SQLite3中可以使用 BEGIN TRANSACTION 和 COMMIT TRANSACTION 来开始和结束一个事务, 使用 ROLLBACK 来回滚未被提交(COMMIT)的事务. 如果没有添加这些事务语句, SQLite3会为每条SQL语句加上一个事务. 要想优化SQLite3的性能, 那么必须要了解SQLite3中一次事务执行过程.
SQLite 的事务
初始状态
数据库打开后, 未进行任何数据库操作时大概是下图的状态.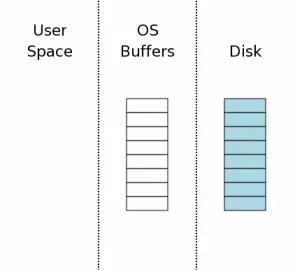
这里分了三个部分
- 左面是用户空间
- 中间是内核缓存区(文件的读写缓存)
- 右边是物理磁盘设备(iOS的闪存).
在SQLite中数据最小的读写单位扇区(sector), 通常是512B, 图中每个小矩形代表一个扇区. 蓝色代表未更改的原始数据, 中间白色表示是空的, 即此时数据没有读取到内核缓存区.
准备读取(申请共享锁)
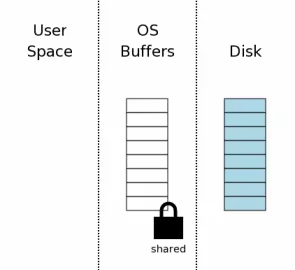
任何写操作都会先申请共享锁, 因为写之前要读取数据库的schema, 插入和修改的位置等. 在读取操作之间前申请共享锁(Shared). 申请共享锁是为了防止其它线程对数据库进行写操作, 而保证读取时数据不被修改. 这时其它数据库的读取操作依然可以正常执行.
读取数据
加了共享锁之后就开始读取数据了, 此时将磁盘上的页复制到了缓冲区
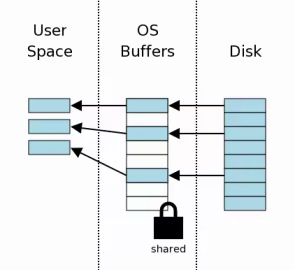
这里读取了3个扇区的数据, 读取时通过系统文件读取调用, 会从内核缓存中拷贝到用户空间.
准备修改数据(加写锁)
数据读取完毕后, 就准备开始修改数据了, 修改数据之前首先申请保留锁(Reserved), 保留锁可以和其它进程的共享锁同时存在, 此时其他进程仍可以申请新的共享锁,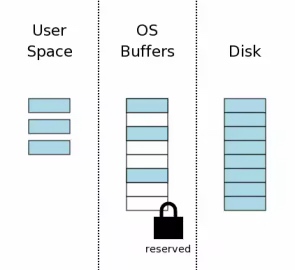
建立回滚日志
开始写操作之前, 先建立一个回滚日志文件, 以便进行回滚操作. 将更改之前的旧数据保存到回滚日志文件中. 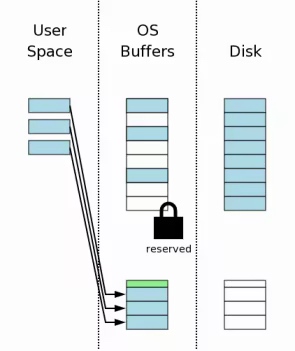
回滚日志文件包含一个头信息(绿色部分), 记录回滚必要信息, 后面是磁盘原本的页信息
在用户空间中修改数据
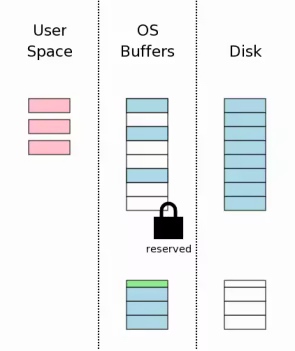
用户空间可以开始写数据了, 图中粉色表示已修改的数据.
