[转载] QQ 客户端性能稳定性防劣化系统 Hodor 技术方案
防劣化是比较经典的技术话题,手 Q 的防劣化系统从 2021 年 10 月开始投入研发,从 0 到 1 迭代了将近三年的时间,已经达到了业界先进水平。为了守护好手 Q 性能稳定性的门禁,我们将其命名为 Hodor 系统,即 Hold the door!
从验证可行性跑通最小闭环,到搭建群控机架一次次为集群扩容,实属不易。其中涉及到大量的方案讨论甚至推翻,很多思路和实现细节是业界找不到公开方案的,只能自己摸索。本文详细分享了手 Q 防劣化系统的构建链路,相信对业界和开发者们都有较高的借鉴意义。
为什么要做防劣化
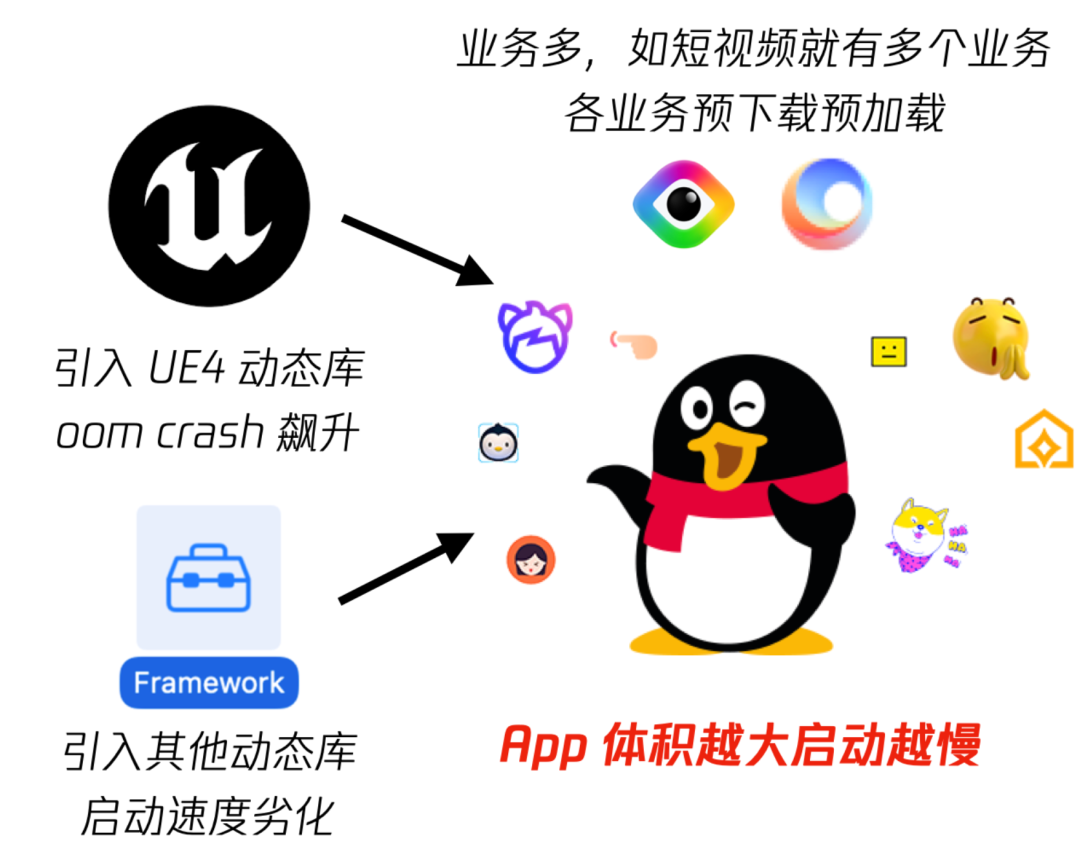
- 代码体量较大:业务涵盖 IM/空间/短视频/超级 QQ 秀等。
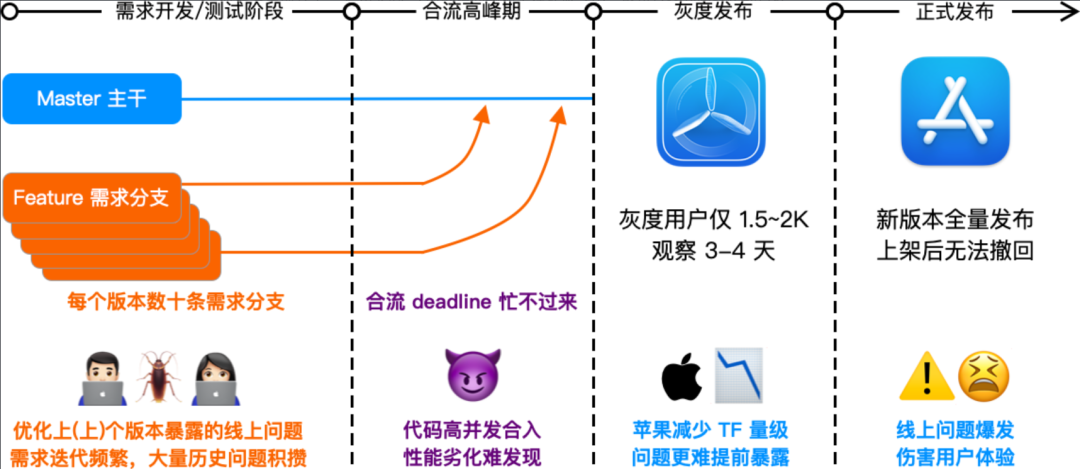
- 迭代需求紧:双周迭代,研发人员多;每版本几十条需求分支,主干每周构建出包数百次。
- 问题较多:需求合流新增性能问题多,基础侧人力寡不敌众,问题越堆越多,事后回溯效率低。
当业务的体量足够大,问题足够复杂的时候,解决问题的思路也需要转变。
1.1 如何破局
盘点了下手 Q 研发流程的困局,现有的手段更着重于线上监控问题并在下个版本修复(甚至是下下个版本),如果能在开发阶段发布前甚至合入 master 之前就把问题扼杀在摇篮之中,就可以达到防劣化的目标。
下图根据手 Q 真实惨痛案例改编,当年为了查一个严重的启动耗时劣化问题,二分法拉代码手动跑 Instruments 的痛,懂的都懂。

此聊天记录为虚构,如有雷同纯属巧合
大家开发需求都爱赶 deadline,所以合流高峰期光靠堆人力代码 CR 和手动测试性能是不现实的,性能问题漏出事后优化也是不够的。因为业务的复杂性,总是优化赶不上劣化快。手 Q 在优化性能稳定性的同时,也提前布局防劣化系统,将其作为质量三位一体中的重要一环:
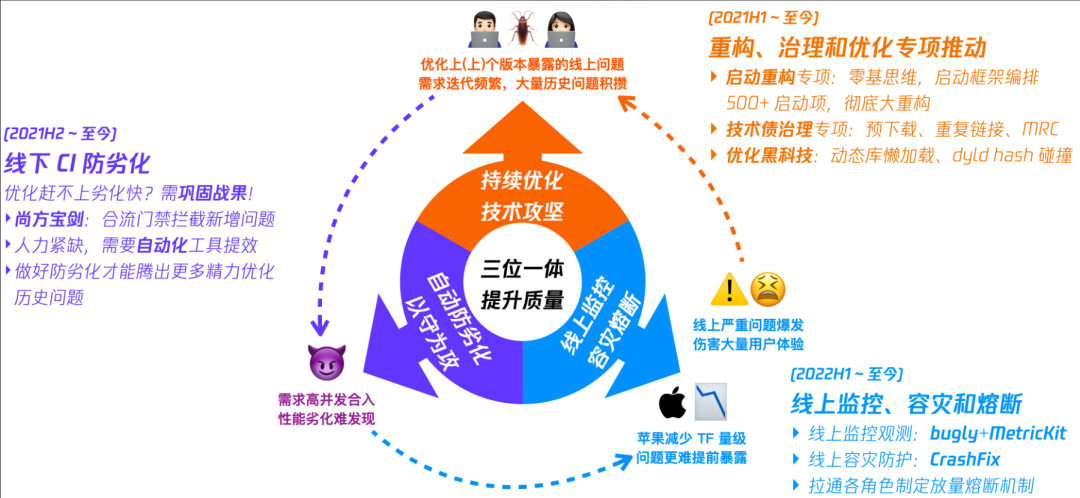
1.2 我们的口号:Hold the door!
