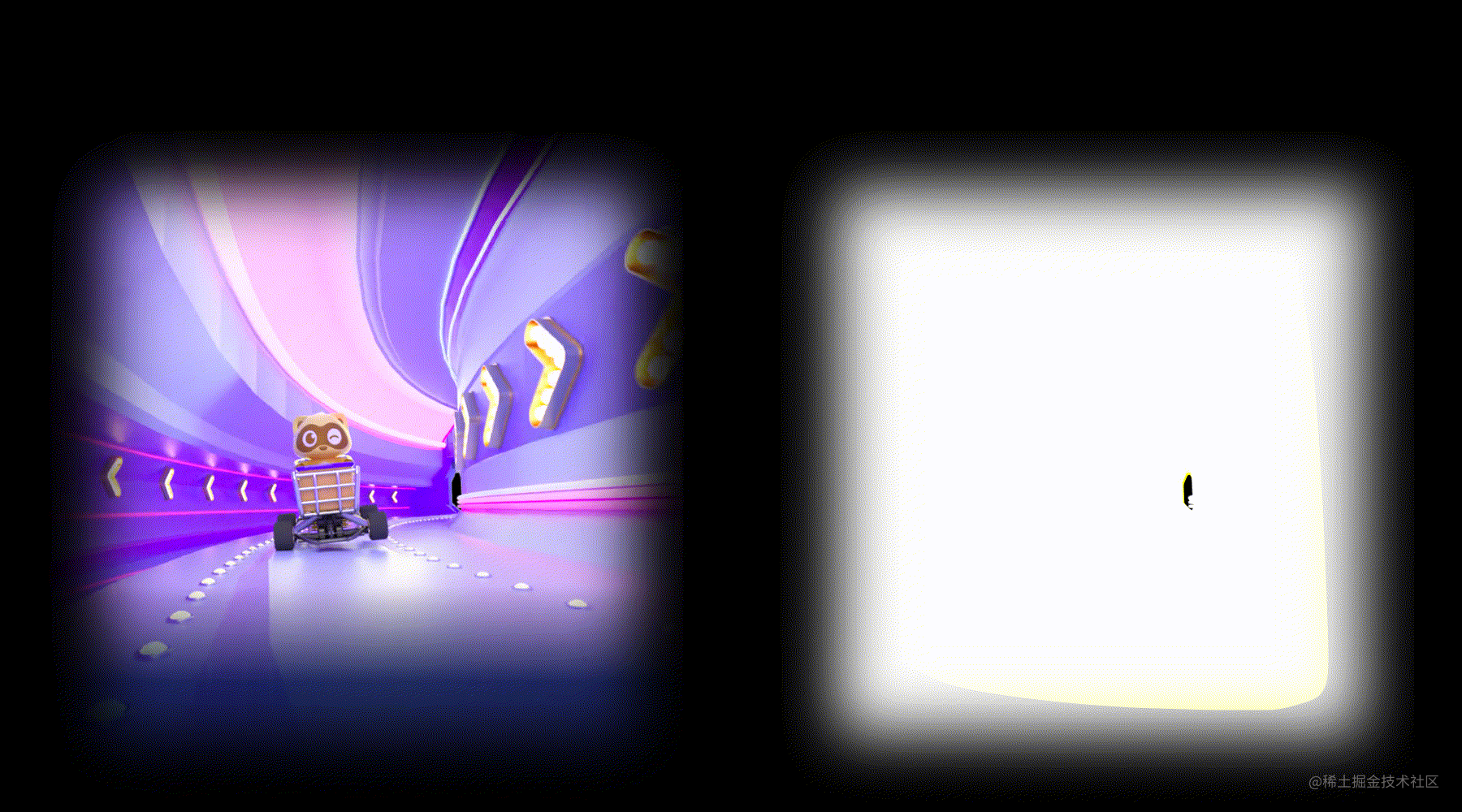
右边图层,就是左边图层的有像素值的地方为非黑色,无像素值即黑色的地方为黑色生成的一个图层。
所以输出的第二个视频就可以使普通MP4在渲染的时候,具备透明的效果,因为右边的区域值保存了左边区域的alpha通道。
3.3 MP4+Alpha混合原理

如上图所示,源素材向右扩充了一倍的像素,用来存储Alpha通道的数值,在客户端渲染的时候,直接使用右侧像素点的R值,除以255,就得到了0-1之间的alpha取值
例如第一个像素点, 红色:右侧的RGB值为(255,0,0) + 左侧的R值(128) ,混合之后的 RGBA = (255,0,0,128/255) ~= (255,0,0,0.5)
3.4 客户端渲染
客户端拿到视频轨道数据后,解码出每一帧图片,然后通过左边yuv+右边的yuv混合后再上屏,gl公式可理解为
1 | gl_FragColor = vec4( |
变换矩阵在动画上一些应用
介绍
我们都知道,屏幕是由像素点组成的。而动画的实质,就是对元素内的像素点进行平移,旋转,放缩等相关操作。如何把相关操作,用数学的形式表示出来,并通过计算机的方式来还原,这时候就需要通过变换矩阵来描述了。本章我们来通过一些数学公式,理解下如何通过变换矩阵,把动画的过程描述下来。下面我们以二维平面为例,展开论述。
1. 齐次坐标
在齐次坐标领域,有一个确切的结论 ,二维平面内
1 | 点: 用 (x, y, 1)来表示坐标系中一个固定的坐标点 |
可以得出第三个分分量 区别就是0与1。点的重点在点,向量的重点在方向。
2.矩阵相乘
2个矩阵相乘的前提条件是:前一个矩阵的列 要等于后一个矩阵的行,且得到的结果是 前一个矩阵的行x后一个矩阵的列,即
1 | n x m * m x k = n x k |
3.矩阵运算
3.1 平移
考虑一个点(x,y,1),我们知道,一个点在x轴上平移3个单位,y轴上平移4个单位,平移后的结果为 (x+3,y+4,1)。我们使用列向量 来表示点 ,通过上面的矩阵相乘我们知道,需要构造一个 3x3的矩阵,且左乘 列向量后,才能够得到 一个新的 3x1 的列向量
即推到公式如下:
1 | a b c x x+3 |
可以看到, 让一个像素点 平移dx ,dy 。 即 构造一个上方的矩阵后,左乘 向量 即可得到新的点
3.2 缩放
考虑一个点(x,y,1),我们知道,一个点在x轴上伸缩3倍,y轴上伸缩4倍,伸缩后的结果为 (3x,4y,1)同理,需要构造一个 3x3的矩阵,且左乘 列向量后,得到新的结果
