C++ 异常处理机制 try catch 在快手 App 内突然失效,引发大量未捕获异常导致的崩溃。本文介绍稳定性团队排查此次问题的过程,问题的根本原因以及修复规避方案,最后梳理异常处理流程,知其然,知其所以然,方能在问题出现时冷静应对。
背景介绍
快手 App iOS 端在最近的一个版本上线前, 自动化测试流程上报了非常多 C++ 未捕获异常(invalid_argument 、out_of_range 等)导致的崩溃,崩溃堆栈在版本周期内并没有修改记录,并且在崩溃的代码路径上存在 try catch 语句,catch 语句声明的异常类型是 exception。
invalid_argument 和 out_of_range 都是 logic_error 的子类,logic_error 是 exception 的子类。
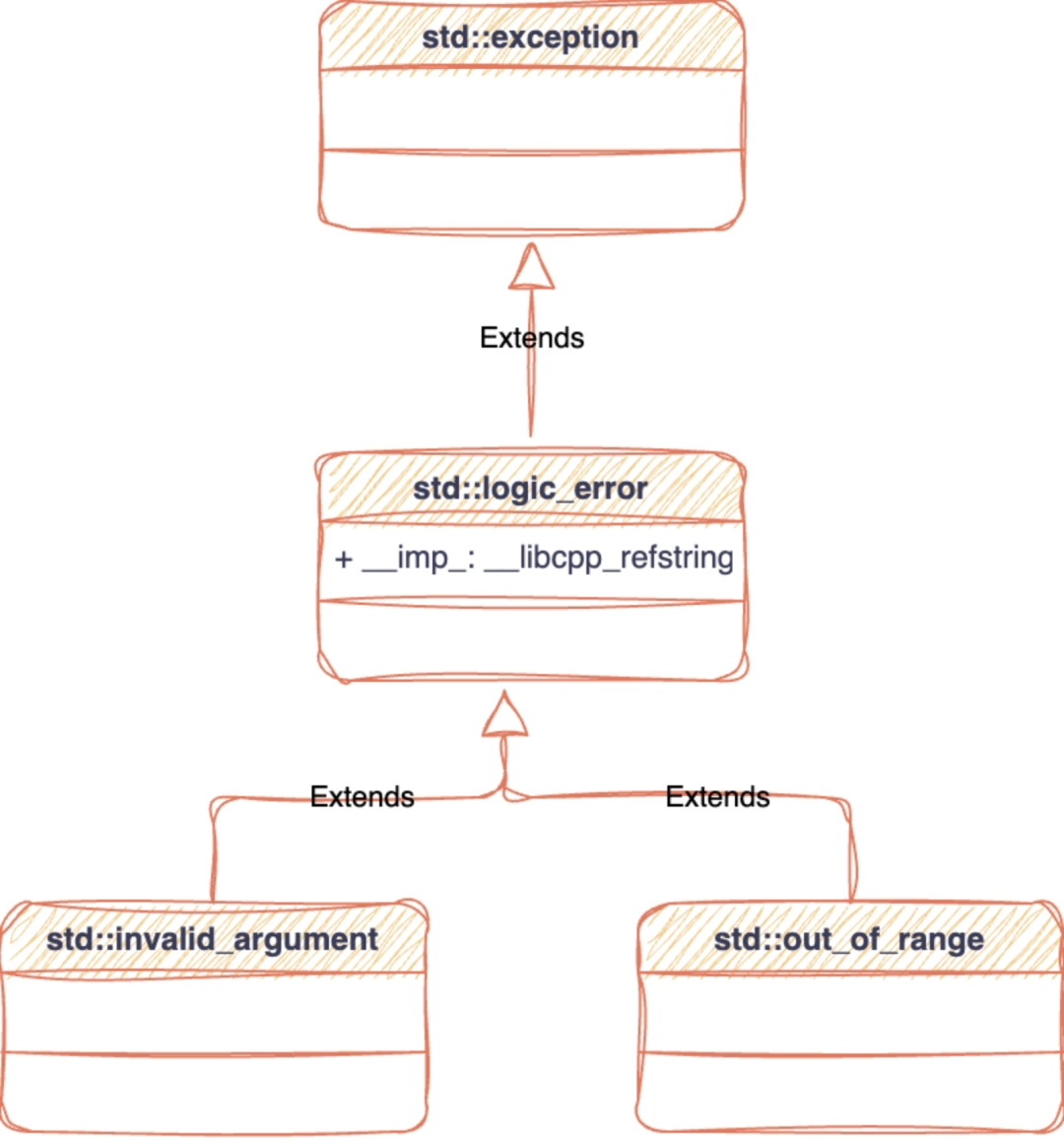
根据 try catch 的工作原理,catch 语句声明 exception 可以捕获子类
out_of_range 和 invalid_argument。
catch <type> @ExcType
This clause means that the landingpad block should be entered if the exception being thrown is of type @ExcType or a subtype of @ExcType. For C++, @ExcType is a pointer to the std::type_info object (an RTTI
object) representing the C++ exception type.