提前发现部分主路径问题,通过门禁防止性能劣化:
- 主干合流门禁:对于较稳定的性能指标,合流前自动检查。
- 日常自动提单:针对偶现的性能问题,开发阶段提前发现。
- 性能数据看板:常态化详细数据看板,上帝视角观测性能。
- 告警机器人:自定义各性能维度告警规则,第一时间发现问题。
防劣化系统的实现
因为整套系统的实现比较复杂,考虑到整体篇幅限制,数据采集部分仅概述 iOS 平台的方案,各平台数据的上报协议及服务端的处理逻辑是共享的。
2.1 方案设计
要做好门禁,就需要把性能数据精确到每一次
commit,并做好科学的对比。现实情况是很复杂的,可能有各种各样的突发情况:
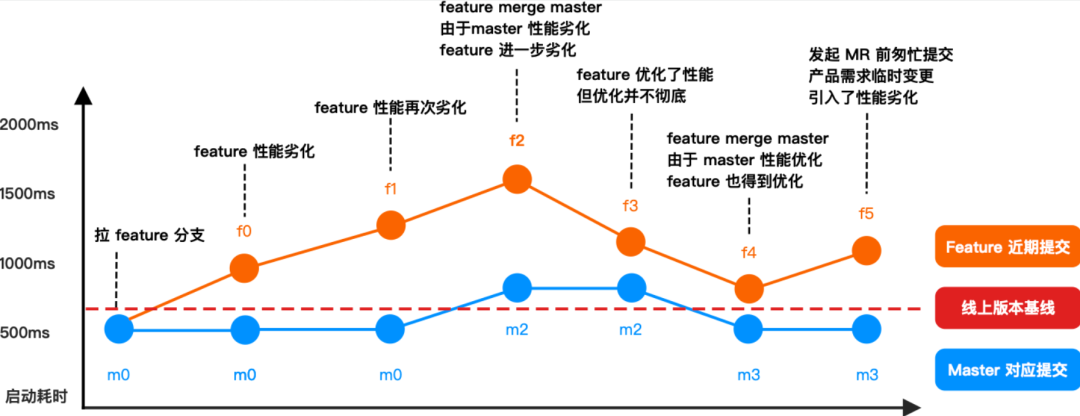
基于以上诉求,我们开发了 feature 分支对比 master 的算法策略。建立全维度性能指标和科学归因方案。Hodor 实现了性能报告、数据分析、智能调度、提单告警、设备管理、用例管理等一系列能力,大概的运行机制如下:
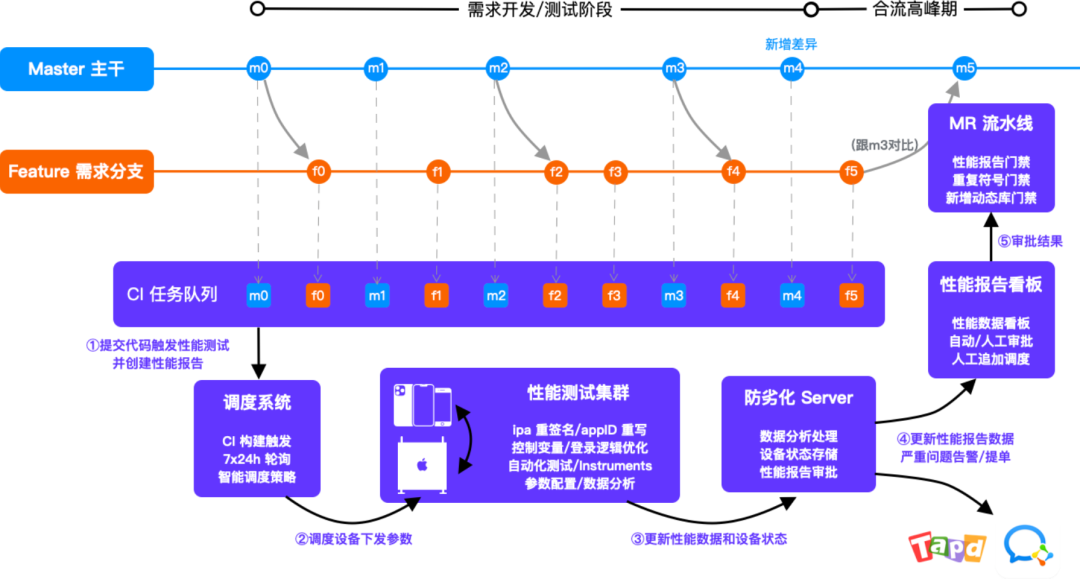
此方案的优点:
- 性能测试和性能报告创建审批左移到开发阶段。
- 覆盖场景可拓展:测试用例云端独立管理派发。
- 性能维度可拓展:支持 Instruments 所有模板。
- 静态检查可拓展:构建数据服务端存储与比对。

2.1.1 防劣化 ≠ 自动化测试
现有测试平台和工具的不足:测试平台站在发现问题角度,缺乏解决问题思维;APM SDK 运行时采集能力受限
- 传统的自动化性能测试平台和工具的报告只有 metric 统计数据和 App 截图/日志,信息太少不足以定位问题。
- APM 平台的线上监控很强大,但无法动态追踪采集 time profiler 等详细数据。
所以解决问题依然需要开发同学获取更详细信息或能够 debug 复现问题,而性能问题往往是偶现的。

自动防劣化解决方案:打通发现和解决问题全链路:
- 通过 Instruments 动态追踪技术采集 diagnostic 诊断数据,无侵入性。
- xctrace 自动解析 trace 文件,翻译堆栈精准归因,还原『案发现场』。
- 每次提交构建均执行防劣化检测,精准定位问题的提交引入者。
- 数据可视化看板+自动提单派发+大模型 AI 分析问题 = 测开降本增效。
总之,手 Q 的解决方案从一开始就打破了传统思维,最终的方案也是真香!

2.1.2 复杂业务下如何降低性能波动
俗话说细节决定成败,很多事情想跑通 demo 很容易,但是想达到高可用性,需要打磨很多很多细节才能应用到生产环境。比如为了控制变量降低场外因素波动,大到集群调度策略,小到机器零件型号,都锱铢必较。

2.2 数据采集
在运行时性能数据采集方面,我们拥有一套自研方案;在静态扫描方面,也从编译链接过程采集了相关数据。
2.2.1 动态性能数据采集
性能采集方案选型之初,我们对于性能采集主要有以下几个诉求:
- 需要有详细的堆栈信息;
- 性能维度足够多;
- 最好非侵入式的;
- 容易与 CI 流程相结合。
为了满足上述诉求,最终我们选则了当时苹果刚推出的 xctrace 方案。
应用外数据采集:
xctrace
Instruments 是 iOS & macOS 平台进行性能分析必不可少的工具,它能采集到绝大多数的性能数据,同时拥有精美的 GUI 方便排查和分析。但是 Instruments一直都只有 GUI(古早年代曾经有过导出性能数据的功能,后面也去掉了),没有 CLI,这也使自动化使用 Instruments 进行性能采集和分析成为奢望。直到 Xcode 12,苹果终于推出了 Instruments 的 CLI 版本:xctrace。

xctrace 提供了一系列命令,可以录制、导出性能数据,Instruments 支持哪些性能维度,xctrace
就支持哪些性能维度。我们根据不同的性能采集需求,生成不同的性能模板,使用 xctrace 录制对应的性能数据。录制好的 trace 文件可以通过 xctrace 导出为 XML 格式的文件,从 XML 文件中读取到性能数据。
值得一提的是,手 Q 作为早期第一批吃螃蟹使用 xctrace 的技术团队,我们一边摸着石头过河探索 workaround,一边与苹果团队合作以提升其可用性。Xcode 14 Release Notes 中解决的多个 issue 也是手 Q 团队在防劣化开发过程中向 Apple 提出的:

所以手 Q 团队已经默默帮大家踩过很多坑了!