即推到公式如下:
1 | a b c x 3x |
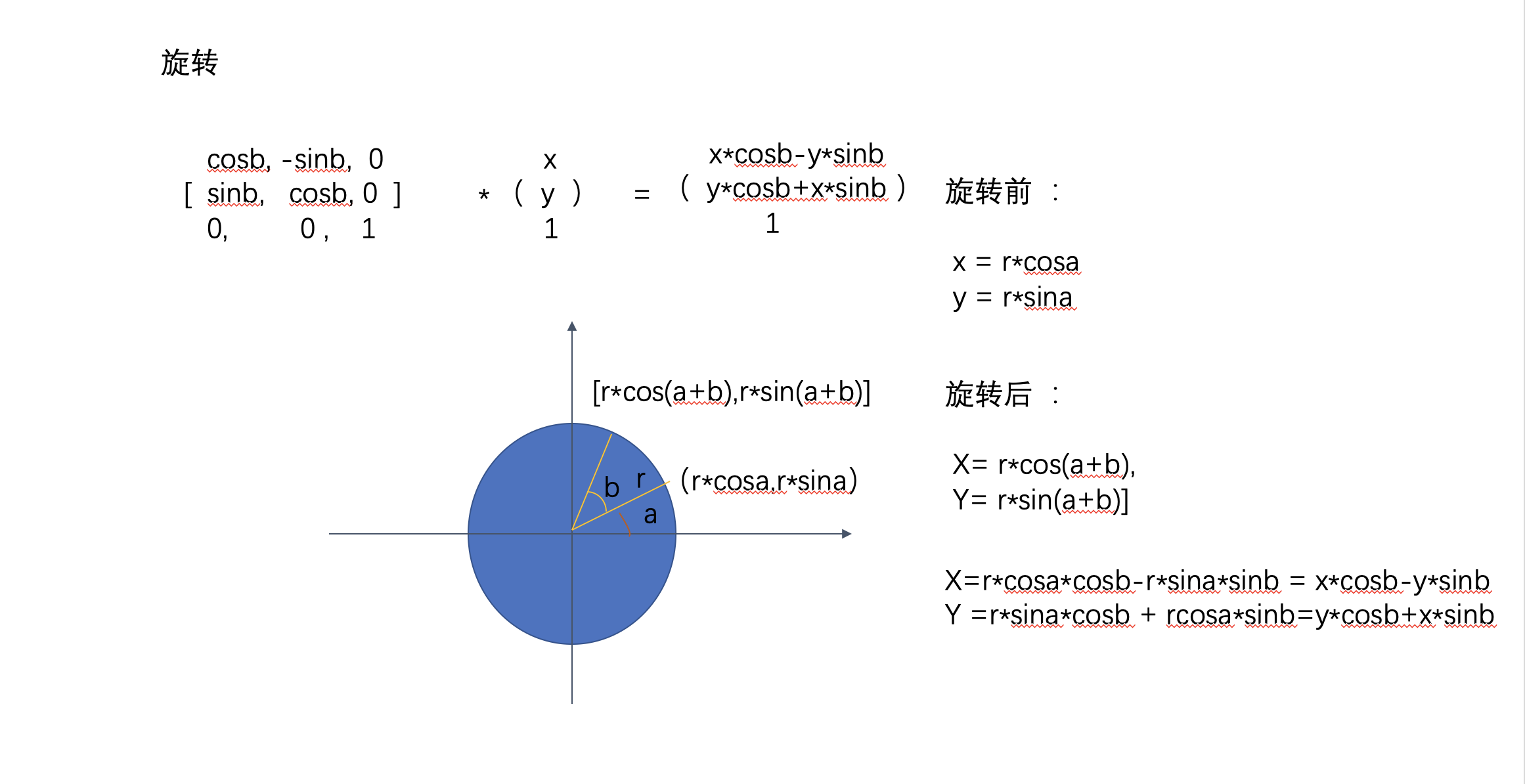
3.3 旋转
考虑一个点(x,y,1),我们知道,绕着圆点旋转 b 度。这里用一个图来展示下 旋转后的结果
1 |
|
4. 仿射变换
仿射变换就是用数学表达式,通过以上矩阵变换进行组合,可以用来左乘点列向量,表示像素点的变换
其中注意:左乘一般是先放缩、旋转变换,再做平移变换,例如
1 | 对像素点 (3,4,1) -》 x轴正方向平移一个单位,y轴正方向平移2个单位后 -》 x轴方向放大2倍,轴方向放大2倍 |
总结变换矩阵如下表示
1 | a 0 dx |
其中 a b 共同影响着旋转和缩放 ,dx ,dy影响位移
YYEVA让MP4静态资源也能够动态起来
介绍
在很多业务场景中,需要在静态资源 叠加 业务数据,例如,在直播间的送礼场景下,需要在动效资源内添加用户和主播的头像和昵称。目前比较成熟的方案有 SVGA,Lottie,这两种方案都能实现在资源显示的时候,动态添加业务数据,但这2种技术方案都不适合一些复杂的3D动效。在直播领域,一些大额的礼物动效都使用了MP4资源来播放。
因此,去年下半年,YY也着手研究如何让MP4能够像前两者一样,支持动态元素插入,满足视觉效果的前提下,更好的和业务结合,在研究2个月后,我们完成了YYEVA (YY Effect Video Animate)的开发,并推出了整套工具链,覆盖 设计侧的资源输出、在线预览 、客户端测的渲染。YYEVA包含的工具链: Adobe After Effect插件、 Preview预览页面、各平台渲染SDK
在这边文章发布前,我们也上线了几个新的礼物动效,如漫画脸礼物,使用了该方案完成MP4静态资源动态化。
设计师篇,请跳转到文档:第五篇:YYEVA设计规范
探索
在 第二篇:透明MP4礼物 文章里,有介绍过,MP4资源,使用YUV颜色采样标准,本身是不支持alpha通道的,透明MP4实现方案就是增加了一个区域来存放源素材的alpha通道。因此,我们也是按照该思想,再进一步去扩充MP4的能力。
经过和设计师的沟通,我们确定了动态插入的元素 暂分为 “文字“ ”图片” 两种类型
同时,资源是由动画同学去设计导出的,理应由他们来指定应该
- 插入什么类型的元素 ?
- 以什么样的形状 ?
- 插入在画布的什么位置 ?
这里就存在三个关键信息:
- 元素类型
- 元素的形状
- 元素的位置