以 mmkv 的崩溃堆栈为例,readString 方法抛出了 std::out_of_range,这个异常应该在 decodeOneMap 方法内被捕获,而不应该触发崩溃。
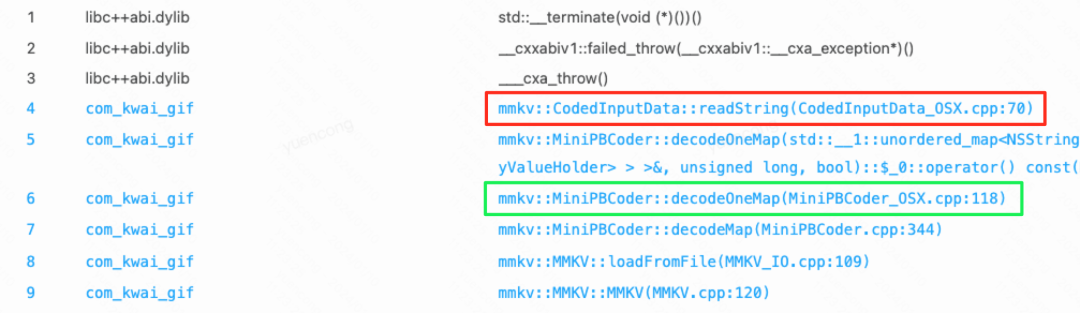
mmkv::CodedInputData::readString 抛异常代码:

mmkv::MiniPBCoder::decodeOneMap 中捕获异常代码: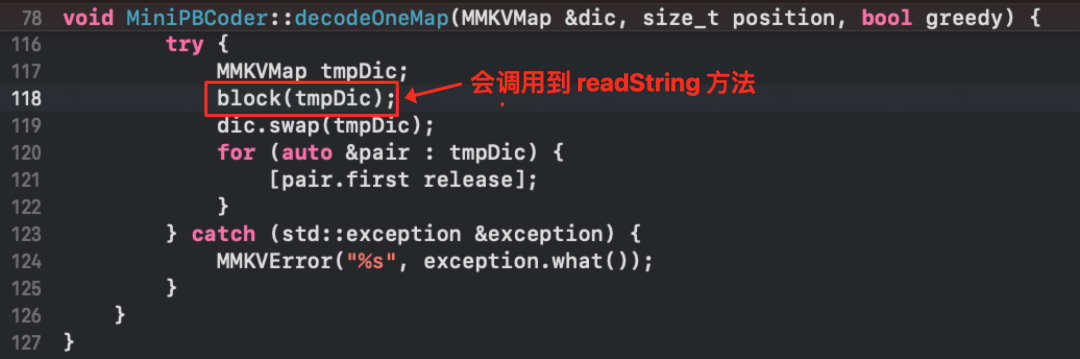
debug 线上的版本,124 行可以正常输出错误日志,在 mmkv 没有任何改动的情况下,自动化测试版本 catch 语句不能正常捕获异常了。
排查过程
本人王者荣耀钻五选手,对这个游戏有着相当深刻的理解,接下来的排查过程就以一局游戏为例吧。(真实原因是起一个段落标题和函数命名一样困难!)
全军出击
同样深入理解游戏的人脑海中已经有了画面,游戏开局,小兵缓缓抵达了战场,小鲁班 A 了一下兵线,first blood 人没了……
mmkv 里面的崩溃堆栈简化后如下所示:
1 | void throw_exception() { |
这段代码在 demo 工程里面运行,使用 exception 类型可以 catch 子类型 out_of_range。但是把相同的代码复制到快手 App,catch 语句不会执行。当时怀疑和快手 App 的编译选项改动有关,找到架构那边的同学,确认编译参数近期没有任何改动。
21 年年底处理过一次 try catch 失效导致的崩溃,这种超乎常理的问题总是令人印象深刻。上次的原因是 hook 系统方法 objc_msgSend 后没有添加 CFI 指令,导致 unwind 回溯到 objc_msgSend 后中断,无法继续向上查找调用栈中的 catch 语句。所以在排查这个问题时首先想到的是判断 unwind 流程是否正常。这个判断用代码比较容易实现,测试用例里面,新增一个 catch 语句,捕获具体的子类,然后在快手 App 运行。
1 | try { |
运行上述代码后,执行了第二个 catch 块,out_of_range 捕获了 out_of_range,说明 unwind 流程是正常的,可以回溯到 try catch 语句。
测试用例中运行结果同时表示:
- out_of_range 实例 is type of out_of_range 成立。
- out_of_range 实例 a subtype of exception 不成立。
第二条显然不符合预期,所以在快手 App 内异常没有被捕获的原因是判断 exception 和 out_of_range 的继承关系时存在错误。尝试使用 is_base_of 在快手 App 内判断 out_of_range 是否是 exception 的子类,返回的结果 rv 是 true。
1 | bool rv = std::is_base_of<std::logic_error, std::out_of_range>::value |
然而,在异常处理流程中,判断 catch 的 exception 类型是否能匹配抛出子类型 out_of_range 异常时是通过 is_base_of 方法吗?这个问题现在来看比较低级,但是在当时缺少对整个异常处理流程的认知,不知从何处开始调试,只能暂时放下这个问题,开始其它方向的排查。
请求打野支援
一顿操作猛如虎,一看战绩 0-5。打野,速速来 gank!