Xcode Memory Graph
在排查内存泄露相关问题时,使用 Instruments 内存相关模板只能看到对象的创建堆栈和引用计数的增减过程,无法展示对象间的引用关系。面对这类问题,Xcode Memory Graph 是更好的选择,但 Xcode Memory Graph 也是一个嵌入到 Xcode 的 GUI 程序,目前为止还没有 CLI 实现。为此,我们调研了 Xcode Memory Graph 的实现,获取到相关协议,实现脱离 GUI 生成 Xcode 内存图,并使用 heap、vmmap、leaks 等工具分析内存图,实现自动采集内存图,进行大内存占用和内存泄露的分析和监控。
Crash
Crash 的监控比较简单,我们是通过检查测试过程中设备上有没有新生成的 ips 文件方式来监测 Crash 的。这种方式的优点是监控范围广,SIGKILL、pre-main 阶段 Crash 等常规方式无法捕获的 Crash 也能监控到。实践中遇到的一个小坑是单台设备每天单个 App 生成 ips 文件是有上限的,之前测试阈值是 50,崩溃超过 50 次就不再生成 ips 文件。
高频日志
分析客户端日志是必不可少的排查问题的手段,但大型项目业务繁多,会出现很多无效高频日志,高频日志会占用大量的 IO 和 CPU 资源造成卡顿和发热,甚至有导致日志文件过大,无法打捞起来的情况。而且很多时候,高频日志的背后就是一段死循环或者循环调用逻辑的存在,所以我们对高频日志也进行了监控和告警提单。
应用内数据采集:
流量监控
流量下载的数据采集,虽然 Instruments Network 模块能够监控所有的下载请求,但 Network 上显示的流量大小依赖了 Response Header的 Content-Length 或 Range 字段。由于部分后台服务器并没有填写该字段,所以 Instruments 上无法获取总的下载流量大小,故而放弃 Instruments 上采集数据,改用 App 运行时收集数据。
业务打点
性能数据需要和业务场景进行关联,我们采用了苹果的 Signpost 方案进行打点,选择 Signpost 打点方案的原因主要是下面 3 点:
- 和 Instruments 高度契合,Instruments 有 os_signpost 模板,应用内使用 signpost 相关接口打的点,在 Instruments GUI 展示性能数据时,也能将业务打点一并展示,方便排查问题;
- signpost 打点数据可以使用 xctrace 进行导出,可以实现业务场景和性能数据的相关联;