我们要做的,应该是制作一个Adobe Effect After插件,通过解析设计师制作的资源,把这些相关信息都保存下来,然后客户端就能够拿到这些数据后,去复原整个动画过程。
在 第三篇:变换矩阵在动画上一些应用 文章里,有介绍过,动画实质上就是通过将像素点左乘一个仿射矩阵,得到了一个新的位置。那我们如果能够通过 Adobe After Effect 提供的接口,去获取到每一帧图层的相关变换,然后构造一个相关的仿射矩阵,我们就能够获取到图层每一帧的位置。
事实上,我们就是按照这个思想,去完成整个YYEVA的方案。
YYEVA 具体实现方案
Adobe Effect After插件测
该功能模块主要是给设计师提供制作MP4开发的相关插件
我们开发的插件的主界面如下:
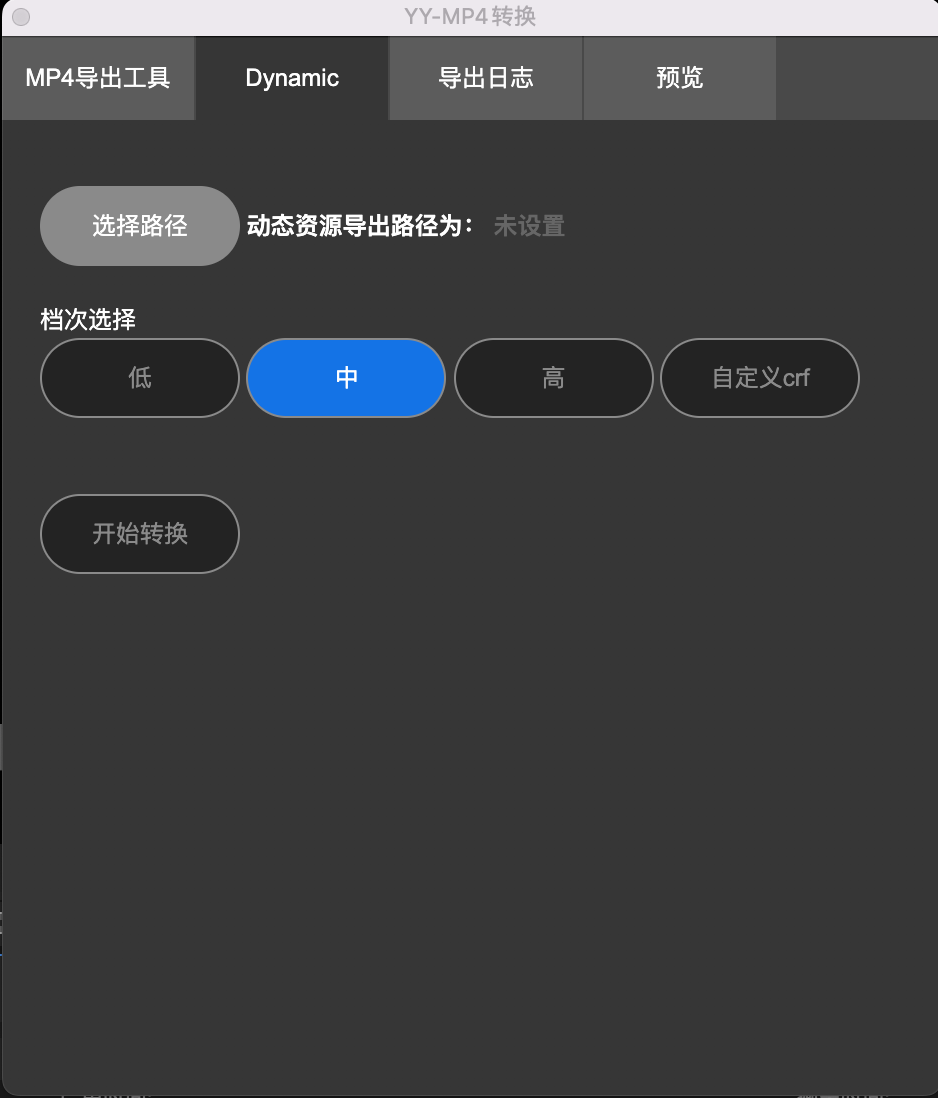
其中
h264/h265: 主要是为了扩充Adobe Effect After无法直接渲染出MP4而开发的一个子模块Dynamic: 主要是用来解析设计师的图层,导出一个混合MP4资源的子模块导出日志模块:主要是快速导出解析和转换过程中的日志,方便排查插件的一些功能BUG
下面对插件完成的功能每一个步骤进行详细的论述
1. 动效设计师 制作混合MP4素材
使用AE制作混合MP4的时候,需要遵循 第五篇:YYEVA设计规范 ,才能够正确解析出混合MP4资源。具体相关规范,请跳转至链接查看。
2. 转换前的准备工作
插件在进行转换前,会检测所选图层的合法性。主要是检测:
所选合成是否包含透明区域图层,因为我们目前开发的插件是在透明
MP4礼物的基础上做的一个扩充,所以源素材必须是一个透明MP4资源。所选合成是否包含
Mask遮罩区域;YYEVA插件设计规范有介绍,- 文字遮罩区域是以
mask_text作为合成的name - 图片遮罩区域是以mask_image作为合成的name
如果都不包含两者,插件认为无需进行混合MP4的转换。
- 文字遮罩区域是以
检查AE是否包含
YYConverterMP4模板,如果不包含,请参考YYEVA插件设计规范 进行模板配置,该步骤是为了扩充AE转换MP4的能力,进行一些渲染队列的相关配置。
3. 分析、处理设计师的图层相关数据
通过合法性验证后,插件开始解析设计师指定的合成。
- 遍历项目的合成,提取出 mask_text 和 mask_image 这2个遮罩合成,并分为 图片和文字 两大类型
- 分别遍历图片和文字2大类型中的所有有效图层,获取每个图层在每一帧的仿射矩阵:matrix
