正则表达式:使用、原理和优化
什么是正则表达式
正则表达式描述了一种字符串匹配模式,包括普通字符(如a-z之间的字母)和特殊字符(比如.、^、$等有特殊意义的专用字符)。
典型的搜索和替换操作要求我们提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。
比如,需要验证用户输入的电话号码符合###-###-#### 格式(#表示一个数字)时,如果不使用正则表达式,则需要遍历用户输入的每个字符,确保#位置输入的是数字,非#位置输入的是-。而使用正则表达式的话,一行语句就可以完成验证功能。
1 | // 不使用正则表达式验证输入 |
此外,一个好的正则表达式可以比非正则表达式更快地完成验证工作,如上述2种实现中,使用正则表达式的验证方式总体快于循环验证用户输入的方式。这就是正则表达式的强大之处。
正则表达式的主要功能包括:
- 进行数据验证:验证一个字符串是否符合某种模式,如电话号码模式或信用卡号码模式。
- 替换文本:可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
- 基于模式匹配从字符串中提取子字符串。
本文将先介绍正则表达式的两种匹配方式–字符匹配或位置匹配,然后对一种重要符号(括号)的使用进行总结,然后简单介绍正则表达式的匹配原理,并提出一些优化正则表达式的方法,最后通过3个案例展示正则表达式在实际场景中的应用。
字符匹配
正则表达式之所以强大,是因为其能实现模糊匹配来匹配字符串中的某种模式。而有些情况下,允许匹配多种模式中的一种,这时可以使用多选分支。下面我们将详细介绍。
两种模糊匹配:量词和字符组
模糊匹配分为两个方向:横向模糊和纵向模糊。
横向模糊
横向模糊:被匹配字符串的出现次数不是固定的。实现横向模糊的方式是使用量词 {m,n} ,表示前面的字符连续出现最少m次,最多n次的模式。
1 | var regex = /ab{2,5}c/g; |
量词的简写形式如下表:
| 量词简写 | 具体含义 |
|---|---|
| {m,} | 至少出现m次 |
| {m} | 等价于{m,m},表示出现m次 |
| ? | 等价于{0,1},出现一次或不出现 |
| + | 等价于{1,},至少出现一次 |
| * | 等价于{0,},出现任意次或不出现 |
纵向模糊
纵向模糊:某一位置的字符不确定,有多种可能。实现纵向模糊的方式是使用字符组,如 [abc] ,表示该字符可以是a、b、c中的任何一个。
1 | var regex = /a[123]b/g; |
- 范围表示法:如果字符组中的字符特别多,可以使用范围表示法。如
[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。由于连字符在范围表示法中有特殊用途,在作为普通字符进行匹配时,需要转义或者不放在两个字母之间,如要匹配“a”、“-”、“z”,可以使用[az-]、[-az]或[a\-z]。 - 排除字符组:可以用方括号中的尖号表示排除方括号中的选项。如
[^abc]用于匹配除了a、b、c的其他值。 - 为了简化书写,一些常用的字符组存在简写形式:
| 字符组简写形式 | 具体含义 |
|---|---|
| \d | [0-9]。表示是一位数字。 |
| \D | [^0-9]。表示除数字外的任意字符。 |
| \w | [0-9a-zA-Z_]。表示数字、大小写字母和下划线。 |
| \W | [^0-9a-zA-Z_]。非单词字符。 |
| \s | [\t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。 |
| \S | [^\t\v\n\r\f]。 非空白符。 |
| . | [^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。 |
- 匹配任意字符:通配符排除了换行符、回车符等,如果需要匹配任意字符,可以使用
[\d\D]、[\w\W]、[\s\S]和[^]中任何的一个。除此之外,在ES2018中增加了标志位s(“dotAll”),以使.可以匹配任意字符,如 /foo.bar/s 中, . 就可以匹配换行符、回车符、行段分隔符。
上面说的纵向匹配都是匹配一个字符,如果需要匹配多个子模式中的任意一个,可以使用多选分支。如 /p1 | p2 | p3/ 支持匹配子模式p1或p2或p3中的任意一个。
量词的两种匹配方式:贪婪匹配与惰性匹配
量词的匹配默认是贪婪的,即会尽可能多的匹配。 举个🌰,需要从下面的HTML中提出id="container"。
1 | <div id="container" class="main"></div> |
如果将正则表达式写成 /id=".*"/ ,匹配到的内容将会是 id="container" class="main" 。因为通配符 . 可以匹配双引号,而量词 * 默认会进行贪婪匹配,当遇到 container 后面双引号时,是不会停下来,会继续匹配,直到遇到最后一个双引号为止。
解决这个问题的方法,就是使用惰性匹配。
惰性匹配(?):尽可能少的匹配,在量词后面加 ? 就能实现惰性匹配。
| 惰性匹配的量词 | 贪婪匹配的量词 |
|---|---|
| {m,n}? | {m,n} |
| {m,}? | {m,} |
| ?? | ? |
| +? | + |
| *? | * |
回到上面的例子,在量词 * 后面加 ? 实现惰性匹配,会在遇到的第一个双引号处匹配成功。
1 | // 贪婪匹配 |
另外,多选分支在匹配时也是惰性的,前面的子模式匹配上后就不会匹配后面的子模式了。
正则表达式位置匹配
什么是位置?