- 相比 print 打点方式,signpost 性能损耗更低。
2.2.2 静态扫描能力
符号扫描
平台有两套符号扫描工具,都是面向链接期产物 (Mach-O Image)
进行静态扫描,分别洞察产物中的 Objective-C (简称 OC)
符号问题和原生符号问题。
OC 符号扫描:
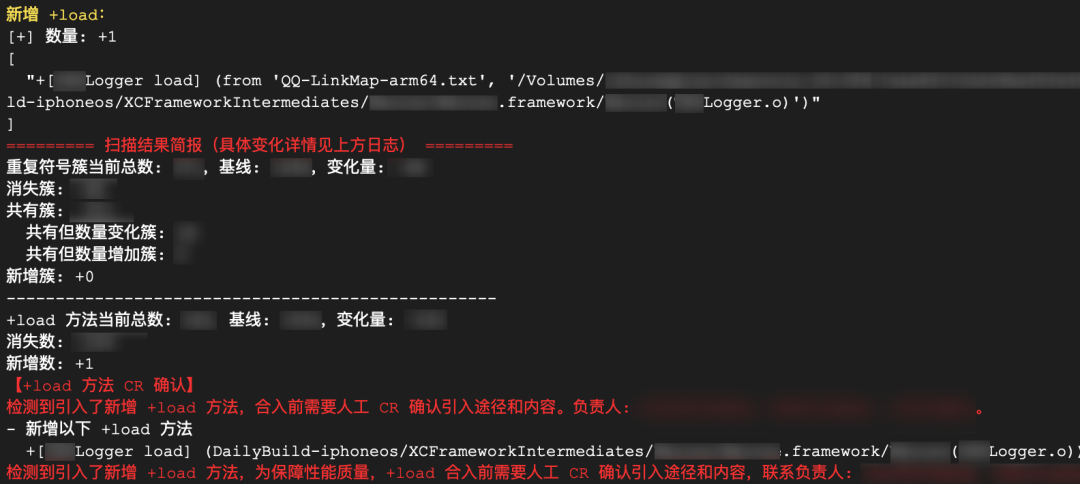
OC 符号扫描工具,帮助扫描工程产物中存在的 OC Category 同名方法覆盖和 +load 静态初始化方法。
- OC Category 同名方法覆盖是指 Category 机制隐含的运行时实现覆盖问题,覆盖问题有两种情形:1. 若主类 (原类) 存在一个与 Category 扩展方法同名的方法,则运行时会选择 Category 的实现使用。2. 若存在多个 Category 都对同一个类扩展了同名的方法,则运行时会选择其中一个 Category 的实现使用。这两种情况都可能导致程序逻辑非预期地调用到其他库的实现,出现功能异常或崩溃。该问题相对隐蔽不易被察觉,因为在链接期间不会产生警告。尽管代码规范要求 Category 方法名必须加前缀来规避该问题,但该问题在大型多源项目的集成过程中,还是时有发生,只是往往因为恰好兼容没出问题而没感知。直到某天改动后出现莫名异常,溯源后才发现。
- +load 方法在程序加载的静态初始化阶段执行,会影响应用的启动耗时。
这两类方法(符号)对稳定性和性能有全局性的影响,因此平台建设了工具来关注这些符号。
工具综合基于 class-dump 和链接器生成的 LinkMap 信息 (如果有),获取产物中的全部 OC 符号和来源,统计筛选出重名 Category 方法和 +load 方法。并与 CI 构建检查相结合,监控和管控这两类问题方法,设立门禁要求业务新引入 +load 和重名方法须拉通基础侧 Review。

原生符号扫描:
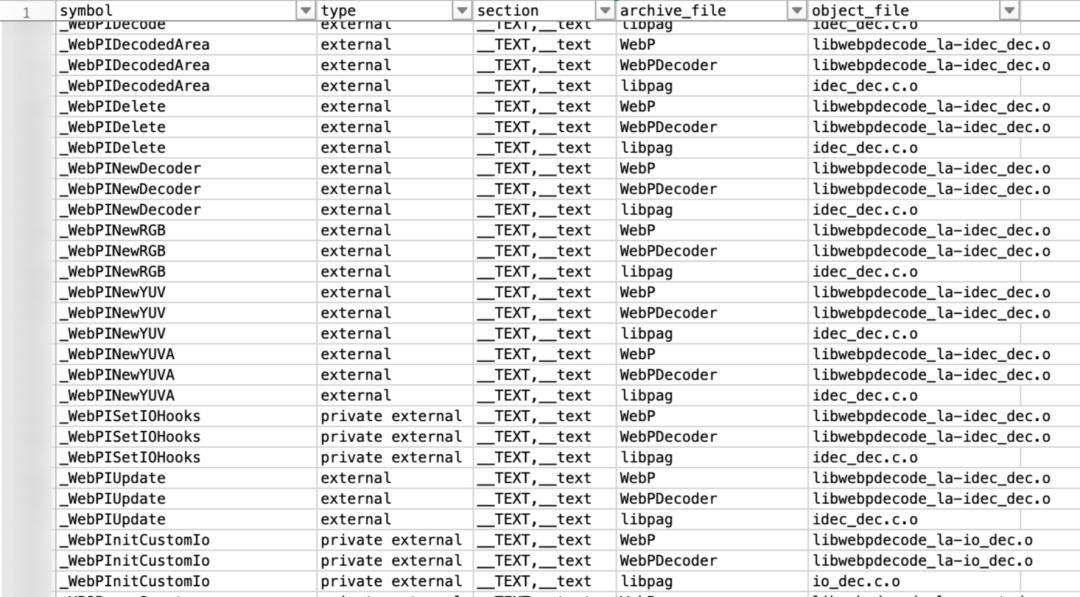
原生符号扫描工具,帮助扫描工程所有依赖库中存在重复的库函数(符号) (主要关注 C 符号重复问题)。
通常重复的库函数是 C/C++ 编写的基础实用函数,这大部分归咎于 C/C++ 缺少广泛认可的依赖管理范式,部分大型业务静态库采取将其依赖的实用方法库也一同编译打包 (ar) 的范式而导致。这些实用方法库通常是广泛使用的基础实用库,如 FishHook、zip、libffi 等。若有多个业务静态库都集成了同源的基础实用库,在链接 (ld) 生成可执行程序时,链接器会选择其中一份链接 (取决于链接先后顺序等因素,可以通过 LinkMap 确认选用的实现),它们虽然具有相同的符号 (API),但版本/实现未必一致、ABI 未必兼容,所以如果链接时选取的实现不恰当,则可能出现功能异常或崩溃。