- 根据步骤2获取的仿射矩阵matrix,可以得到每一个图层在画布上每一帧的位置 renderFrame
1 | 具体计算方法如下:(以一个图片图层为例) |
对于 步骤4 的计算方法,如下图案例:

以上步骤即可以得到第一个关键数据 renderFrame ,即 mask 每一帧在屏幕上的位置数据
- 拷贝选中的合成,用于添加到渲染队列时使用的输出合成,防止在原合成上操作,影响到 原始 合成资源
- 针对拷贝后的输出合成,缩小 alpha 区域0.5倍,划分为三个区域:区域1、区域2、区域3
1
2
3
4
5
6
7
8
9
10例如 1800 * 1000的 视频
- 源合成
- 区域1. 左边 900 * 1000 存 rgb
- 区域2. 右边 900 * 1000 存 alpha
- 输出合成
- 区域1. 左边 900 * 1000 存 rgb
- 区域2. 右边 900 * 500 存 alpha
- 区域3. 右边 900 * 500 存 mask
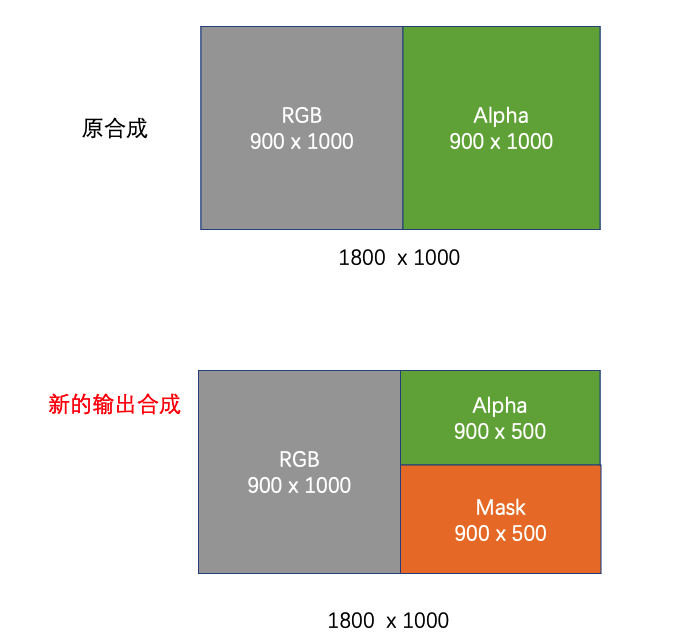
- 拷贝所有的有效遮罩合成到步骤4的输出合成的区域3
- 该步骤会将图片和文字遮罩下的所有图层,拷贝到输出合成的区域3中,并且需要动态调整 所有图层的大小 和 位置,并将大小和位置 存储在
outputFrame,用于之后能够通过outputFrame获取到这些遮罩的形状- 保存区域3的可容纳的宽高,用于判断是否足够容纳copy过来的图层
- 获取计算出的当前需拷贝图层的 renderFrame
- 计算从当前mask图层的位置 变换到 新的 beginX 和 beginY 位置的仿射矩阵
- 将mask图层的位置,应用 上步骤计算 的仿射矩阵
- 计算出拷贝后的mask图层的位置 mask_Frame ,并记录下来
- 更新 beginX 和 beginY 和 maxWidth 及 maxHeight
针对每一个Mask图层应用了上面的操作后,我们可以得到又一个关键的数据outputFrame,即Mask每一帧在输出上的位置数据
4、生成混合MP4 资源
通过步骤三相关的图层分析,我们可以得到如下内容数据
Mask在屏幕上的每一帧的位置renderFrameMaskcopy到拷贝合成中,每一帧的位置outputFrame- 将
renderFrame和outputFrame添加到一个Json数据结构里 - 使用 创建的模板
YYConverterMP4,将拷贝合成 添加到渲染队列中 - 使用