这是一个新增并且可以稳定复现的崩溃,因此一定能够查找到是哪个 MR 引入的。稳定性组的两个同事,从出现崩溃的 commit 开始二分查找之前一天的
MR,最终锁定了动态库改静态库这个提交 ,这个提交 merge 之后构造的测试用例可以复现崩溃。之后根据自动化流程上报的堆栈,修改 mmkv readString 方法,调用即抛出 out_of_range 异常,在 decodeOneMap 方法内异常没有被 catch,实锤了是这个 MR 引入的问题。
这个 MR 并不复杂,修改点不多,将部分动态库改为静态库集成到快手 App。里面删除了一些动态库的编译选项,和 C++ 相关的只有一个 CLANG_CXX_LANGUAGE_STANDARD,用于指定 Clang 编译器在编译 C++ 代码时所使用的语言标准。


虽然定位了问题引入的 MR,但是此时根据代码 diff 还是看不出具体的原因。
集合准备团战
不是一个人的王者,而是团队的荣耀!
动态库改静态库是最近一次活动必须要上的需求,否则会存在 ANR 影响活动效果,所以定位到的 MR 不能被直接回滚。周四就要提审,这个问题不被解决一定会阻塞提审流程,影响到活动版本的覆盖率。
周三晚上,稳定性组的负责人开始组织整个组同学参与进来一起讨论解决方案。在这次讨论中,首先排除了一个方向: 代码 diff 中删除动态库的 C++ 版本对快手 App编译环境无影响。之后初步梳理了 C++ exception handling 的逻辑,明确崩溃场景下使用 __gxx_personality_v0 routine 方法来判断栈帧是否能 catch 异常。之后 debug __gxx_personality_v0 得出了一个非常关键的信息,导致 try catch 失效的直接原因是快手 App 内多了一份 exception 的 type_info:
std::exception 的 type info 对不上,name 都是一样的,但是一个在 libc++abi.dylib, 一个在快手 App内,正常应该都会在 libc++abi.dylib,也就是说快手 App多了一份 std::exception 信息。
在定位到直接原因后,接下来开始查找 std::exception 的 type_info
是被哪个编译 target 引入快手 App的。image lookup 可以查看 type_info
指针地址详细的信息:
1 | (lldb) image lookup -a 0x000000010396c970 |
0x000000010396c970 存储在 __DATA.__const 段, __DATA.__const 是一个特殊的 section,用于存储只读的常量数据,在一般情况下,__const section 中存储常量的顺序是按照它们在源代码中出现的顺序来排列的。尝试查看 0x000000010396c970 这个地址附近存储的信息。
1 | (lldb) image lookup -a 0x000000010396c978 |
在 0x000000010396c970 - 0x10 的位置找到了 Runtime::JSState。Runtime 这个符号在组件 dummy 内定义。取 dummy 的编译产物 libdummy.a,发现 .a 里面 const 段,存在 exception 的 type info。
1 | 00000000000070b0 (__DATA,__const) weak private external __ZTISt9exception |
1 | ➜ Exception git:(main) ✗ c++filt __ZTISt9exception |
测试 demo 工程依赖组件 dummy 后编译,使用 exception 无法 catch out_of_range ,实锤了是这个组件引入的问题。在 podspec 里面查看 dummy
的编译选项,发现禁用了 RTTI,在 Xcode 里面将这个选项修改为 YES 之后,try
catch 失效导致的未捕获异常崩溃不再复现。
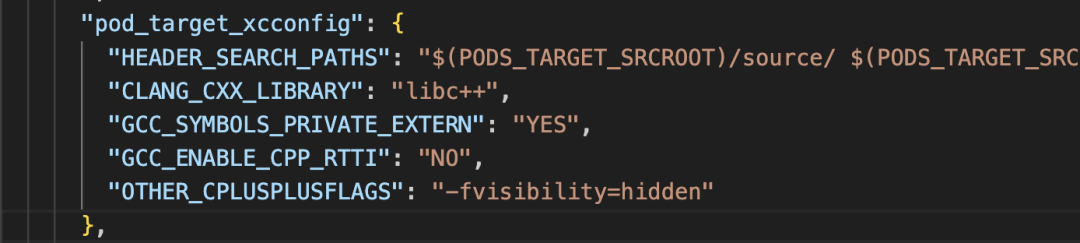
dummy 是这次动态库改静态库的需求中,改动的动态库间接依赖的静态库,主可执行文件之前不会直接依赖 dummy。宿主动态库以静态库方式集成到快手 App后,dummy
同样以静态库的方式集成到快手 App,导致 std::exception 的 type_info 被引入主可执行文件。定位到了引入的子库 dummy 和 try catch 失效的原因后,接下来就是查找对应的解决方案。
VICTORY
敌方水晶已被击破!