通过原生符号扫描工具,扫描出重复的库函数,有助于标识出上述这样”存在多份重复选其一不兼容”的潜在风险。
工具的工作流程是解析链接 (ld) 参数,遍历每一个参与链接的静态库,使用 nm 工具等工具读取它们包含的对外导出 (External & Defined) 符号。实践中集成到 CI,在构建完成后的现场回溯构建日志取得链接 (ld) 参数并执行,统计出重复的原生符号并根据规则登记归档。
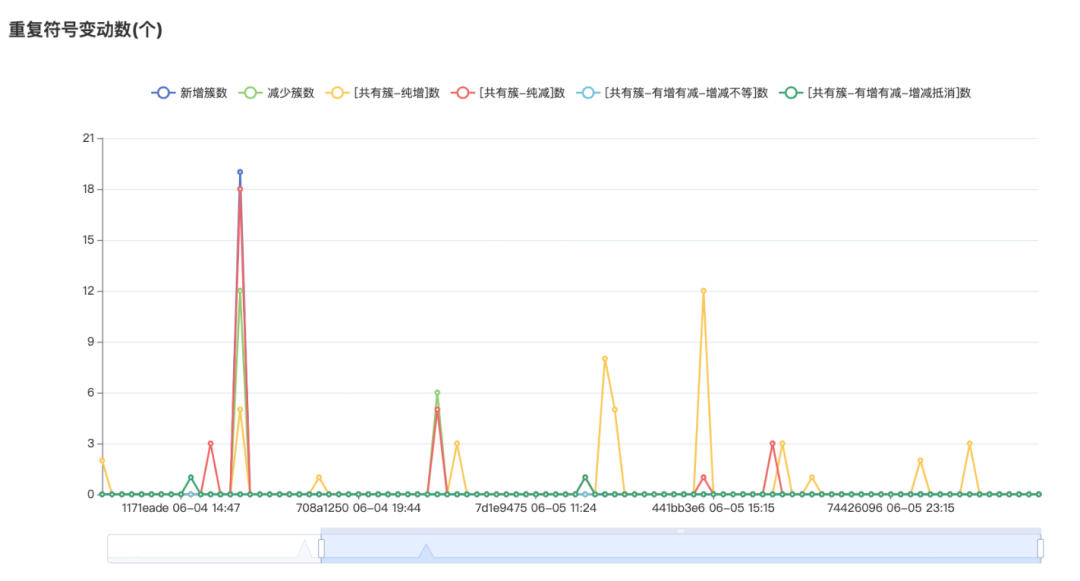
最终的统计结果会展示在 Hodor 平台,可以查看每个 commit 的重复符号变化情况:
dyld hash 碰撞扫描
在 Hodor 防劣化系统上线了一段时候后,我们抓到了一个冷启动劣化的 case:主干上一个新提交导致冷启动 T0 阶段(pre-main)劣化了 150+ ms,但该提交只修改了一个方法名。在排除掉外部因素、测试环境稳定性因素之后,发现真的因为一个方法名导致冷启动劣化那么多。问题看起来很棘手,幸好,我们有详细的 trace 文件,在详细分析对比了劣化前后的堆栈之后,发现劣化的根源是冷启动创建启动闭包时调用了一个 perfect hash 的算法,新修改的方法名导致这个算法的碰撞次数增加了,发生碰撞的情况下,需要 rehash,于是耗时增加。以下是生成启动闭包的简要流程:
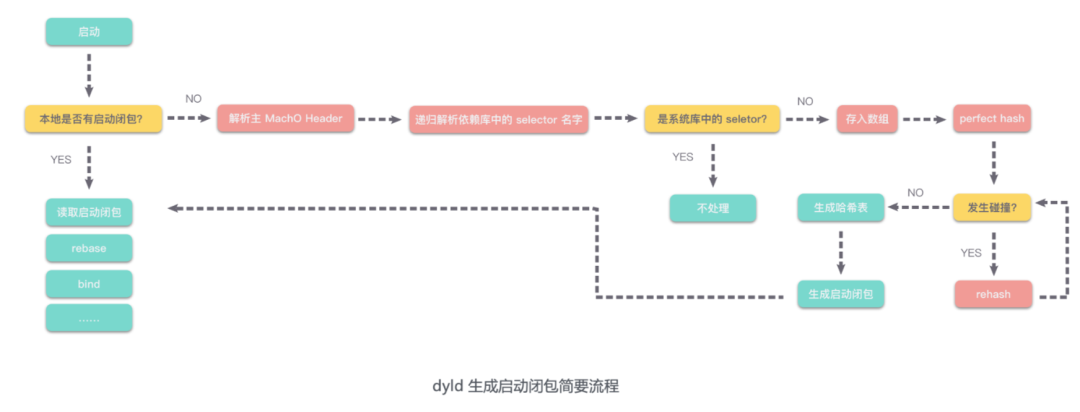
找到了劣化的原因,那如何找到发生碰撞的方法名呢?答案只能去 dyld 源码里找,还好,dyld 是开源的,我们在 dyld 源码里找到了生成启动闭包相关的部分,在发生碰撞的地方输出对应的 sel 名字,将其编译起来后,把 QQ 的 Mach-O 扫一遍,这样我们就找到了所有的碰撞点,之后我们修复了所有的碰撞点,冷启动得以降低了 700 ms(iPhone 11)。
我们将该扫描工具部署回了 Hodor 系统,监测每一个提交的碰撞情况,同时我们也将这个问题反馈给了苹果负责 linker 的团队。
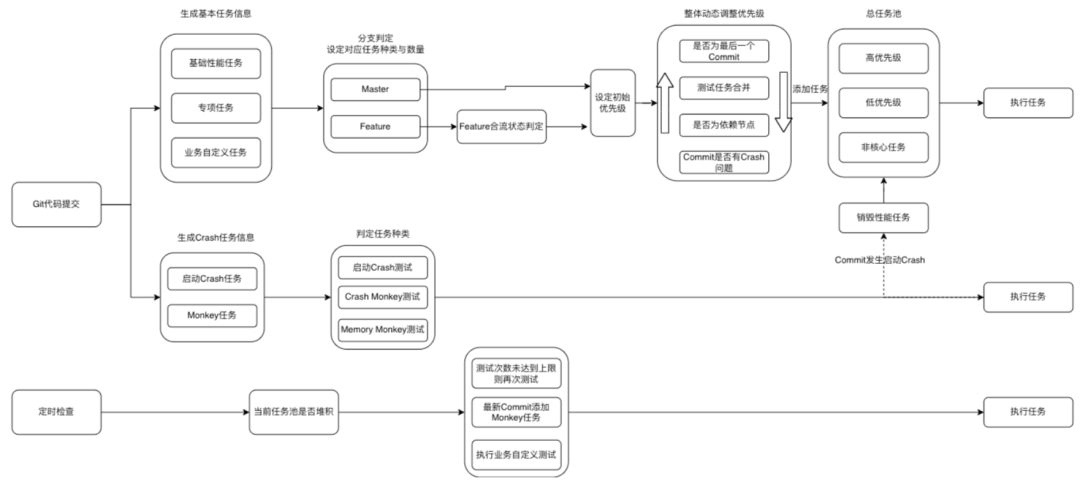
2.3 任务调度
职责在于监听 Git 事件与自定义事件并生成多类型的性能测试任务,在合适的时间点将任务与合适的测试机进行匹配然后生成配置文件,最后将配置文件派发到数据采集端驱动性能测试任务在对应测试机上执行。