h264/h265的扩展功能, 将渲染生成的AVI资源 转成MP4资源 - 将 步骤3 的数据 用
zlib打包后,使用base64的方式存储 - 将生成的
base64数据,封装成如下格式 - 由于 H5 不会嵌入
ffmpeg库,因此 H5 提取Metadata段的方式依赖用正则匹配,因此我们的Metadata数据格式会加上前后缀yyeffectmp4json[[base64]]yyeffectmp4json,这样可以方便H5快速定位到Metadata段的数据
1 | var templateStart = "yyeffectmp4json[[" |
客户端测
客户端拿到了 混合MP4 资源后,需要将写入的 base64 提取出来,并解压缩数据,并结合解码后的每一帧数据,完成最终的渲染工作。
1. 提取 Json 数据
使用 ffmpeg SDK 或者 正则表达式 ,从 MP4 中提取出 Metadata 存储的 base64 数据,去前缀后后并通过 zlib 解包后,得到真正存储的 Json 数据
2. 获取解码后的渲染帧
对 MP4 的 Video Track 使用硬解后,得到解码后每一帧的 pixelBuffer
3. 根据Json数据和渲染帧数据,并结合传入的业务数据,完成上屏操作

性能数据
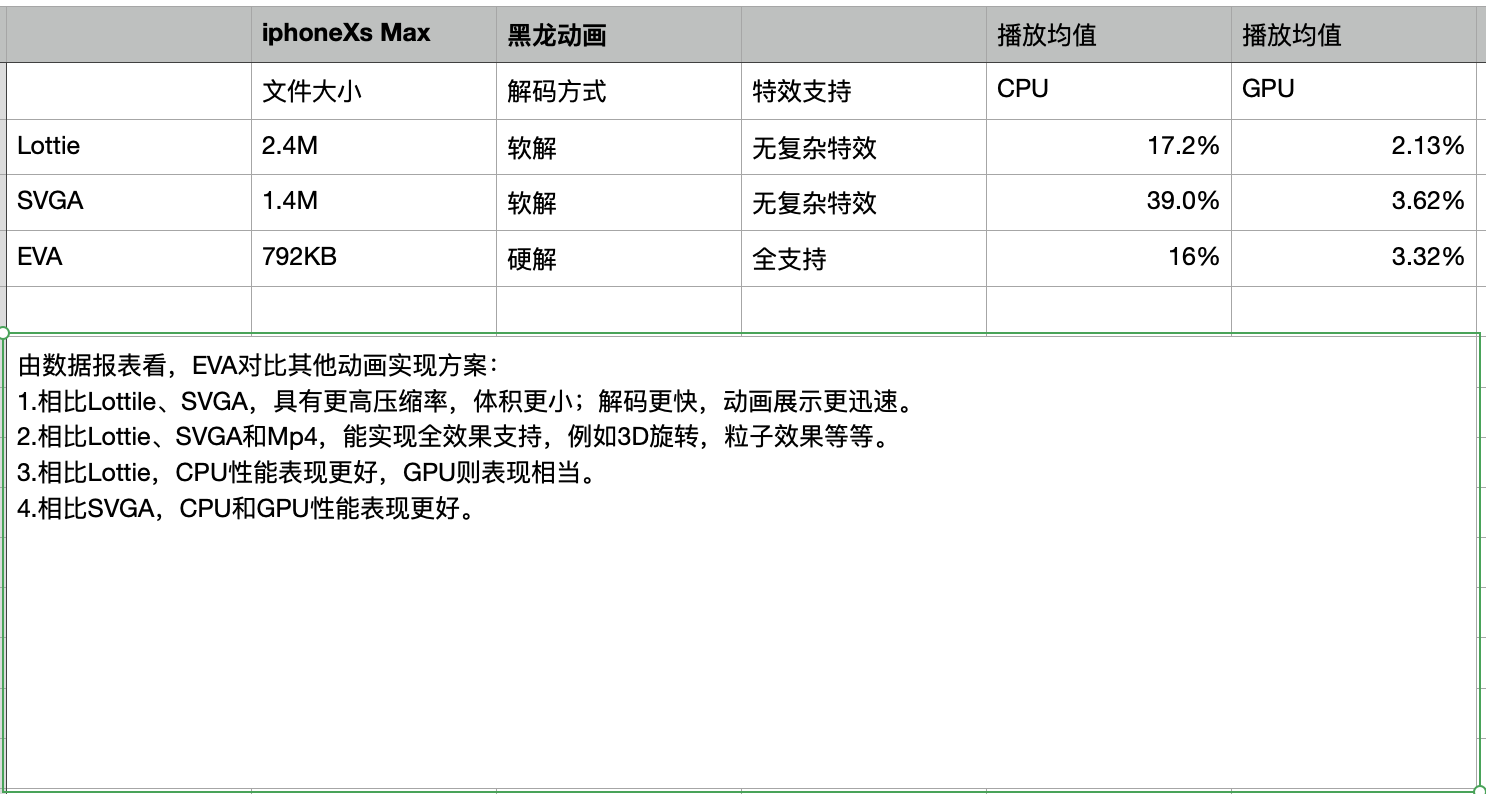
Json 数据结构定义
YYEVA设计规范
介绍
在 第四篇:YYEVA , 让MP4静态资源也能够动态起来 文章中有提到, YYEVA 包含一套完整的工具链,从设计端的资源输出,到资源预览,再到客户端的渲染 SDK 。本章内容主要是讲解 YYEVA 设计端的插件 YY-MP4 转换 是如何配置环境 和使用的。
YY-MP4转换 插件主界面
其中
h264/h265: 主要是为了扩充Adobe Effect After无法直接渲染出 MP4 而开发的一个子模块Dynamic: 主要是用来解析设计师的图层,导出一个混合MP4资源的子模块导出日志模块: 主要是快速导出解析和转换过程中的日志,方便排查插件的一些功能 BUG
插件 环境搭建
插件安装
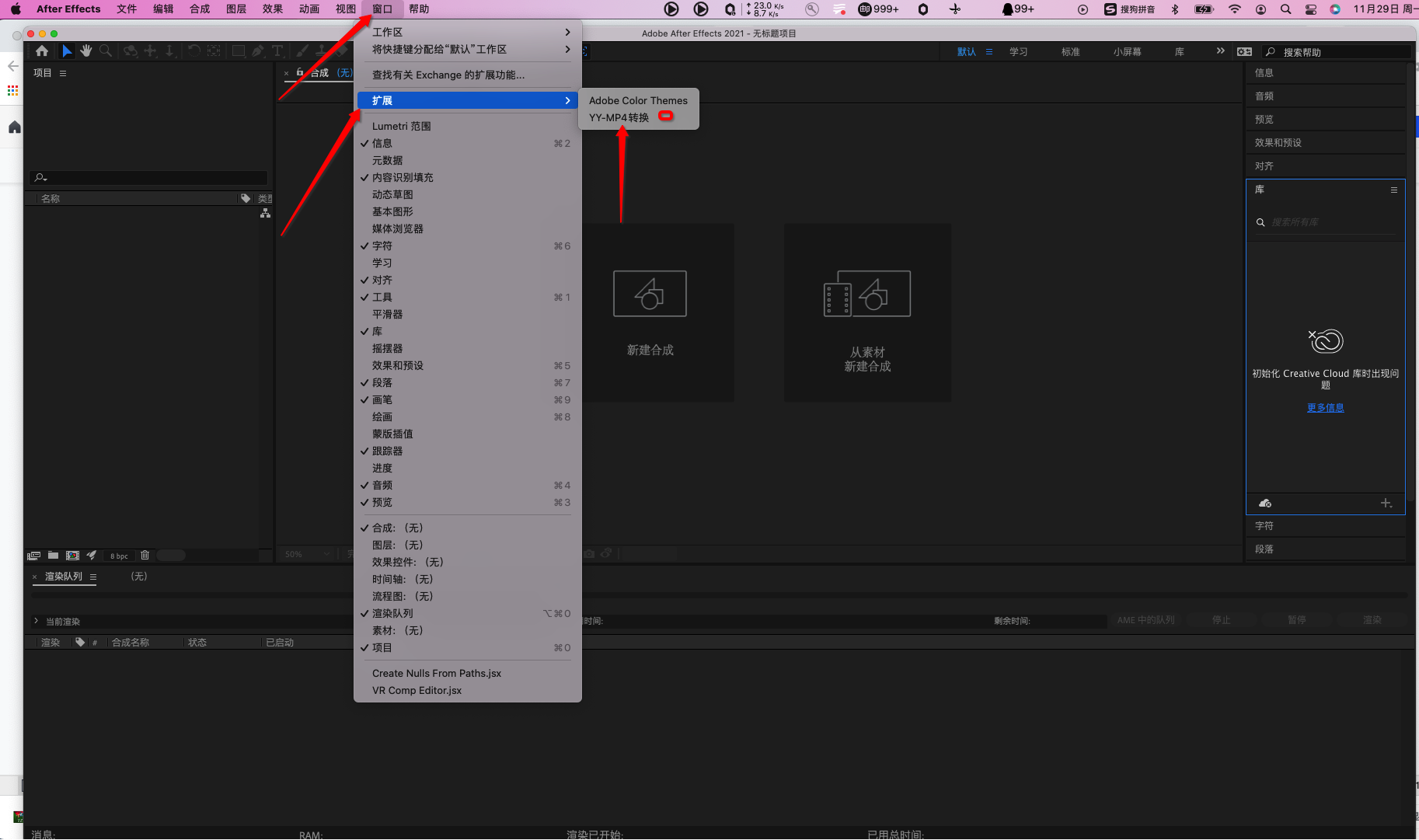
环境配置
- 创建
YYConvertMP4模板 。 重要步骤
- 打开AE,选择编辑 —-> 模板 —-> 输出模块
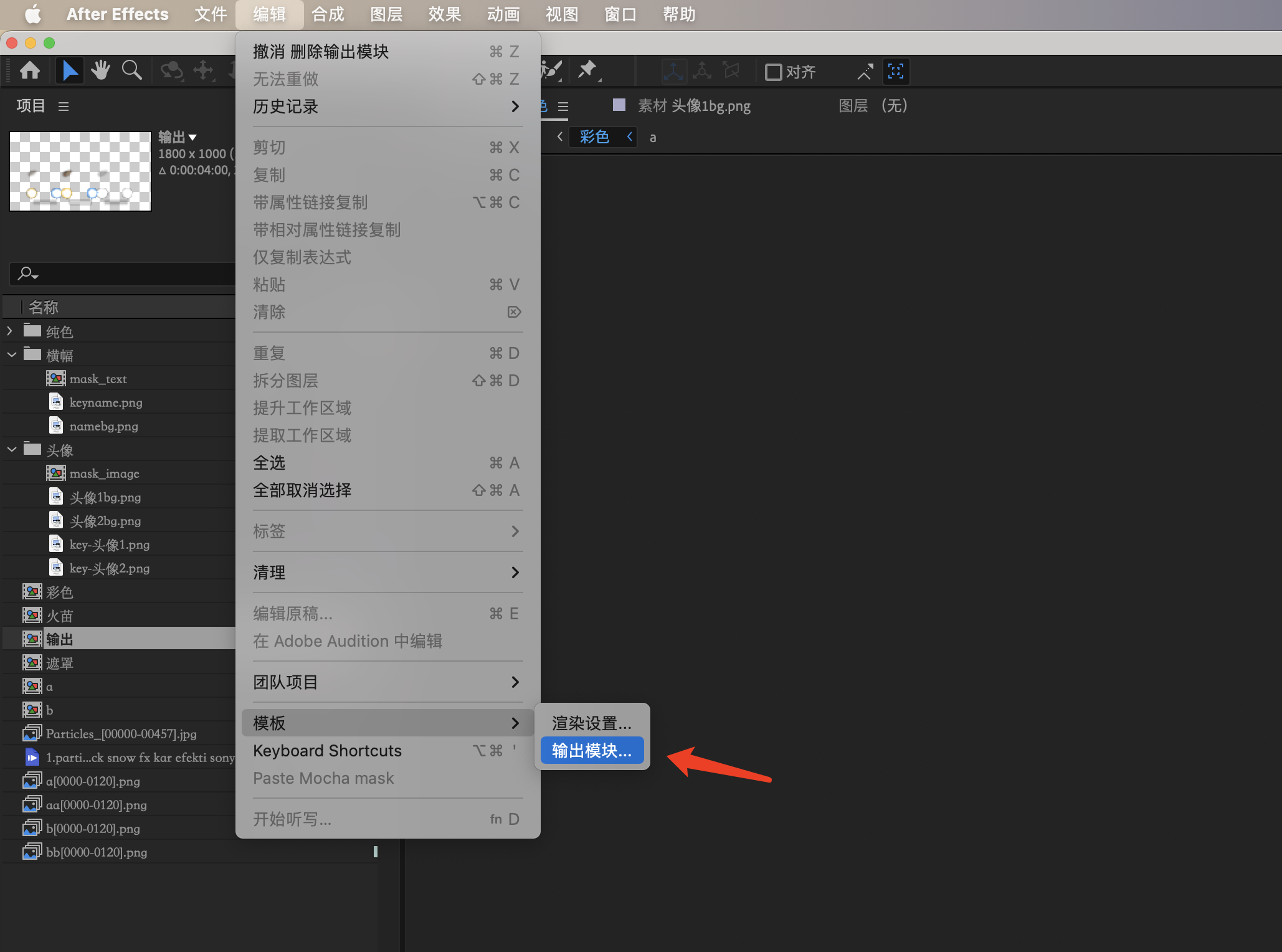
- 按如下步骤创建