位置是相邻字符之间的位置。如下图所示,箭头所指的地方就是“hello”这个单词中的位置。位置的主要作用是替换和条件限制。位置本身无法匹配字符串的内容,但是可以为内容匹配提供限制条件。
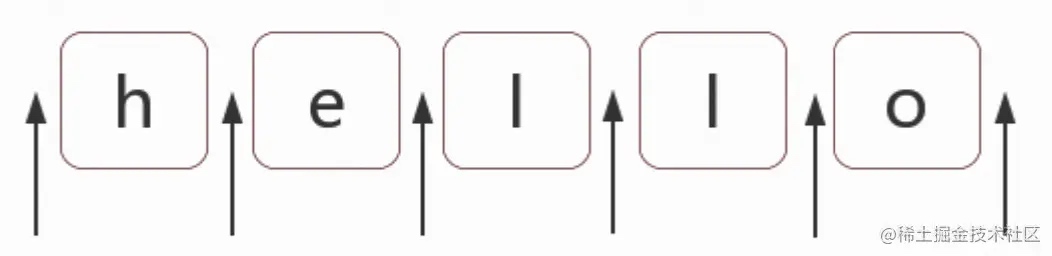
如何匹配位置?
匹配位置是通过以下6个锚。在表格的第三列中,将对应锚匹配的位置替换成#,来可视化地展示锚匹配到的位置。
| 锚 | 含义 | 用 # 替换锚匹配的位置 |
|---|---|---|
| ^ | 匹配行开头。多行匹配中匹配每行开头 | “hello”.replace(/^/g, ‘#’); // => “#hello” |
| $ | 匹配行结尾。多行匹配中匹配每行结尾 | “hello”.replace(/$/g, ‘#’); // => “hello#” |
| \b | 匹配单词边界,即 \w 和 \W 之间的位置 | “[JS] Lesson_01.mp4”.replace(/\b/g, ‘#’); // => “[#JS#] #Lesson_01#.#mp4#” |
| \B | 匹配非单词边界,即所有 \b 不匹配的位置 | “[JS] Lesson_01.mp4”.replace(/\B/g, ‘#’); // => “#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4” |
| (?=p) | 匹配子模式 p 前面的位置 | “hello”.replace(/(?=l)/g, ‘#’); // => “he#l#lo” |
| (?!p) | 匹配所有 (?=p) 不匹配的位置 | “hello”.replace(/(?!l)/g, ‘#’); // => “#h#ell#o#” |
| (?<=p) | 匹配子模式 p 后面的位置(ES2018) | “hello”.replace(/(?<=l)/g, ‘#’); // => “hel#l#o” |
| (?<!p) | 匹配所有 (?<=p) 不匹配的位置(ES2018) | “hello”.replace(/(?<!l)/g, ‘#’); // => “#h#e#llo#” |
理解位置
可以将位置理解为空字符“”,因此将字符之间的位置写成多个不会影响匹配。 如 /^^hello$$$/ 和 /(?=he)^^he(?=\w)llo$\b\b$/ 都可以匹配”hello”。
正则表达式括号的作用
分组和分支
括号是正则表达式中的重要符号。在正则表达式中括号主要有2种作用:分组和分支。
前面提到 (p1|p2) 表示匹配p1或p2,这是分支的作用。
括号分组的功能则更加强大,支持进行数据提取和替换操作。以 /(\d{4})-(\d{2})-(\d{2})/ 为例,每个被括号中内容匹配到的子串都可以使用以下3种方法之一被提取出来。
| 提取方法 | 示例 |
|---|---|