2.3.1 任务类型
防劣化性能测试任务主要分为以下几大类
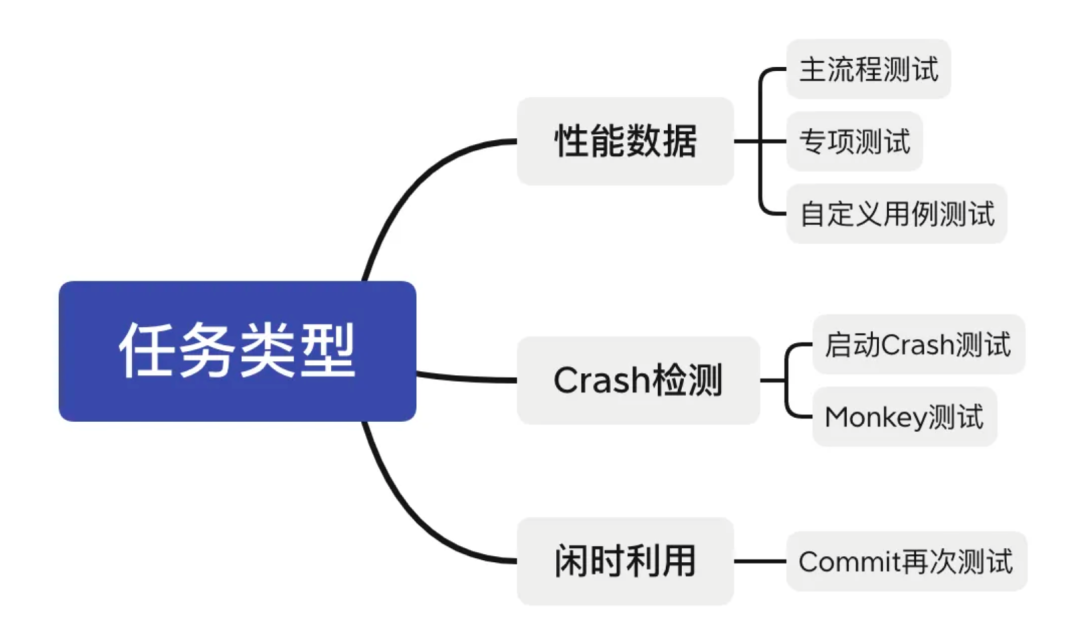
主流程测试:
由基础侧提供的核心测试用例组,测试流程包括手Q的几个核心场景进行测试(启动、登录、AIO、频道、短视频等),所有分支默认运行当前测试用例组。
后续性能报告也是基于当前用例组所上报的性能数据来进行对比。保证统一的测试用例流程与环境,性能数据的对比才是可信任的。
专项测试:
针对某些性能维度(内存、IO、预下载流量检测等)单独进行测试。最终生成相应性能看板。
自定义用例测试:
手 Q 功能场景十分的庞大复杂,基础用例也无法覆盖到所有的场景,由此诞生自定义测试用例功能。
如果业务同学想观察自己所处业务部分详细的性能数据,防劣化系统支持由各业务来编写自定义的测试用例,测试完毕后根据上报数据与定义的场景将自动生成相应性能看板。
Crash、Monkey 测试:
在日常开发中,发生 Crash 问题将会严重影响整个项目开发进度。我们希望能第一时间将问题检测暴露出来并推动修改。
启动以及主流程 Crash 则是最为严重的,直接导致项目不可使用,影响大家日常开发。Master 主干的每一个 Commit 合入都会进行 Crash 测试。如果发生 Crash,会立即拉群通知排查。而对于非启动以及主流程 Crash 问题则会进行自动提单。
而 Monkey 测试则是模拟用户操作,无序进行操作。能够尽可能的将 Crash 问题暴露出来。
闲时利用:
为了更充分的利用防劣化系统,在空闲时间(深夜、周末)会对过去已经测试过的主干 Commit 再次进行测试。用尽可能多的测试来暴露出更多的问题。
2.3.2 任务调度管理
所有生成的测试任务会根据任务类型,优先级等条件进行一轮排序,最终优先保证最紧急的任务最优先执行。
简单示意图如下:
当任务状态异常时,也会有告警。

2.3.3 设备管理
针对不同类型的任务采用不同的策略进行测试机分配。
- 对于 Crash 任务,为了保证能第一时间发现问题,会分配专门的机器池进行测试。
- 对于性能任务,根据版本流程与任务优先级进行动态分配。基础性能>业务自定义>=专项测试>闲时利用。
设备环境发生问题,也将及时进行告警:

2.4 数据处理
由于 Instruments 采集到的性能数据量巨大,动辄 GB 级别,无法全量上报,所以性能数据采集时会进行符号化和性能问题的分析,比如找出卡顿堆栈、内存泄露的对象等。分析完毕后会将数据上报给服务端,由服务端进一步处理。
职责在于将上报的数据根据不同规则进行计算存储。不同维度性能根据不同规则计算,得出相应的性能结果并消费劣化性能数据(自动提单与告警)。