YYConvertMP4输出模板
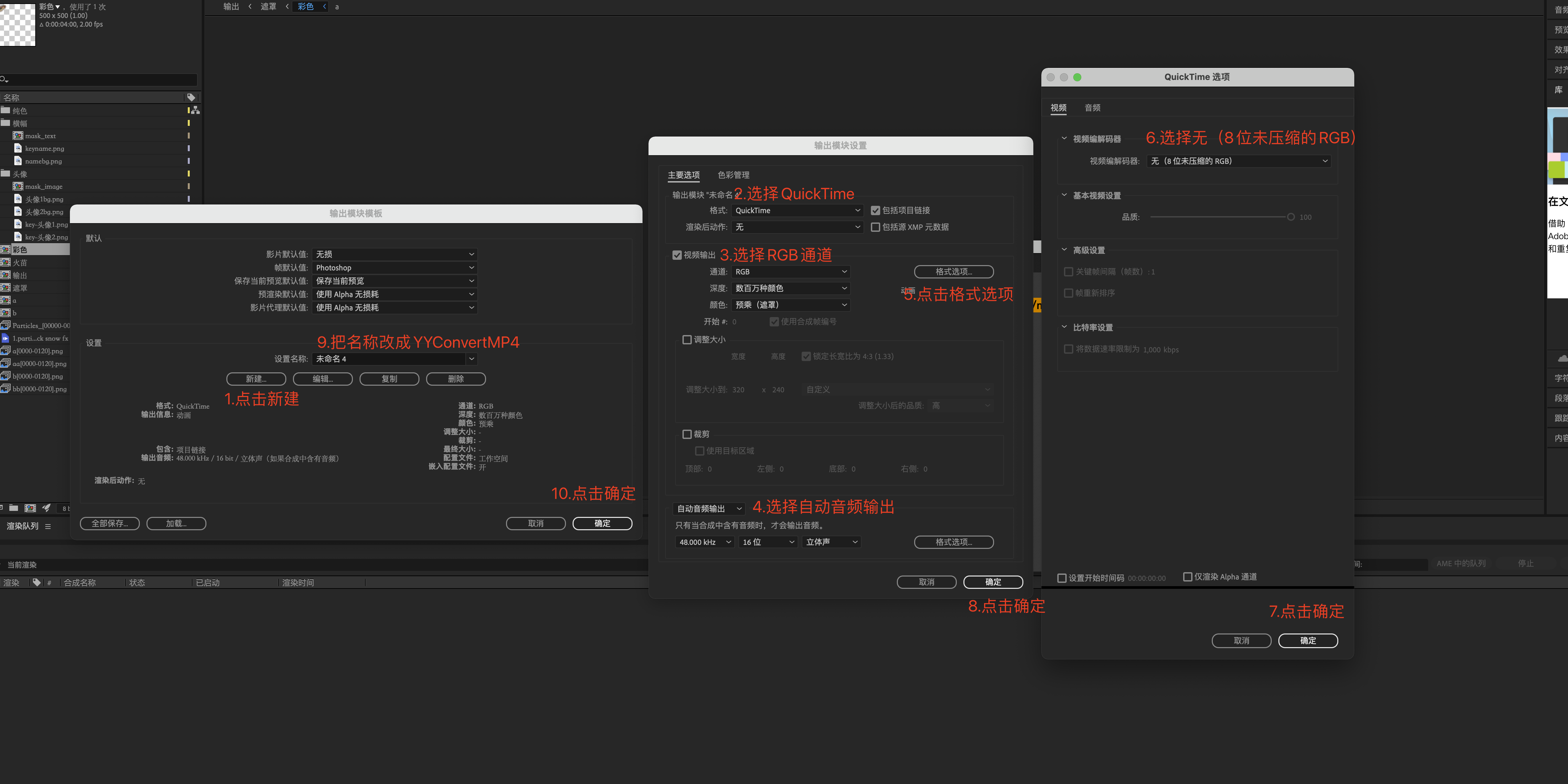
开启权限
- Mac
如图 : 打开脚本和表达式:
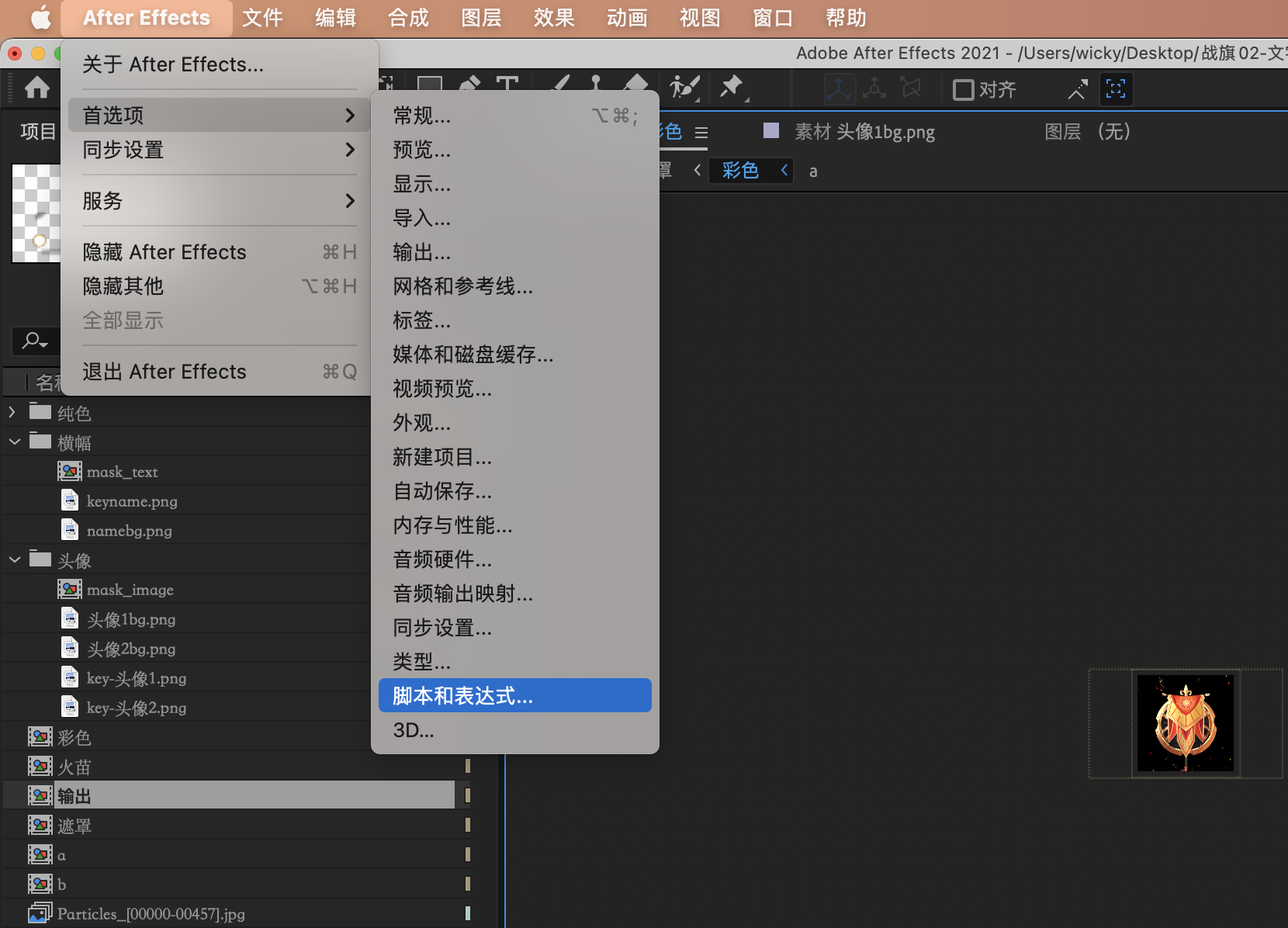
接下来勾选“允许脚本写入文件和访问网络”
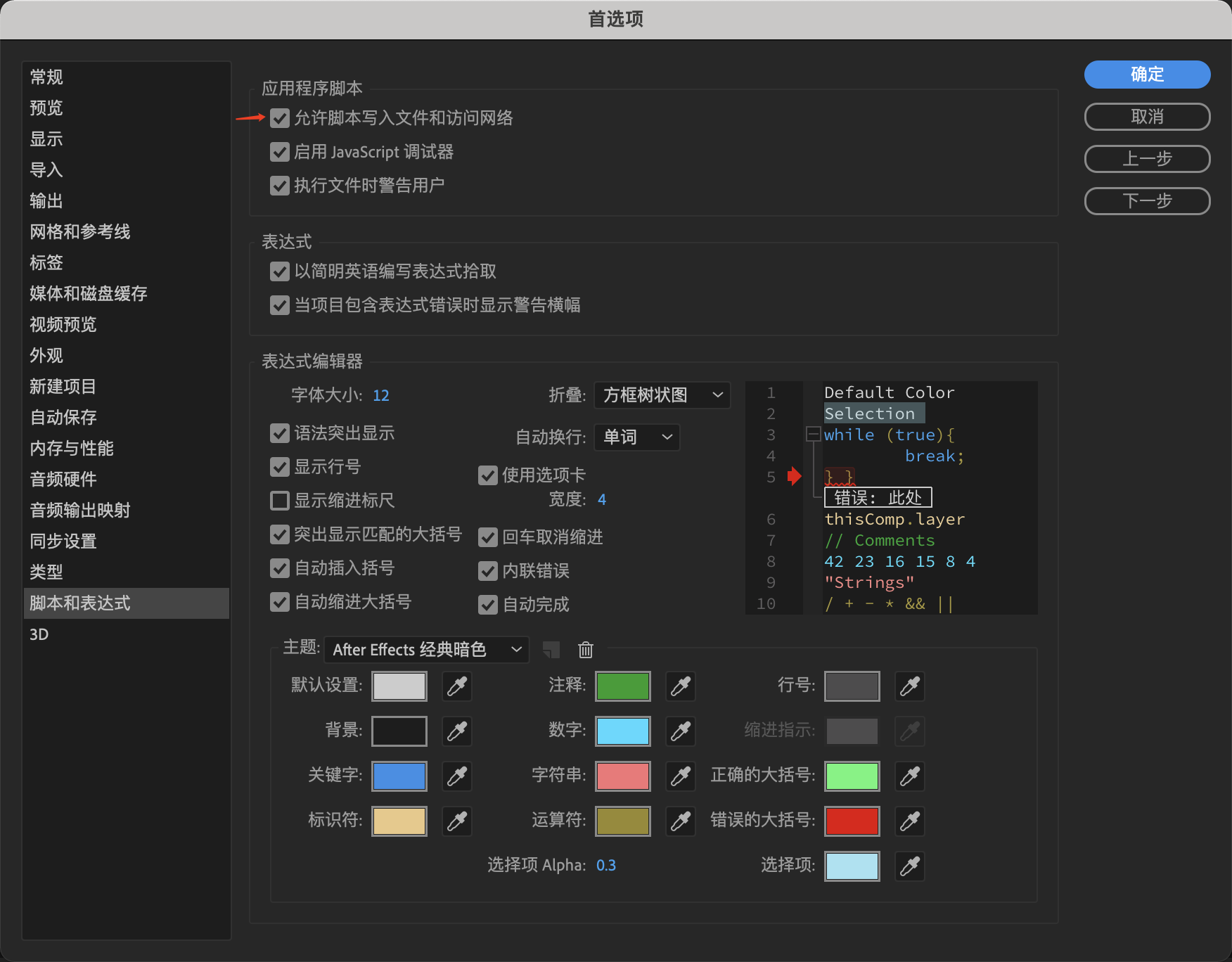
Windows
打开左上角编辑->首选项->脚本和表达式,打开窗口后勾选“允许脚本写入文件和访问网络”
插件使用
h264/h265模块 使用介绍
- 选中一个已经制作好的 普通透明MP4 输出合成
- 打开 窗口 -> 扩展 -> YY-MP4转换 工具
- 开始转换
* 设置输出路径
* 选择 视频质量 的档位 其中: 高档( CRF 18) 中档:( CRF 23) 低档:( CRF 28) , 自定义可以自行决定 CRF 的值
* 点击开始转换 - 资源输出 (会在指定的输出路径 : 资源输出 一套 MP4 资源,输出的文件名规范为 )
* h264 资源: 选择的合成name_normal_h264_档位.mp4
* h265 资源: 选择的合成name_normal_h265_档位.mp4
Dynamic模块 使用介绍
该模块主要是通过解析 Mask 合成,生成一个 带嵌入元素的混合 MP4 资源
1. 创建Mask 合成
插件会解析读取两种类型的 Mask 合成
mask_textmask_image
因此,如需制作文字类的遮罩,请添加一个 mask_text 命名的合成,如需制作图片类的遮罩,请添加一个 mask_image 命名的合成。
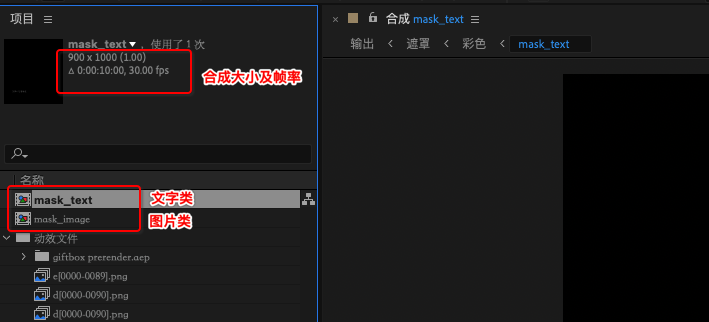
上图 创建了 2个 Mask 合成,这里需要注意 创建的规范是:
- 合成的命名必须是 mask_text 或者 mask_image
- 帧率要和输出合成的帧率保持一致
- 图层的大小 和 帧率 必须以输出合成帧率 及 rgb 区域的大小 保持一致
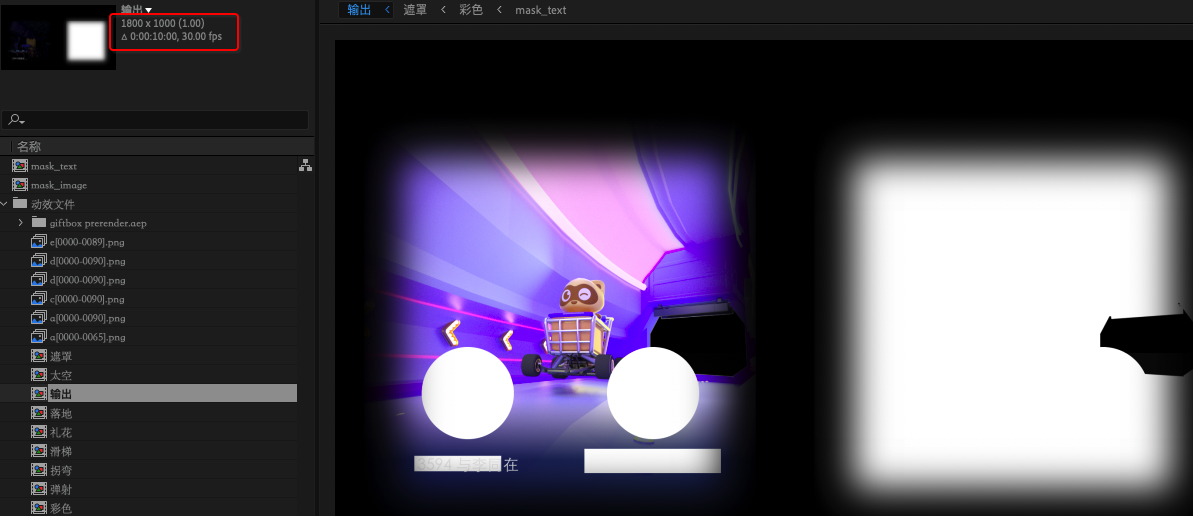
如上图,输出合成的大小是 1800 x 1000 ,其中 rgb 区域 是 900 x 1000,则 Mask 创建的合成也要是 900 x 1000
2. 制作 Mask 合成
- 制作
mask_text
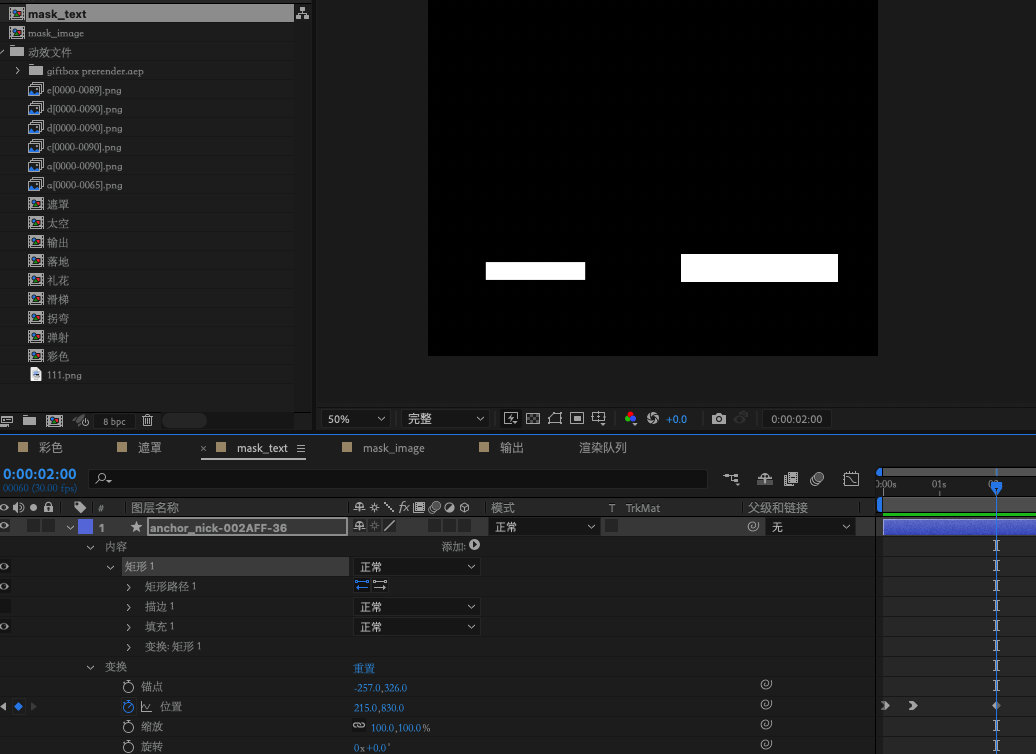