方案 1
最快速的修改是将 dummy 编译选项 GCC_ENABLE_CPP_RTTI 修改为 YES,但是因为其特殊的业务场景不允许被修改。
方案 2
dummy 删除 std::exception 的依赖。最终以失败告终,libdummy.a 仍然存在 exception type_info,当时应该是没有删除干净,仍然存在 exception 的子类。
方案 3
这个方案和方案 2 在同步进行。崩溃的直接原因是动改静之后,将 dummy 集成到了快手 App,导致主可执行文件多出了一份 std::exception。虽然不能将全量的动态库回滚,单独将 dummy 回滚为动态库也能解决问题。
方案 4
反向修改。在查看 libdummy.a 符号时,发现这个库同时存在 exception 的子类 std::bad_alloc 的 type_info,在快手 App内使用 exception 可以 catch bad_alloc,说明父类和子类都在主可执行文件时,try catch exception 也可以捕获子类。如果 dummy 包含了所有的子类,try catch 失效的问题也能解决。这个方案虽然能修复我们遇到的问题,但是我们无法评估这样的修改是否会产生额外的影响。
方案 5
事后我手同事又提供一个解决方案,添加如下cflags:set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -D_LIBCPP_TYPEINFO_COMPARISON_IMPLEMENTATION=2"),添加之后,即使存在两份 type_info,type_info 的判等可以走到 strcmp 的逻辑里面。
最终选择了方案 3,风险最低,不会影响业务逻辑,并且修改的时间成本较低。方案 3 并不是把 try catch 失效的影响范围缩小到了dummy 里面,根据方案 4 的原理,方案 3 并不会导致 dummy 内的 try catch 失效。最终由架构组同学负责修改,修改后验证可行。
复盘
段位在钻五之上的人一定是懂复盘的,要从之前胜利的对局中吸取经验,这样在以后的对局中才能一直赢,一直赢,守住钻五的牌面。
try catch 失效的问题虽然被解决了,但是排查过程中遇到的一些问题还没有找到答案。从稳定性的角度出发,首要问题是理清 C++ 异常处理机制,exception handing 如何查找 catch 块以及判断 catch 块是否匹配正在抛出的异常?在问题解决后,查阅了一些资料,对 C++ 异常处理机制有了一些基本的了解。
在函数调用栈帧中每个函数都对应 1 个或者 0 个 exception table,里面包含了这个函数内不同的 PC 区间可以 catch 的异常类型,以及 catch 后的跳转地址,在异常抛出时,查找调用栈中可以捕获抛出异常的栈帧时,会依次使用调用栈中不同的栈帧对应的 exception table,根据栈帧跳转时的 PC,匹配栈帧 exception table 内记录的地址区间,找到这个区间可以 catch 的异常类型,使用这个类型来判断是否能 catch 抛出的异常,如果可以 catch 则跳转到区间对应的跳转地址,继续执行 catch 块的代码,否则继续查找上一个栈帧。
接下来将结合具体的 demo 用例、编译产物、源码和大家一起分享下异常处理流程。
throw
从 throw 说起,编译时 throw 会被替换为 __cxa_throw, __cxa_throw
会调用 _Unwind_RaiseException, 如果_Unwind_RaiseException 未找到捕获当前 exception 的 landing pad 或者在查找过程中出现错误,会 return。return 后 __cxa_throw 方法继续执行 failed_throw,failed_throw 内执行__terminate。查找到可以捕获异常的 landing pad 之后会跳转到对应的地址,不会 return 也就不会触发崩溃。
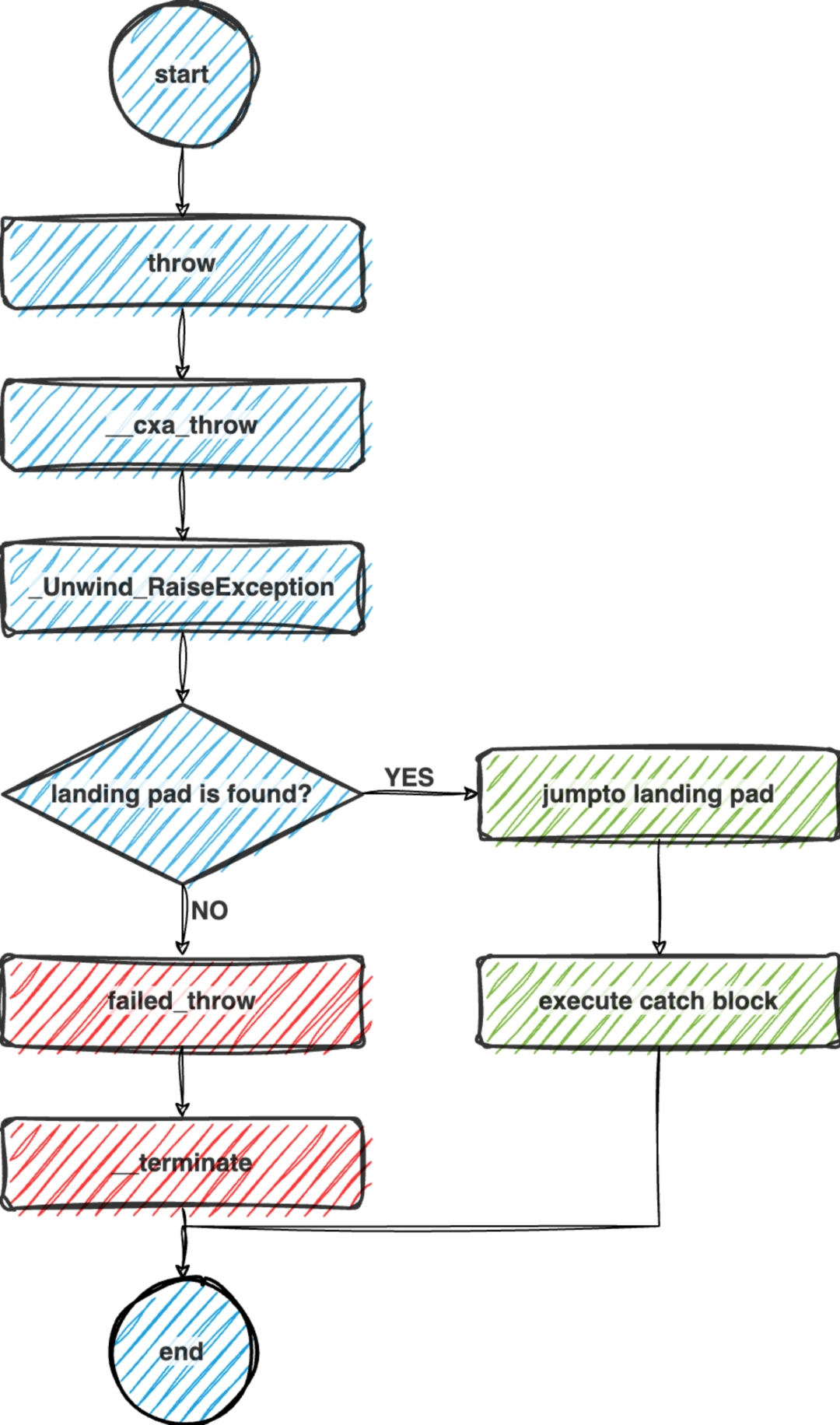
这里的 landing pad 可以理解为当异常捕获时继续执行的函数调用入口,这个函数接收两个参数 exception structure 和 exception type_info 在 typetable 中的索引。在 landing pad 函数内会根据 type_info 的索引值来决定具体执行的 catch 块。landing pad 的另一个语义是 cleanup 调用入口。
_Unwind_RaiseException
_Unwind_RaiseException 包含了异常处理的两个核心流程 phase1 和phase2,对应 search 和 cleanup。
在异常抛出时,需要遍历栈帧,查找可以捕获异常的 catch 语句。search 阶段使用 libunwind 依次回退栈帧,恢复寄存器信息,并根据 PC 二分查找 __unwind_info,获取栈帧对应的 personality 函数,以及执行 personality 函数依赖的 exception table -- LSDA(Language Specific Data Area)。之后调用 personality 解析 LSDA 来判断当前栈帧是否能 catch 异常,如果可以会记录栈帧相应的信息。