2.4.1 不同类型性能数据的处理
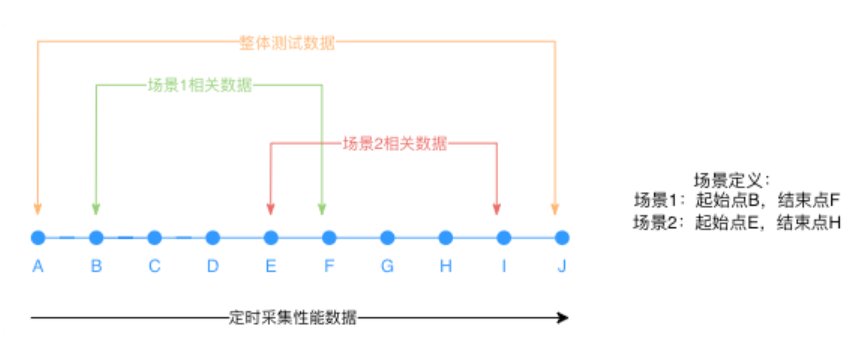
- 基础性能数据 对于基础性能数据而言(CPU、内存、IO、线程数),上报的数据是原始每一次采样所得数据(大致在一秒采样一次),这里诞生了两种计算方式。
- 对于关注整体性能数据以及流程比较短的用例,则会整体计算出三个维度的数据:峰值数据、平均数据、结束时数据。
- 对于有定义「场景」的用例,会根据所传递的打点(Signpost)值来找到对应时间范围的数据进行计算。同样是以上三个基础维度,另外新增一个耗时计算。 整体示意图如下:
- 重点性能数据 对于重点关注的数据(启动时间,启动线程状态),采集端会使用专门的模板来进行测试,上报数据后。Server 端对多次测试结果数据进行综合计算,得出结果最后展示在相应看板上。
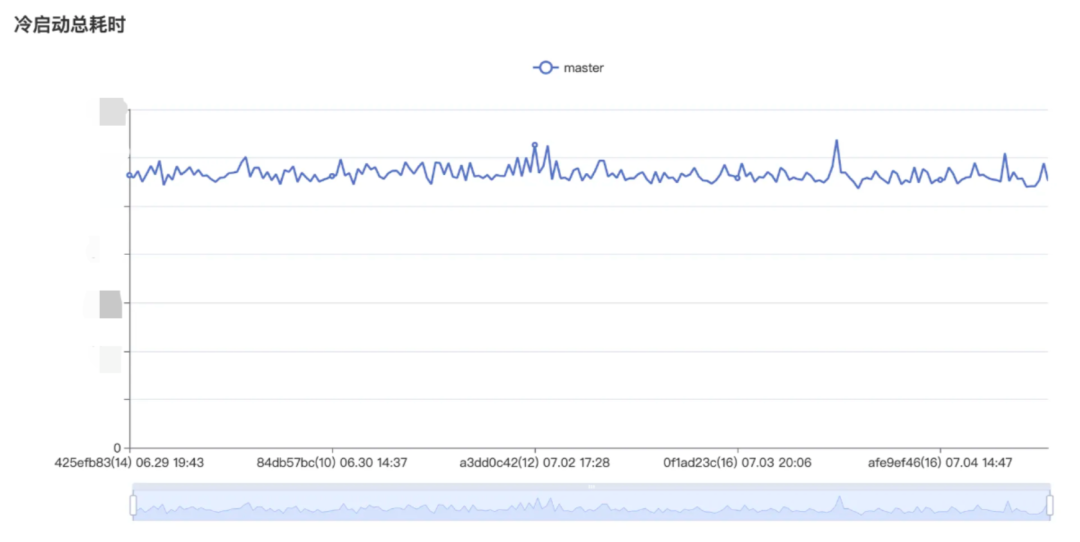
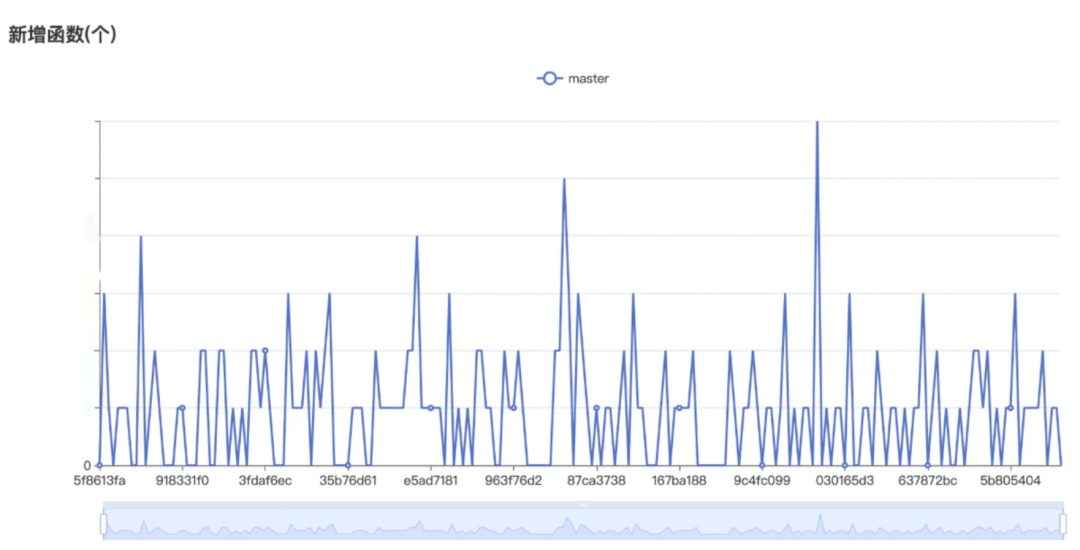
- 自定义性能数据 对于自定义上报数据(重复符号变动,启动阶段函数监控),则是开放专门上报数据接口,由对应业务方自主计算上传(防劣化会向业务方提供基本数据)。防劣化系统负责记录数据并展示相应看板。
2.4.2 消费性能劣化数据
1、 自动提单
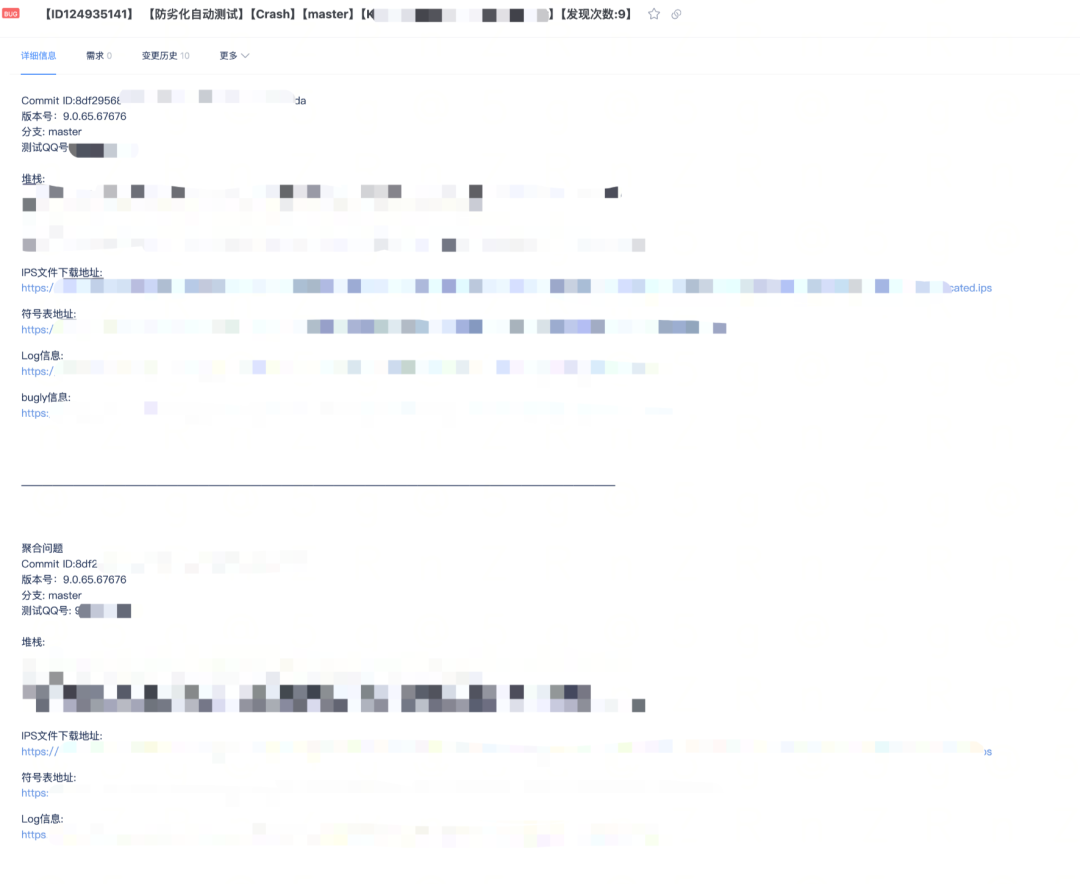
我们会定时扫描数据库中上报的性能劣化信息。先根据白名单以及过滤规则进行筛选,然后将需要提单的数据进行信息聚合,最终以提单的形式将问题自动分配给对应的业务负责人。

bug 单包含了缺陷的堆栈等详细信息:
2、 性能告警
对于主干的性能数据进行实时监控,不同用例不同性能维度可以配置不同的告警规则。当发生劣化时及时将对应的信息抛到对应业务群中进行告警。

2.5 管理端展示
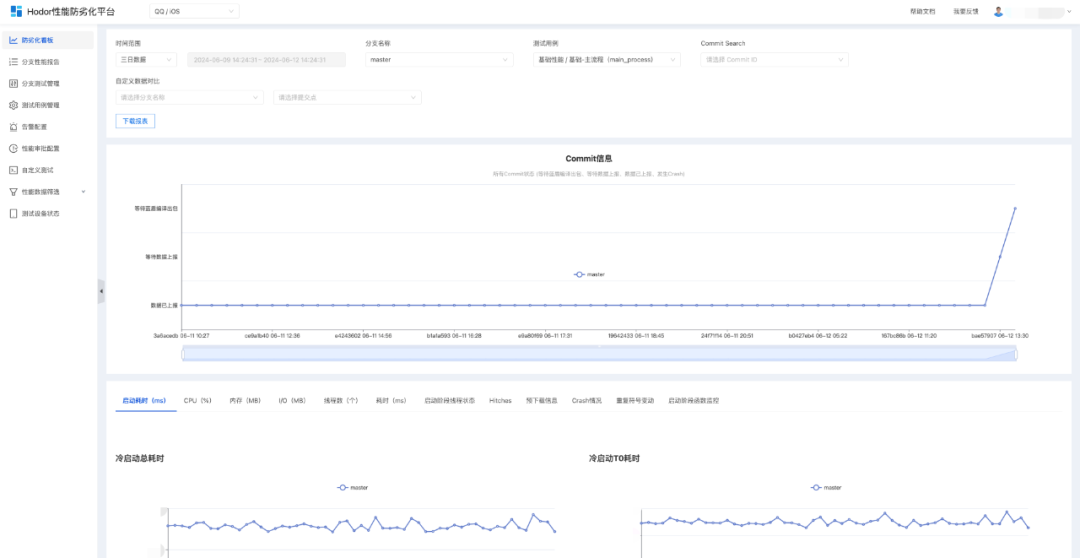
2.5.1 防劣化看板
防劣化看板支持查看指定时间、分支、测试用例和场景下的每个 commit 的状态以及各项性能数据,并可以快速标记 commit,支持与任意 commit 的性能数据做对比。
2.5.2 分支性能报告
防劣化系统会对所有需求分支的每一次 push 进行性能测试,然后与对应的主干 Commit 性能数据进行对比生成性能报告。能直观的看到需求分支的性能变化,当性能发生劣化的时候也能直观的看到是从哪个 Commit 开始引入劣化问题,方便问题排查。