创建完mask_text合成后 ,就可以在该合成下面去制作”文字类”图层了,上图的案例中,我们创建了2个 矩形图层,分别代表的是插入的2个文字元素 以第一个图层为例
name : anchor_nick-002AFF-36
名称以 - 符号作为分隔 ,支持的格式 为 key - font-Color - font-size
1 | `key` : 客户端渲染时 , 索引该 `mask` 的名称 |
当客户端渲染时,会找到上面的key,来进行动态插入

- 制作
mask_image
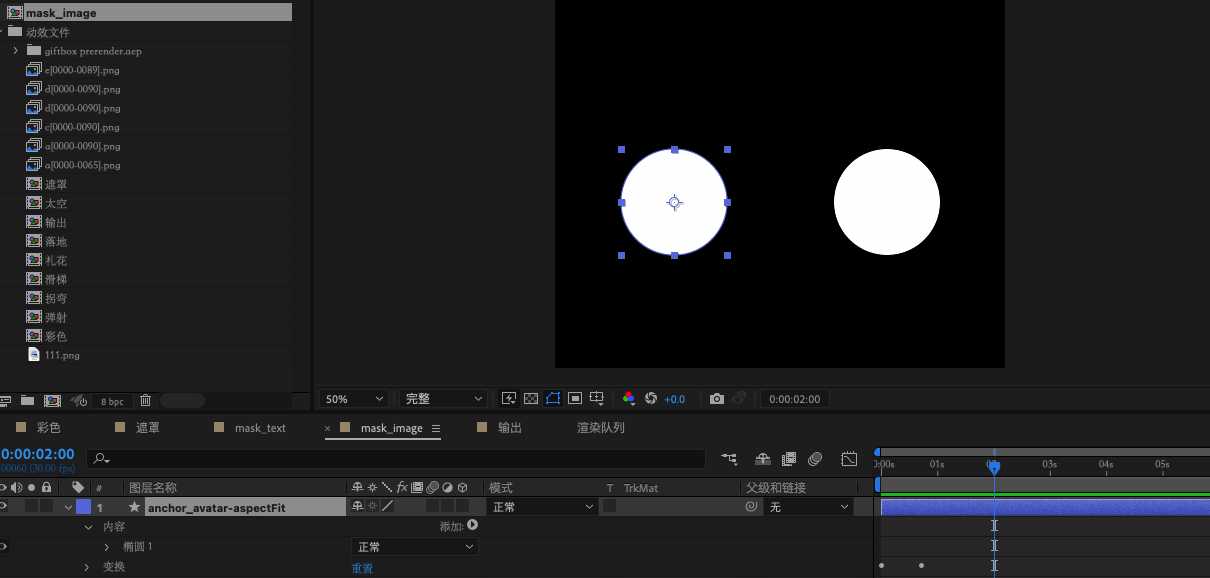
创建完`mask_image`合成后 ,就可以在该合成下面去制作"图片类"图层了,上图的案例中,我们创建了2个 椭圆 图层,分别代表的是插入的2个图片类的元素 以第一个图层为例
`name` : anchor_avatar-aspectfit
名称以 - 符号作为分隔 ,支持的格式 为 key - scaleMode
1
2
3
4
5
key : 客户端渲染时 , 索引该 mask 的名称
scaleMode : 图片放缩时的模式
* aspectFill 保持图像的纵横比并将图像缩放成将适合背景定位区域的最大大小。
* aspectFit 保持图像的纵横比并将图像缩放成将完全覆盖背景定位区域的最小大小。
* scaleFill 不保持图像的纵横比,铺面背景区域。
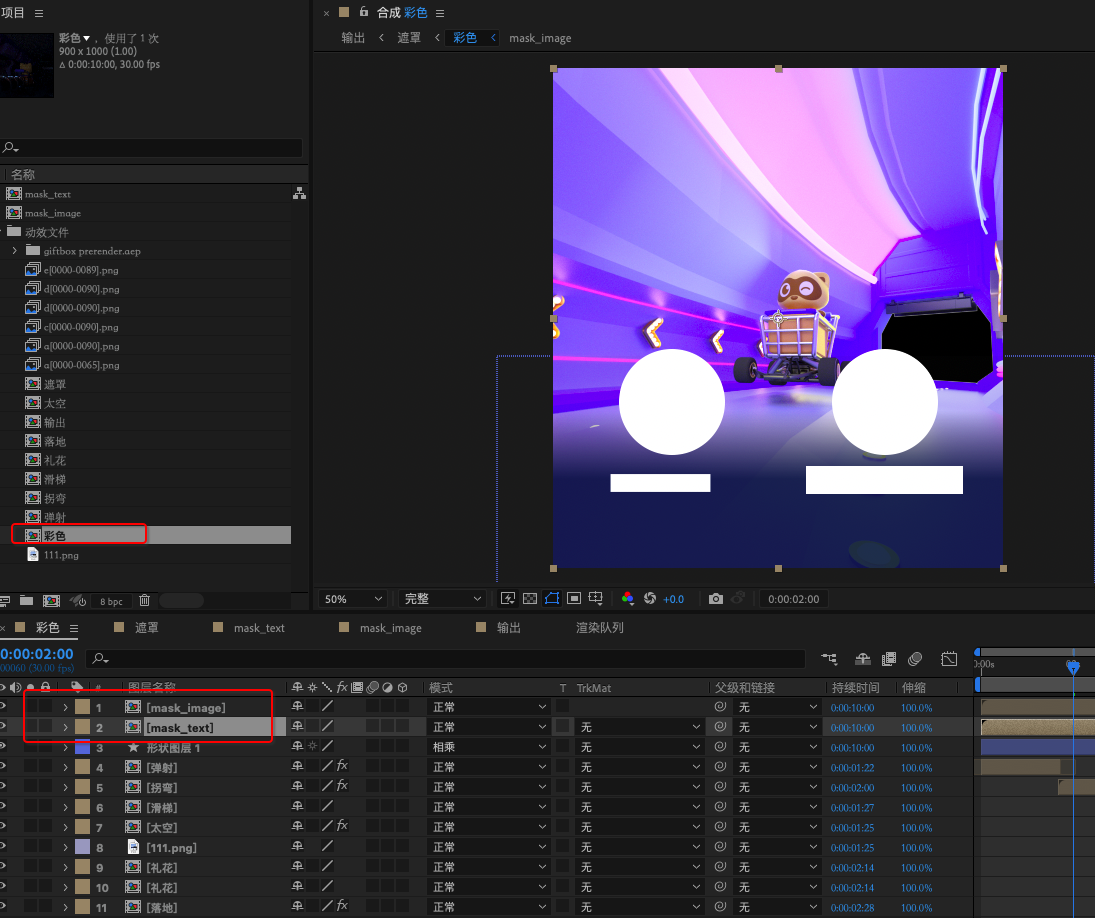
3. 在RGB的合成上引用2个Mask合成
在 rgb 合成上,需要引用刚刚制作好的两个 Mask 合成,即关联上了这2个 Mask
4. 使用插件 导出资源
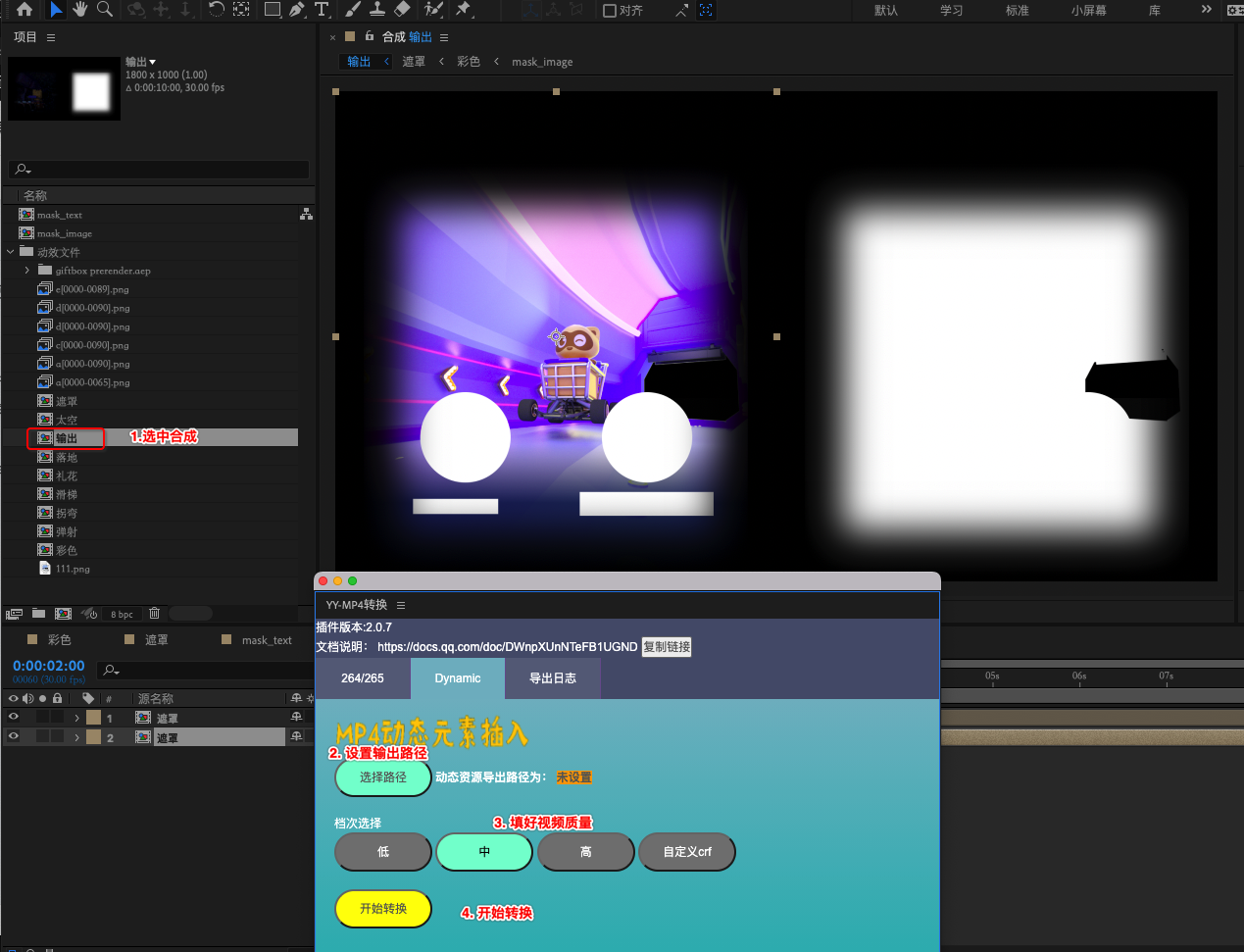
等待转换完成后,会在指定的输出路径,得到2个 混合 MP4 资源
- h264 : 输出合成的name_dynamic_264_mid.mp4
- h265 : 输出合成的name_dynamic_265_mid.mp4
设计同学可以在预览界面,预览该合成视频
在该预览界面下,将输出文件拖入预览区域,即可看到当前视频包含的可嵌入的元素 的 key 及类型
可以使用文章末尾的提供的混合 MP4 资源文件,试试看效果哦~
YYEVA-docs
介绍
- YYEVA加载的Json数据经过了 zlib压缩,再转成base64
- 转换后的数据是写在MP4的Metadata段
格式规范
1 | { |
字段概况