search 阶段如果没有查找到可以处理异常的栈帧,会返回到 __cxa_throw
方法内,执行 terminate,查找成功会继续执行 cleanup 阶段。当异常发生时,从 throw 到 catch 之间的函数执行中断,cleanup 等价于在函数退出时执行的清理操作。以下面的代码为例,A 调用 B,B 调用 C,A catch C 抛出的异常,在 B 调用 C 之前定义了 m_cls。未发生异常时 m_cls 在函数末尾触发析构方法,异常发生时 B 函数执行中断,m_cls 在 cleanup 阶段执行析构方法。
1 | void funcC() { |
cleanup 会再次回退栈帧,并执行局部变量的清理,保证资源可以正常释放,当回退到 search 阶段记录的栈帧,会使用 search 缓存的跳转地址,执行 resume,实现 throw 到 catch 块的跳转。
异常处理流程为什么会拆分为 search 和 cleanup 呢?官方给出的解释如下:
A two-phase exception-handling model is not strictly necessary to implement C++ language semantics, but it does provide some benefits. Forexample, the first phase allows an exception-handling mechanism to dismiss an exception before stack unwinding begins, which allows resumptive exception handling (correcting the exceptional condition and resuming execution at the point where it was raised). While C++ does not support resumptive exception handling, other languages do, and the two-phase model allows C++ to coexist with those languages on the stack.
两个阶段的异常处理模型对于 C++ 并不是严格必需的,但是它可以带来一些好处。比如,第一阶段允许异常处理机制在栈帧展开之前消除异常,这样可以进行恢复式异常处理(对异常情况进行修复,然后在抛出异常的地方继续执行),虽然 C++ 不支持恢复式的异常处理,但其它语言支持,两阶段模型允许 C++
与那些语言在堆栈上共存。
在 search 和 cleanup 阶段,都需要依赖 LSDA 判断当前栈帧是否能 catch 异常,了解 LSDA 的数据结构对于理解异常处理流程至关重要。
LSDA
LSDA 包含 header, call site table, action table 和一个可选的 type table。判断当前栈帧是否能 catch 异常时,涉及到三次查表的过程,
- 根据当前栈帧的 PC 查找 call site table,获取地址区间匹配的的 call site。
- 根据 call site 记录的 action 索引值在 action table 取 action。
- 根据 action 中 type_info 的索引值在 type table 中取 type_info。
之后根据 type_info 判断是否能 catch 异常,是则记录(phase1)或者跳转(phase2)到 call site 中 lpad 字段记录的的 landing pad address。否则继续向上回溯栈帧,并重复上述过程。
LSDA 的数据结构如下图所示:
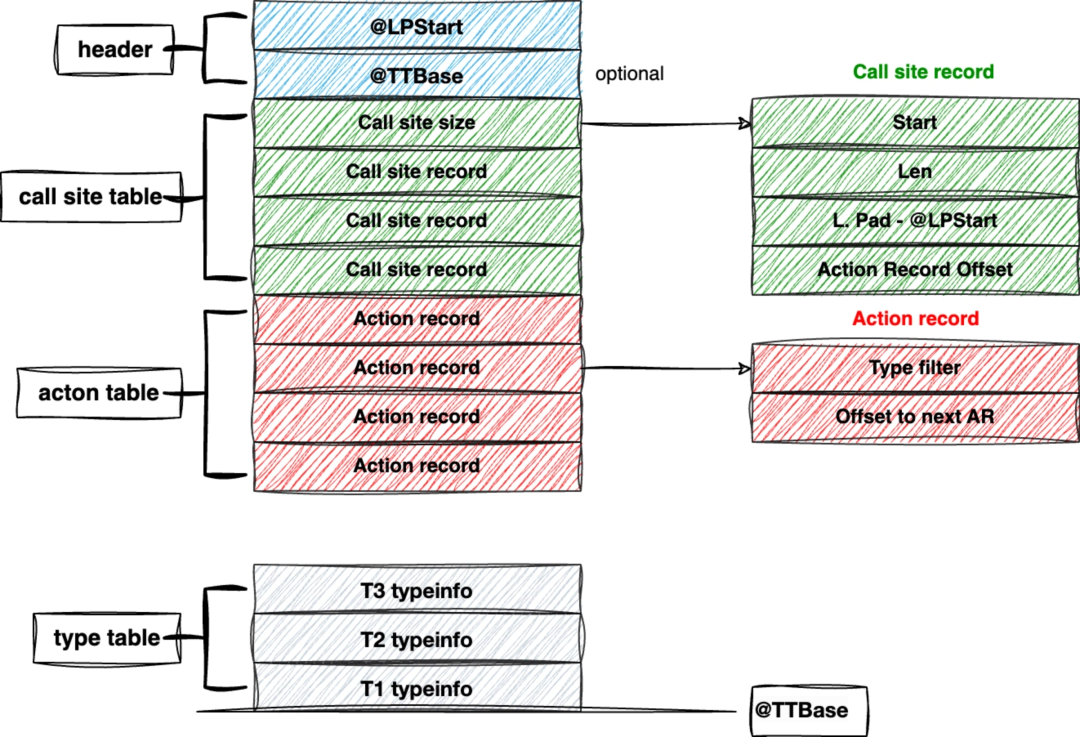
header
LPStart: 默认是函数的起始位置。
TTBase: 记录 type table 的相对位置。
call site record
start & len: 记录了可能会抛出异常的 PC 区间,这个区间是相对于函数起始位置的偏移量。
lpad: 记录匹配之后跳转的”函数地址” landing pad address 的相对位置。
action_offset: 记录 action table 中的索引值,action 用于查找 call site 能够捕获的异常类型。
action record:
filter:记录了 catch 块中异常类型的 typeinfo 在 type table 中的索引。
next_ar:指向下一个 action 或者 end,如果 filter 类型不匹配,则继续查找 next_ar。遍历到 end 未找到匹配的 filter 表示当前 call site 所包含的 catch 块都不能处理 exception。
type table