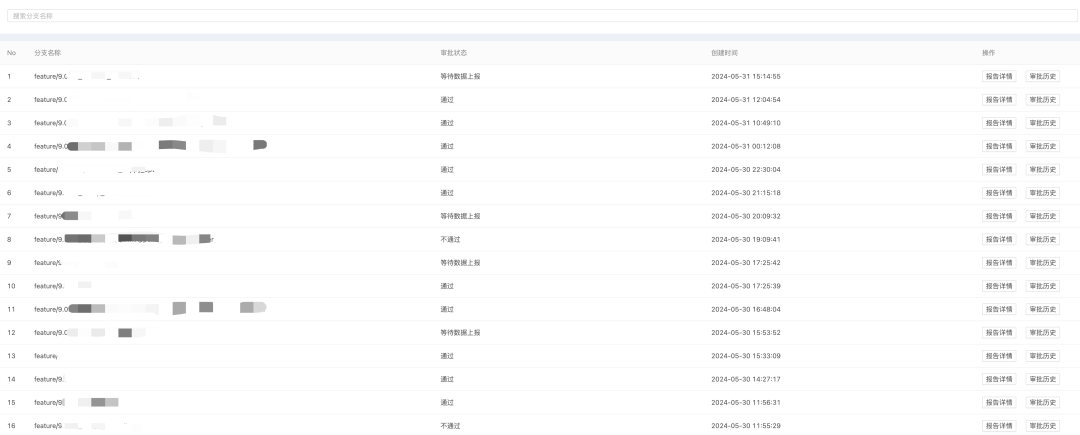
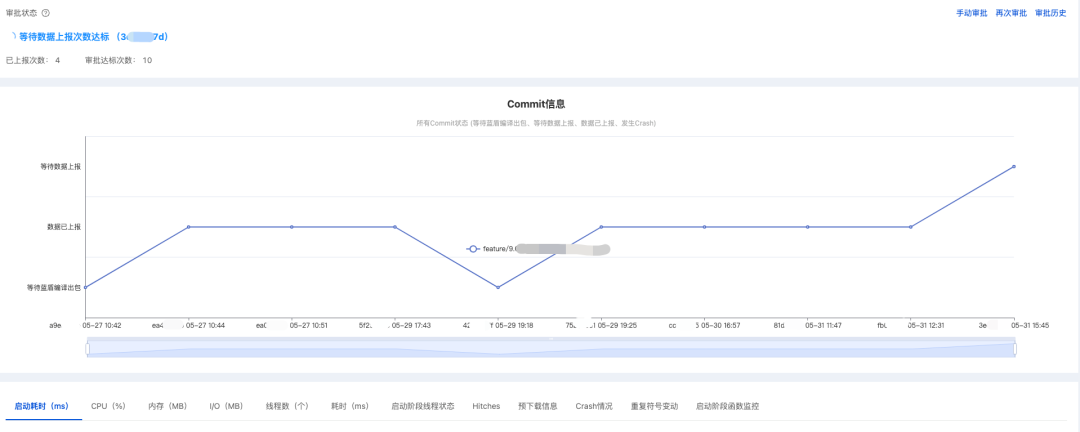
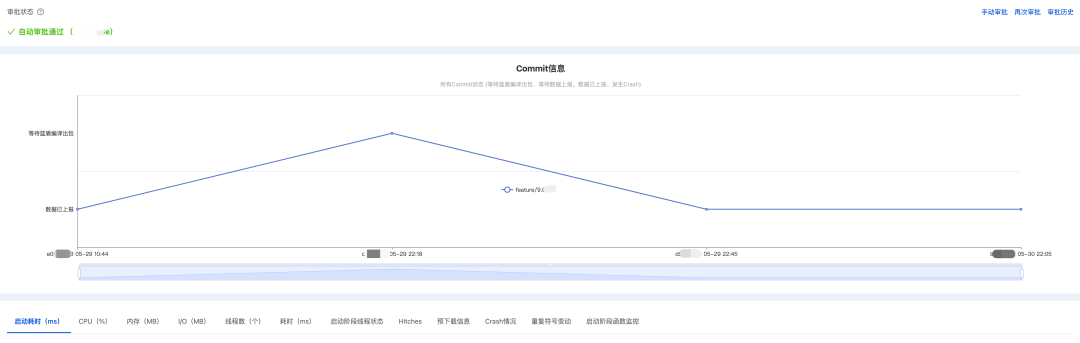
测试报告有多种状态,比如”等待数据上报”、”自动审批通过”、”自动审批不通过” 等:
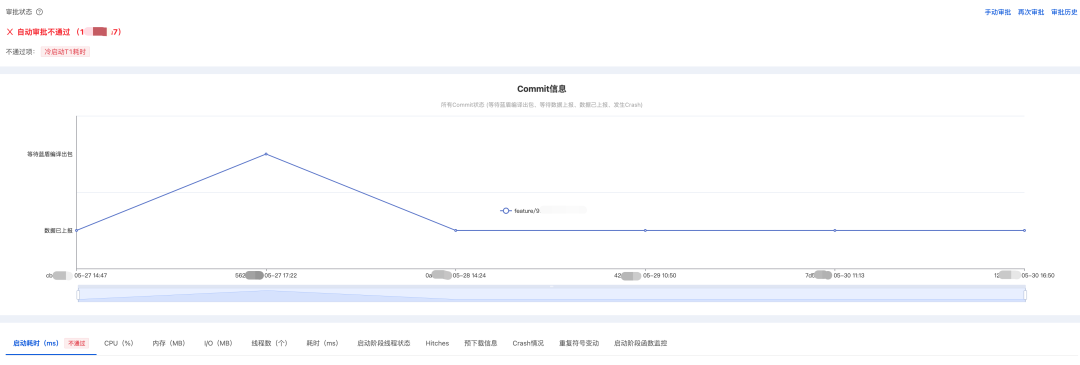
当测试报告”自动审批不通过” 时,也会标注出是哪些指标不通过,便于开发者迅速定位问题:
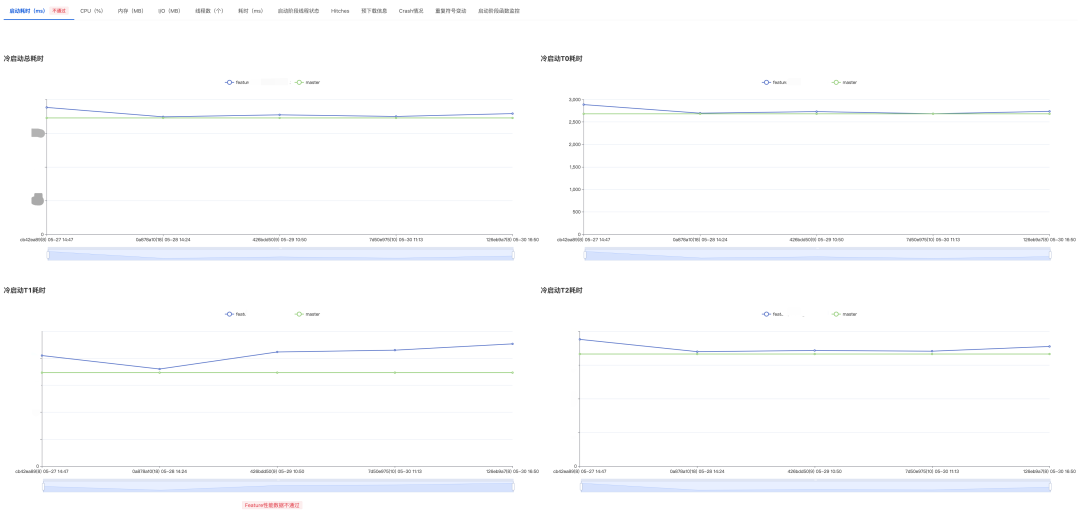
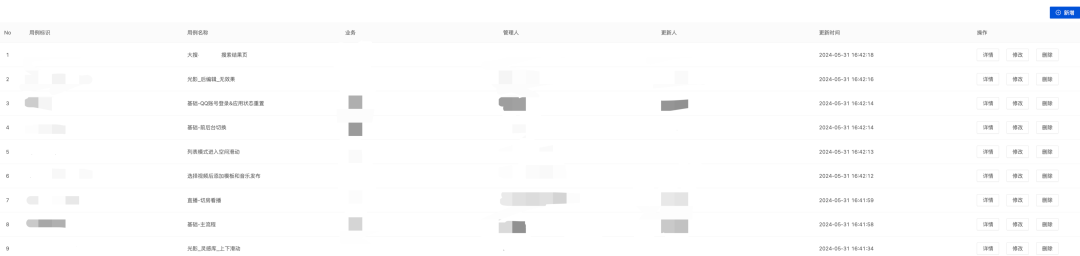
2.5.3 测试用例管理
基础所提供的主流程测试用例必然是无法覆盖手 Q 所有的场景,因此提供开放能力,支持各业务方的开发、测试自主提供测试用例。在防劣化平台上进行配置测试,测试完毕后自动根据配置生成相应的性能看板。

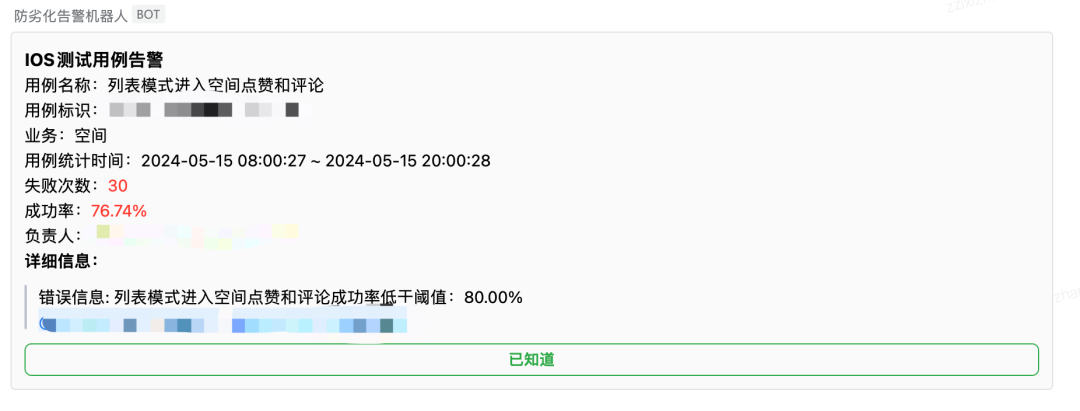
同时对正在运行的测试用例进行成功率监控,低于一定的成功率将进行告警。如业务方在一段时间内没有处理告警,会将其临时下架避免资源浪费。
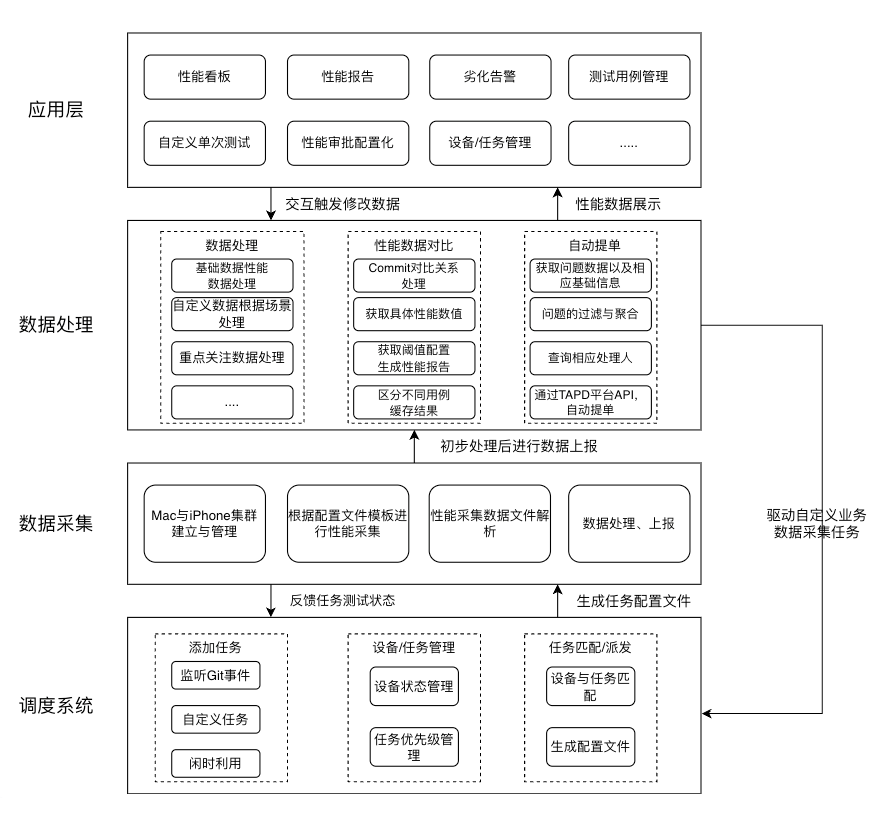
2.6 整体架构
收益与总结
Hodor 上线后收益显著,研发效率大幅提升!

通过将问题发现和解决左移到开发阶段,可以有效防止问题漏出到线上导致大盘数据劣化。如某次提交导致主干启动耗时上涨,基于防劣化系统可精准快速定位到代码提交者。
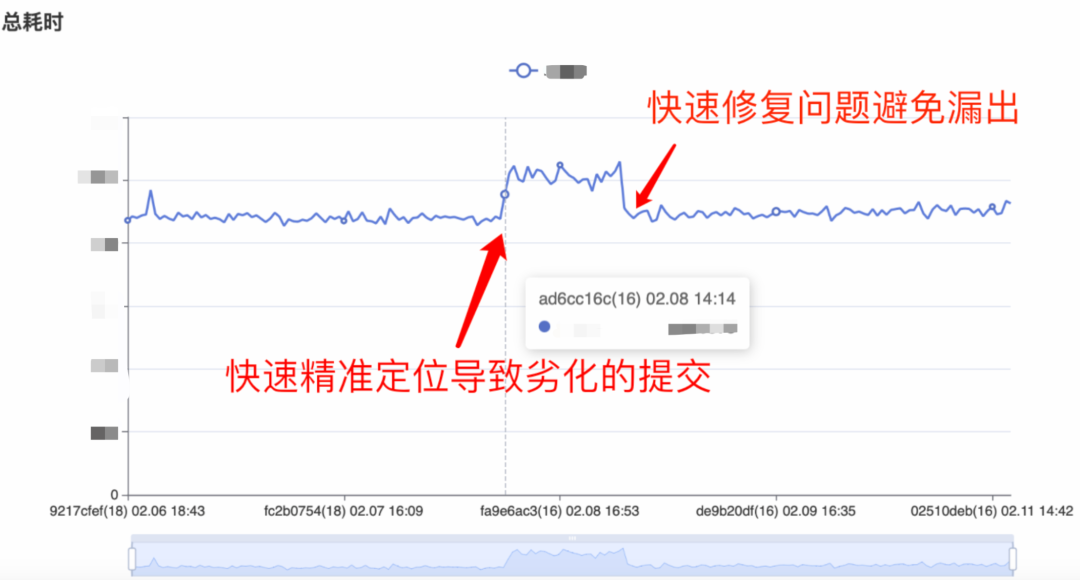
Hodor 系统还在不断迭代中,2024 年还拓展了 QQ 桌面客户端,并在运行效率方面持续优化。目前防劣化系统已经落地了 QQ 各平台。
防劣化系统从 0 到 1 迭代了将近三年的时间。从验证可行性跑通最小闭环,到搭建群控机架一次次为集群扩容,实属不易。其中涉及到大量的方案讨论甚至推翻,很多思路和实现细节是业界找不到公开方案的,只能自己摸索。
在建设过程中我们遇到了不少很底层的问题需要与厂商沟通,比如与 Apple 的技术专家们线上和线下交流过程中也学到了不少,在此也感谢 Apple。
客户端的性能稳定性防劣化是一个很复杂的话题,而且只有体量足够大的业务才会面临更多的挑战。正因为我们面对的很多问题业界都无先例可循,所以也期待行业内后续有更多的分享和交流。同时,我们也期望 Hodor 不仅在性能稳定性方面发挥作用,未来也会把手 Q 研发效能的各项指标集成进来。
-End-