Json数据 包含三层:descript/effect/datas
- descript:描述该资源的整体信息
- effect : 描述 该资源下的所有遮罩相关信息
- datas : 描述 每一帧遮罩的位置信息
详解
descript
描述该资源的整体信息
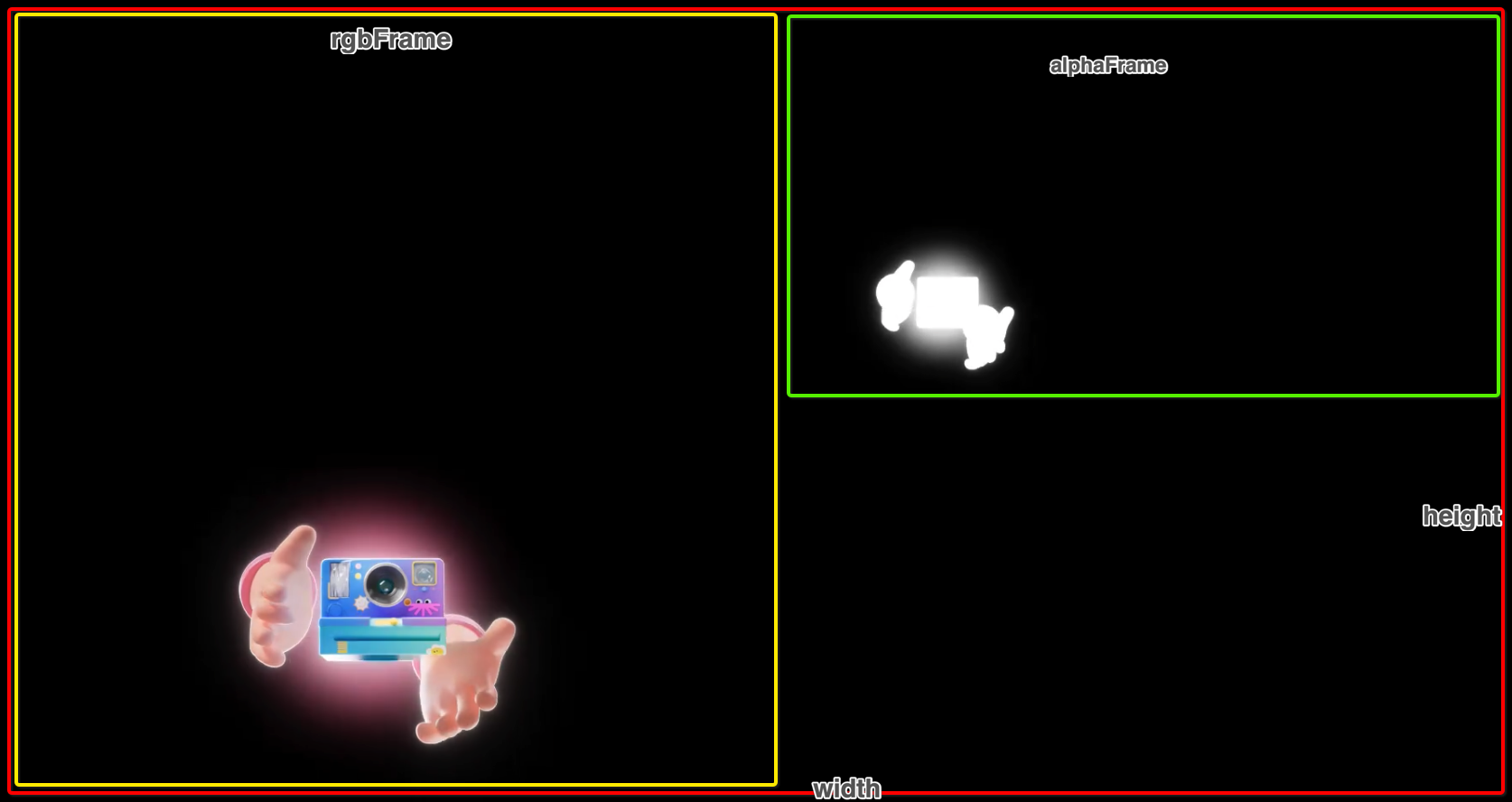
- widthheight描述 该输出视频的 分辨率大小
- isEffect代表该视频是否是一个 支持动态插入元素的 MP4资源
- version 代表 插件的版本号
- rgbFrame代表的是 视频的 R G B 部分在整个视频区域的 位置信息
- alphaFrame代表的是 透明区域 部分 在整个视频区域的 位置信息
effect
该字段 描述 该资源下的所有遮罩相关信息。 每一个遮罩,都会有一个元素在该字段保存下来,用于描述遮罩的类型相关信息
目前遮罩分为两大类型: 图片 文字 ,可根据effectType 来判断
- 基本属性
- effectWidth 、 effectHeight 代表该遮罩元素的原始宽高
- effectId遮罩ID
- effectTag 用于客户端索引该遮罩元素的Key值
- effectType 用于判断该遮罩是文字类型 还是 图片类型
- 特有属性
- 文字类型 (effectType == txt)
fontColor 当为文字的时候,表示客户端渲染时 需要指定的文字颜色
fontSize 当为文字的时候,表示客户端渲染时 需要指定的文字代销 - 图片类型 (effectType == img)
saleMode为图片适配客户端的显示区域时的拉伸方式,取值有三种类型- scaleFill 不保持图像的纵横比,铺面背景区域 ,默认模式
- aspectFit 保持图像的纵横比并将图像缩放成将完全覆盖背景定位区域的最小大小。
- aspectFill 保持图像的纵横比并将图像缩放成将适合背景定位区域的最大大小。
datas
** 描述 每一帧遮罩的位置信息 **
每一帧的每一个遮罩元素,都会存在一个数据段,用来描述该遮罩元素,在该帧下应该如何显示
- frameIndex代表当前是第几帧的数据
- data当前帧下的所有遮罩数据
- effectId表示该数据归属于哪一个遮罩,和effect下的effectId对应 ,可以在 effect下索引到对应的遮罩信息
- outputFrame表示该遮罩在该输出视频区域的位置信息
- renderFrame表示该遮罩在 渲染画布上的位置信息