| 字符串的match方法。得到的数组中,下标1处的是从第一组提出的子串,下标2处的是从第二组提出的子串,以此类推。 | var regex = /(\d{4})-(\d{2})-(\d{2})/;var string = “2017-06-12”;console.log( string.match(regex) );// => [“2017-06-12”, “2017”, “06”, “12”, index: 0, input: “2017-06-12”] |
| 正则实例对象的exec方法。得到的数组中,下标1处的是从第一组提出的子串,下标2处的是从第二组提出的子串,以此类推。 | var regex = /(\d{4})-(\d{2})-(\d{2})/;var string = “2017-06-12”;console.log( string.match(regex) );// => [“2017-06-12”, “2017”, “06”, “12”, index: 0, input: “2017-06-12”] |
| 构造函数的全局属性$1~$9。$1表示从第一组提出的子串,$2表示从第二组提出的子串,以此类推 | var regex = /(\d{4})-(\d{2})-(\d{2})/;var string = “2017-06-12”;regex.test(string); // 正则操作即可,例如//regex.exec(string);//string.match(regex);console.log(RegExp.$1); // “2017”console.log(RegExp.$2); // “06”console.log(RegExp.$3); // “12” |
在替换操作中使用捕获组捕获的内容:在replace函数中,可以通过$1获取第一个分组捕获的内容,通过$2获取第二个分组捕获的内容,以此类推。
比如需要将yyyy-mm-dd 格式的日期,替换成 mm/dd/yyyy 格式。
1 | var regex = /(\d{4})-(\d{2})-(\d{2})/; |
反向引用
有时需要在正则本身里引用之前出现的分组,用于描述前后两部分内容一致的模式,这是反向引用。
在正则中, \1 表示前面从头开始的第1个分组,\2 表示前面从头开始的第2个分组,以此类推。
如需要写一个匹配三种日期格式的正则:2016-06-12、2016/06/12、2016.06.12。最先想到的可能是 /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/ ,前两个数字和后两个数字之间的分隔符可能是-、/或.。但是这个正则表达式也能匹配前后两个分隔符不一致的情况,如 2016-06/12 。
对于这种需要前后两个分隔符保持一致的模式,可以使用反向引用构造正则表达式:/\d{4}(-|/|.)\d{2}\1\d{2}/ 。\1,表示的引用之前的那个分组 (-|\/|\.) 。不管它匹配到什么(比如 -),\1 都匹配那个同样的具体某个字符。