冲(fsync)回滚日志文件
用户空间修改数据后, 未确保回滚日志文件可靠, 必须把回滚日志文件冲入物理磁盘进行持久存储. 这样以确保内核崩溃或断电后依然可恢复数据.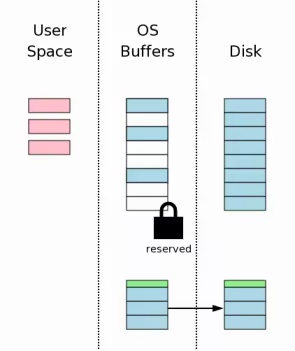
开始真正写文件(申请独占锁)
准备开始真正的写文件了, 要申请独占锁(EXCLUSIVE). 独占锁可以和已经打开的共享锁同时存在, 但不允许新建共享锁了. 这里其实是两步,
- 申请挂起锁(Pending), 数据库有了挂起锁后, 便不再允许新增共享锁,
- 等待共享锁全部释放, 挂起锁会变成独占锁, 此时不再允许新的读操作
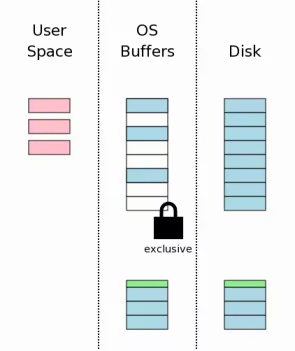
写数据库文件
现在可以安全的写数据文件了, 将用户空间的业信息写入到磁盘缓冲区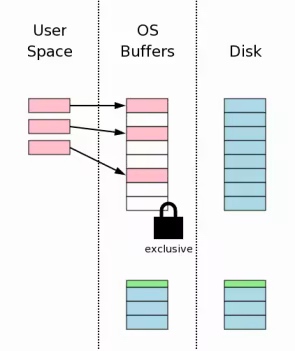
冲(fsync)数据库文件
冲数据库文件到持久存储设备, 这一步是最耗时的.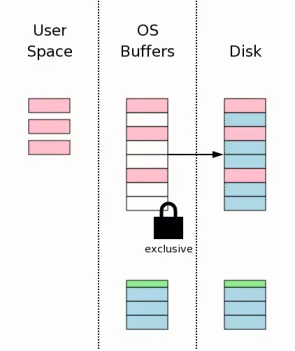
删除回滚日志
冲入数据库文件后才能删除回滚日志, 确保内核崩溃或断电后依然可恢复数据.
释放锁
释放独占锁, 数据库可以开始新的读写操作.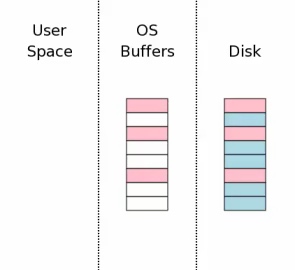
过程分析
为确保ACID, 一次数据库事务竟需要这么多步骤. 下面对此过程进行分析一下:
- 一次文件创建(回滚日志)
- 两次文件写入
- 两次文件冲入(回滚日志, 数据库文件)
- 一次文件删除(回滚日志)
- 加了3次锁, 最后一次不允许读取
优化: 减少事务,合并多条更新操作为一个事务
事务是很耗时的操作, SQLlite默认会给每条SQL语句创建一个事务. 为了提高性能, 可以将多个操作合并为一个事务.
实测一个场景需要连续写入 1000 次, 一个事务只提交一次写操作, 耗时 10 秒, 但是一个事务中将 1000 次一起提交, 耗时 0.6 秒, 长事务 能解决一些场景的性能问题.
ACID
- Atomicity 原子性: 要么成功, 要么失败
- Consistency 一致性: 让数据库系统从一种状态变更为另一种状态,但是事务开始前后数据库的完整性约束等特性不会被破坏.即执行前后状态保持一致.
- Isolation 隔离性: 两个事务读写对象会被相互隔离,这一特性是通过数据库中的锁进行实现.
- Durability 持久性: 即存盘操作,提交成功后数据能正确落盘,数据能得到持久化保障
WAL
WAL的全称是write ahead log, 使用WAL文件能够提高数据库并发性能.