编译器会将 catch 块异常类型的 typeinfo 信息存储在 type table 中。typeinfo是 C++标准库提供的类,它包含了与类型相关的运行时信息。
举个例子
以下面的代码为例,抛出异常并在当前函数内捕获异常:

简化后判断是否能 catch 异常的过程:
catch_exception 将函数的地址区间拆分为不同的 call site,21 行 try 块所在的 call site ,记录了这个区间能 catch 的异常类型 out_of_range 和 exception,以及 catch 后的跳转地址 22 行,在 22 行根据抛异常的类型判断具体执行的 catch 语句。try 块内抛出的异常类型 out_of_range 和 call site 记录的异常类型匹配,异常被捕获,根据匹配的类型继续执行第一个 catch 语句。如果不匹配,会继续在调用栈向上查找,如果上一个栈帧跳转到 catch_exception 的地址也在 try 块内,则继续使用对应的 call site 判断,如果仍然不能匹配或者跳转地址本身就不在 try 块内则继续查找上一个栈帧。
接下来根据 catch_exception 方法生成的实际数据推演运行时捕获 exception 的流程。
catch_exception 方法内 catch 两种类型的异常 out_of_range 和 exception, 对应的 type table 如下所示, 其中 0 表示会 catch 所有的异常:
| Catch TypeInfos | type_info |
|---|---|
| TypeInfo 3 | 0 |
| TypeInfo 2 | __ZTISt12out_of_range@GOT-Ltmp28 |
| TypeInfo 1 | __ZTISt9exception@GOT-Ltmp29 |
action table 如下所示,action table entry 中 filter 表示上述 type table 中的索引值,以 Action Record 4 为例表示使用 type table 中索引 1 对应的 std::exception 判断是否能 catch 异常,判断执行的逻辑是 std::exception 是否和抛出的异常类型是同一个类型或者有相同的基类。而 Action Record 5,next_ar 指向 action 4,表示的是一个链表,会先使用 action 5 中的索引值 2 对应的 std::out_of_range 判断,如果不能 catch 异常,会继续执行 action 4 的判断逻辑,两者任意一个类型匹配抛出异常的类型都表示异常可以被捕获。
| Action Record | Filter(索引) | Next Action |
|---|---|---|
| Action Record 1 | 0(Cleanup) | No further actions |
| Action Record 2 | 1 | Continue to action 1 |
| Action Record 3 | 2 | Continue to action 2 |
| Action Record 4 | 1 | No further actions |
| Action Record 5 | 2 | Continue to action 4 |
catch_exception 方法在编译时生成的 call site table 如下,其中的 Lfunc_beginX,LtmpX 表示汇编代码的标签,可以理解为代码段中地址的别名。
以 Call Site 3 为例,表示当 PC 处于 Ltmp3 和 Ltmp4 地址区间内,会根据上述 action table 中的 action 5 判断是否能 catch 异常,是则会跳转到 call site 记录的 landing pad 地址 Ltmp5 处,执行 catch 语句处理异常。
Call Site 1 2 和 4 记录的 action 都是 0, 0 表示需要执行 cleanup,cleanup 只会在 phase2 阶段触发,在 phase1 命中 cleanup,表示当前栈帧无法 catch 异常,会继续执行 unwind。1 和 4 的 lpad 也是 0 表示不存在执行 cleanup 的函数入口,2 不为 0,实际上也只有 Call Site 2 会在阶段 2 跳转到 Ltmp2 地址处执行 cleanup。
| Call Site | start(代码标签) | len | lpad | action(索引) |
|---|---|---|---|---|
| Call Site 1 | Lfunc_begin0 | Ltmp0-Lfunc_begin0 | no landing pad | 0(cleanup) |
| Call Site 2 | Ltmp0 | Ltmp1-Ltmp0 | jumps to Ltmp2 | 0 |
| Call Site 3 | Ltmp3 | Ltmp4-Ltmp3 | jumps to Ltmp5 | 5 |
| Call Site 4 | Ltmp4 | Ltmp11-Ltmp4 | no landing pad | 0 |
抛出异常代码 throw std::out_of_range("out of range") 对应代码标签 Ltmp3:
1 | Ltmp3: |
Ltmp3 在 Call Site 3 范围内 。
| Call Site 3 | Ltmp3 | Ltmp4-Ltmp3 | Ltmp5 | 5 |
|---|
Call Site 3 的 action 字段值为 5, 对应 Action Record 5:
| Action Record 5 | 2 | Continue to action 4 |
|---|
Action Record 5 使用 out_of_range 判断是否能 catch 异常。抛出异常类型为 out_of_range,action 5 可以 catch 异常,search 阶段执行完成。
Call Site 3 对应的 landing pad address 为 Ltmp5,在 phase2 跳转到 Ltmp5 根据 type_info 判断具体执行的 catch 语句,Ltmp5 标签处的代码:
1 | Ltmp5: |
LBB0_8 最终会执行第一个 catch 语句:
1 | .loc 1 25 9 ; CPPException/test.cpp:25:9 |
LBB0_5 最终会执行第二个 catch 语句:
1 | .loc 1 23 9 ; CPPException/test.cpp:23:9 |
源码分析
对 LSDA 的内存布局和异常处理流程有一定了解之后,再去阅读异常处理流程的源码,相对就比较容易了。接下来回到问题本身,从源码的角度分析一下在快手
App 内为什么 exception 无法 catch out_of_range。
异常处理流程会先获取 catch 语句中 exception 的 type_info:
1 | const __shim_type_info* catchType = |
catchType == 0 表示 catch (...) 会捕获所有异常。不为 0 时调用 can_catch 方法判断 catch 块中声明的类型和抛出异常的类型是否匹配。
1 | if (catchType->can_catch(excpType, adjustedPtr)) { |
can_catch 有两个判断,其中任意一个成立都表示可以 catch 异常。
- 调用 is_equal 判断 catch 块类型是否和抛异常类型相等。
- 调用 has_unambiguous_public_base 判断两者是否有相同的 base,判断 base 是否相同时也会调用 is_equal 方法。(
unambiguous: 明确的)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22bool
__class_type_info::can_catch(const __shim_type_info* thrown_type,
void*& adjustedPtr) const
{
// bullet 1
if (is_equal(this, thrown_type, false))
return true;
const __class_type_info* thrown_class_type =
dynamic_cast<const __class_type_info*>(thrown_type);
if (thrown_class_type == 0)
return false;
// bullet 2
__dynamic_cast_info info = {thrown_class_type, 0, this, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,};
info.number_of_dst_type = 1;
thrown_class_type->has_unambiguous_public_base(&info, adjustedPtr, public_path);
if (info.path_dst_ptr_to_static_ptr == public_path)
{
adjustedPtr = const_cast<void*>(info.dst_ptr_leading_to_static_ptr);
return true;
}
return false;
}is_equal的判断逻辑如下,use_strcmp传入的是 false,执行第 8 行:1
2
3
4
5
6
7
8
9
10
11static inline
bool
is_equal(const std::type_info* x, const std::type_info* y, bool use_strcmp)
{
// Use std::type_info's default comparison unless we've explicitly asked
// for strcmp.
if (!use_strcmp) //
return *x == *y;
// Still allow pointer equality to short circut.