WAL文件替代了回滚日志, 它的优点:
- 大多数情况下, 速度有质的提升
- 更好的并发性能, 由于读不会
block写, 写也不会block读 - 磁盘
I/O操作更序列 - 使用更少的
fsync(), 所以在低质量磁盘上更不容易出问题
缺点:
- 无法改变
Page的大小 WAL在读数量远高于写数量的应用中会略慢1%-2%- 生成额外的
WAL文件(大概每个数据库 2~6M)
WAL的原理:
在引入WAL机制之前, SQLite使用rollback journal机制实现原子事务.
rollback journal机制的原理是: 在修改数据库文件中的数据之前, 先将修改所在分页中的数据备份在另外一个地方, 然后才将修改写入到数据库文件中; 如果事务失败, 则将备份数据拷贝回来, 撤销修改; 如果事务成功, 则删除备份数据, 提交修改.
WAL机制的原理是: 修改并不直接写入到数据库文件中, 而是写入到另外一个称为WAL的文件中; 如果事务失败, WAL中的记录会被忽略, 撤销修改; 如果事务成功, 它将在随后的某个时间被写回到数据库文件中, 提交修改.
同步WAL文件和数据库文件的行为被称为checkpoint(检查点), 它由SQLite自动执行, 默认是在WAL文件积累到1000页修改的时候; 当然, 在适当的时候, 也可以手动执行checkpoint(sqlite3_wal_checkpoinnt()). 执行checkpoint之后, WAL文件会被清空.
在读的时候, SQLite将在WAL文件中搜索, 找到最后一个写入点, 记住它, 并忽略在此之后的写入点(这保证了读写和读读可以并行执行); 随后, 它确定所要读的数据所在页是否在WAL文件中, 如果在, 则读WAL文件中的数据, 如果不在, 则直接读数据库文件中的数据.
在写的时候, SQLite将之写入到WAL文件中即可, 但是必须保证独占写入, 因此写写之间不能并行执行.
WAL 写数据流程
与传统日志模式不同, WAL日志模式可以实现读写并发, 其写入数据的流程图如下: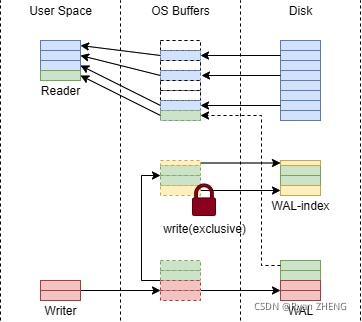
这张图比较复杂, 解读一下:
- WAL的锁机制与传统日志模式完全不同. 首先锁是作用在
WAL-index上的, 而不是WAL日志文件本身; 其次WAL中的锁均具备两种属性: 共享锁与独占锁, 因此这里write(exclusive)表示WAL-index文件上锁WAL_WRITE_LOCK, 且属性为独占锁; Reader指代读请求, 每次读请求实际上都会去寻找WAL-index的比对情况, 确认是从DB文件中读取, 还是从WAL日志文件中读取; 图中绿色数据即表示WAL日志文件中更新后的数据;Writer指代写请求, 写入前会将WAL-index文件上锁(写锁, 独占), 然后将改动后的数据谁加到WAL日志文件有效数据的末尾(mxFrame帧之后), 然后将新增的帧索引以及页号更新到WAL-index文件中, 随后更新WAL-index文件的文件头, 提示mxFrame发生改变, 最后释放写锁;WAL-index是一个记录WAL日志记录情况的索引文件, 以共享内存的方式提供快速索引, 减少磁盘IO, 同时为跨进程通信提供高速支持- 当
WAL日志文件积累到一定体积后, 会触发SQLite的Checkpoint机制, 将WAL日志文件中的新数据写入到DB文件中;
简单说, 原来是对磁盘缓存区上独占锁, 现在只需要对 WAL 中的某一条记录上锁.
开启 WAL 方法
1 | sqlite3* DB = nil; |
执行完后会生成 {SQLite}-wal 文件(6M 左右)以及 ${SQLite}-shm 文件(100k左右), 数据库性能提升 10%左右.
开启之后, WAL 模式会持久存在, 即下次启动哪怕不执行PRAGMA journal_mode=WAL 仍然会默认以WAL模式打开数据库文件.
关闭方式是开开数据库后执行一次sqlite3_exec(DB, "PRAGMA journal_mode=DELETE;", 0, 0, 0); 恢复到默认即可.