return x == y || strcmp(x->name(), y->name()) == 0;
}std::type_info重载了==方法:
1 | bool operator==(const type_info& __arg) const _NOEXCEPT |
默认 __impl 中 __eq 实现如下:
1 | static bool __eq(__type_name_t __lhs, __type_name_t __rhs) _NOEXCEPT { |
结合源码信息, 再次回顾下我们这次遇到的问题,直接原因是 out_of_range 遍历到 base std::exception 时和 catch 语句声明的 std::exception 在执行 is_equal 时返回了 false,便于区分我们把前者称之为 thrown_exception, 后者称之为 catch_exception。
第一个判断条件 ==:
== 判断的是 type_info 中 __type_name 的地址,__type_name 的类型是 const char *。 thrown_exception 的 __type_name 存储在 libc++abi.dylib 的 __TEXT.__const 段。catch_exception 的 __type_name 存储在主可执行文件的 __TEXT.__const 段。所以地址判等为 false。
第二个判断 is_unique:
thrown_exception 的 type_info 是 unique 类型的,unique 表示 type_info 在程序中只存在一份副本,因此对于地址不同的 type_info 一定是不相等的,不需要判断 name 是否相等, 所以在第二个 if 语句返回了 false。
第三个判断 strcmp:
虽然两个 type_info 的 name 都是 St9exception,但在第二个判断返回 false,并没有走到 strcmp 的逻辑里面。
对于 type_info 的判等,实际上存在三种方式:
1. __unique_impl::__eq
1 | static bool __eq(__type_name_t __lhs, __type_name_t __rhs) _NOEXCEPT { |
在遵循 Itanium ABI 的编译器中,对于给定类型的 RTTI,只有一个唯一的副本存在,因此可以通过比较类型名称的地址来判断 ,无需使用字符串,可以提高性能并简化代码。
2. __non_unique_impl::__eq
1 | static bool __eq(__type_name_t __lhs, __type_name_t __rhs) _NOEXCEPT { |
由于各种原因,链接器可能没有合并所有类型的 RTTI(例如:-Bsymbolic 或 llvm.org/PR37398)。在这种情况下,如果两个 type_info 的地址相等或者它们的名称字符串相等,这两个 type_info 被认为是相等的。
修复方案中的方案 5 通过设置 cflag 把 __impl 类型修改为 __no_unique_impl,使用 strcmp 方法判断主可执行文件中的 type_info 和 libc++abi 中的相等。
3.__non_unique_arm_rtti_bit_impl::__eq 默认实现
这种方式是 Apple ARM64 的特定实现,给定类型的 RTTI 可能存在多个副本。在构造 type_info 时,编译器将类型名称的指针存储在 uintptr_t 类型中,指针的最高位表示 non_unique 默认为 0(false)。如果最高位被设置为 1,表示 type_info 在程序中不是唯一的。如果最高位没有被设置,表示 type_info 是唯一的。
这个设计的目的是为了避免使用 weak 符号。它将原本会被作为弱符号生成的默认可见性的 type_info,转而使用隐藏可见性的 type_info,并把 non_unique bit 位设置为 1,表示非唯一。这样做的好处是,在链接镜像内,hidden 可见性的 type_info 仍然可以认为是唯一的,可以继续通过 linker 进行去重,而在不同的镜像间,会被视为不同的类型,避免了 weak 符号被重定向,导致 RTTI 类型信息混乱。
EH & -fno-rtti
这次问题的直接原因是主可执行文件多了一份 type_info, 那为什么禁用 RTTI 之后会重新生成一份 type_info 呢?
异常处理流程依赖 type_info 实现 can catch 的判断逻辑,在禁用 RTTI 之后,为了能继续获取异常类型的 type_info 信息,编译器会重新生成一份。
llvm ItaniumCXXABI.cpp 文件 BuildTypeInfo 方法内可以查看生成 type_info 的逻辑。
其中判断是否使用外部的 type_info 代码如下:
1 | // Check if there is already an external RTTI descriptor for this type. |
条件1: IsStandardLibraryRTTIDescriptor
判断是否是基础类型,比如 int bool float double。
条件2: ShouldUseExternalRTTIDescriptor
判断 type_info 是否已经存在于其他位置,如果是在当前的编译单元中就不需要再生成 type_info。
在 ShouldUseExternalRTTIDescriptor 方法内判断了 RTTI 的状态,禁用后直接返回了 false。
1 | // If RTTI is disabled, assume it might be disabled in the |
禁用 RTTI 后上述两个条件都不满足,会继续执行生成异常类型的 type_info,同时也会生成 base 的 type_info。
1 |
|
总结
开局 3 分钟,战至二塔下猥琐发育的鲁班自言自语到: 有人需要技术支持吗? 鲁班大师,智商二百五,膜拜,极度膜拜。
查看 mmkv 的 issue 列表,发现我们并不孤单。iOS 工程通常使用 cocoapods 集成不同的组件,这些组件在编译时会作为一个独立的 target,任意一个 target 的编译选项禁用 RTTI 后都会影响到宿主 App 的异常处理流程,继而可能引发 try catch 失效。
为了解决此类问题,给大家提供两个规避方案:
- 禁用
RTTI的同时禁用exception handling,即-fno-rtti和-fno-exceptions一起使用,这样单独的 target 不会影响到宿主 App 的exception handing。 - 如果禁用
RTTI后想保留exception handing,添加cflag -D_LIBCPP_TYPEINFO_COMPARISON_IMPLEMENTATION=2,在损耗一点性能的前提下保证exception handling正常的处理流程。
参考资料
[1] https://llvm.org/docs/ExceptionHandling.html
[2] https://itanium-cxx-abi.github.io/cxx-abi/abi-eh.html
[3] https://itanium-cxx-abi.github.io/cxx-abi/exceptions.pdf
[4] http://www.hexblog.com/wp-content/uploads/2012/06/Recon-2012-Skochinsky-Compiler-Internals.pdf