一些问题:
- 括号嵌套时,如何确定分组顺序?分组顺序以左括号为准,左括号在前的分组顺序在前。如
/^((\d)(\d(\d)))\1\2\3\4$/中,第一个左括号对应的分组((\d)(\d(\d)))是第一个分组(\1);第二个左括号对应的分组(\d)是第二个分组(\2)…… - 分组后有量词会怎么样?分组捕获到的数据是括号中内容的最后一次匹配。
1 | var regex = /(\d)+/; |
此时反向引用引用的也是括号中内容的最后一次匹配。
1 | var regex = /(\d)+ \1/; |
非捕获括号
上述括号都会捕获它们匹配的数据,以便后续引用。如果只想使用括号最原始的功能,但不捕获括号内容,也不会引用括号捕获的内容,可以使用非捕获括号 (?:p) 和 (?:p1|p2|p3) 。
比如 /(?:\d{4})-(?:\d{2})-(?:\d{2})/.exec("2017-06-12") 就不会捕获到“2017”、“06”和“12”,而 /(\d{4})-(\d{2})-(\d{2})/.exec("2017-06-12") 会。
正则表达式回溯法原理
正则表达式匹配字符串的方法是回溯法。回溯法的本质是深度优先搜索算法,即从问题的初始状态出发,搜索从这种状态出发能达到的所有状态,当一条路无法再前进时,后退一步或若干步(回溯),从另一种可能的状态再出发,继续搜索,直到所有状态都试探过或者匹配完成。了解正则表达式的匹配原理有助于我们写出高效的正则表达式,避免不必要的回溯。
量词的贪婪匹配
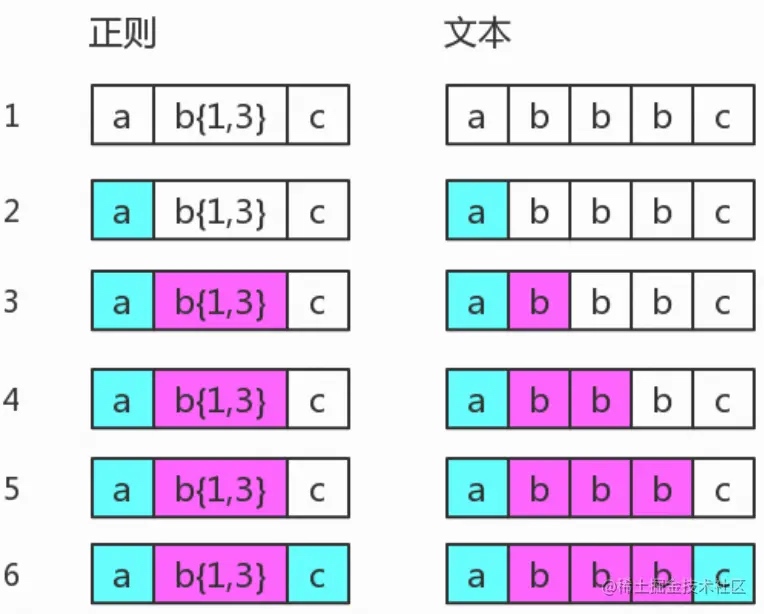
量词在贪婪匹配时,会从多到少尝试,即先尝试匹配出现最多的可能性,匹配不成功时再回退,重新尝试出现较少的可能性。
假设正则是 /ab{1,3}c/ 。当目标字符串为”abbbc”时,匹配过程就没有回溯。由于量词的匹配默认是贪婪的,会优先匹配a和c之间有3个b的可能性,而目标字符串满足这种模式,故可以一次匹配成功。
而当目标字符串为”abbc”时,匹配过程就会存在回溯。因为第一次试图匹配abbbc的尝试失败了,所以回退一步,尝试匹配a和c之间只有2个b的情况。
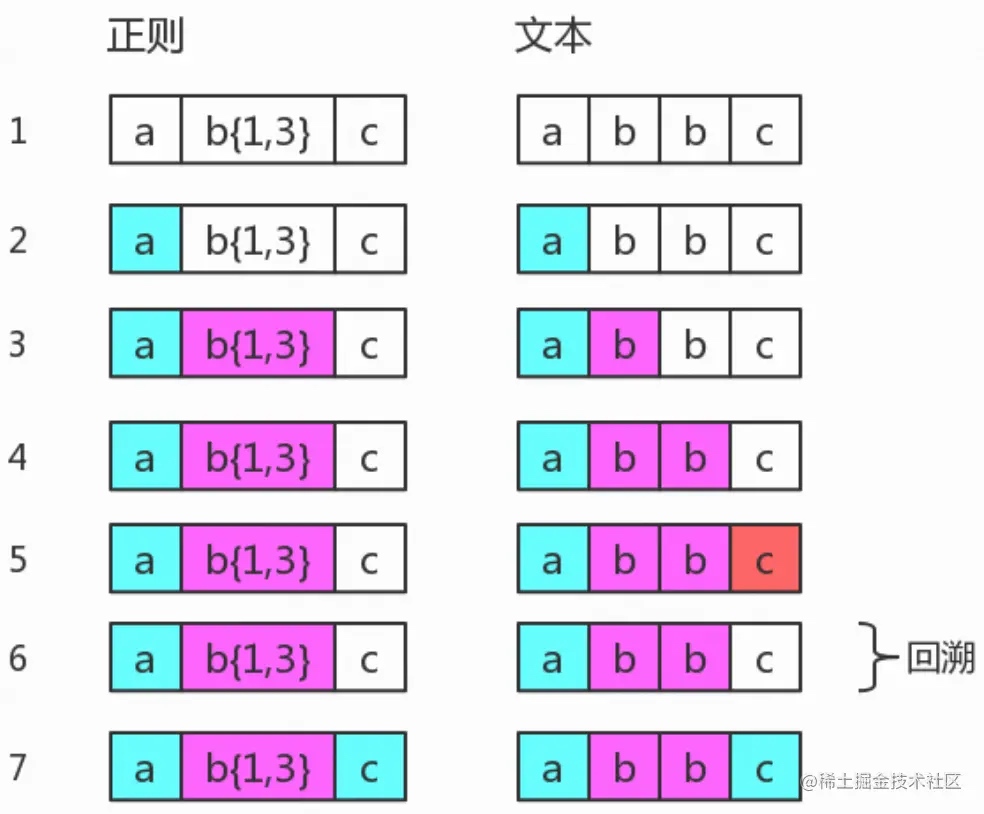
图中第 5 步表示匹配不成功。此时 b{1,3} 已经匹配到了 2 个字符 “b”,准备尝试第三个时, 结果发现接下来的字符是 “c”。那么就认为 b{1,3} 就已经匹配完毕。然后状态又回到之前的状态(即第 6 步与第 4 步一样),最后再用子表达式 c,去匹配字符 “c”。此时整个表达式匹配成功了。
图中的第 6 步,从第一个不匹配模式的字符回退的过程就是“回溯”。
量词的惰性匹配
量词在惰性匹配时,会首先尝试匹配出现次数最少的可能性,如果此时整体无法匹配,那么会回退,尝试匹配出现次数第二少的可能性,看这样能否完成整体的匹配。如:
1 | var string = "12345"; |
匹配过程如下图: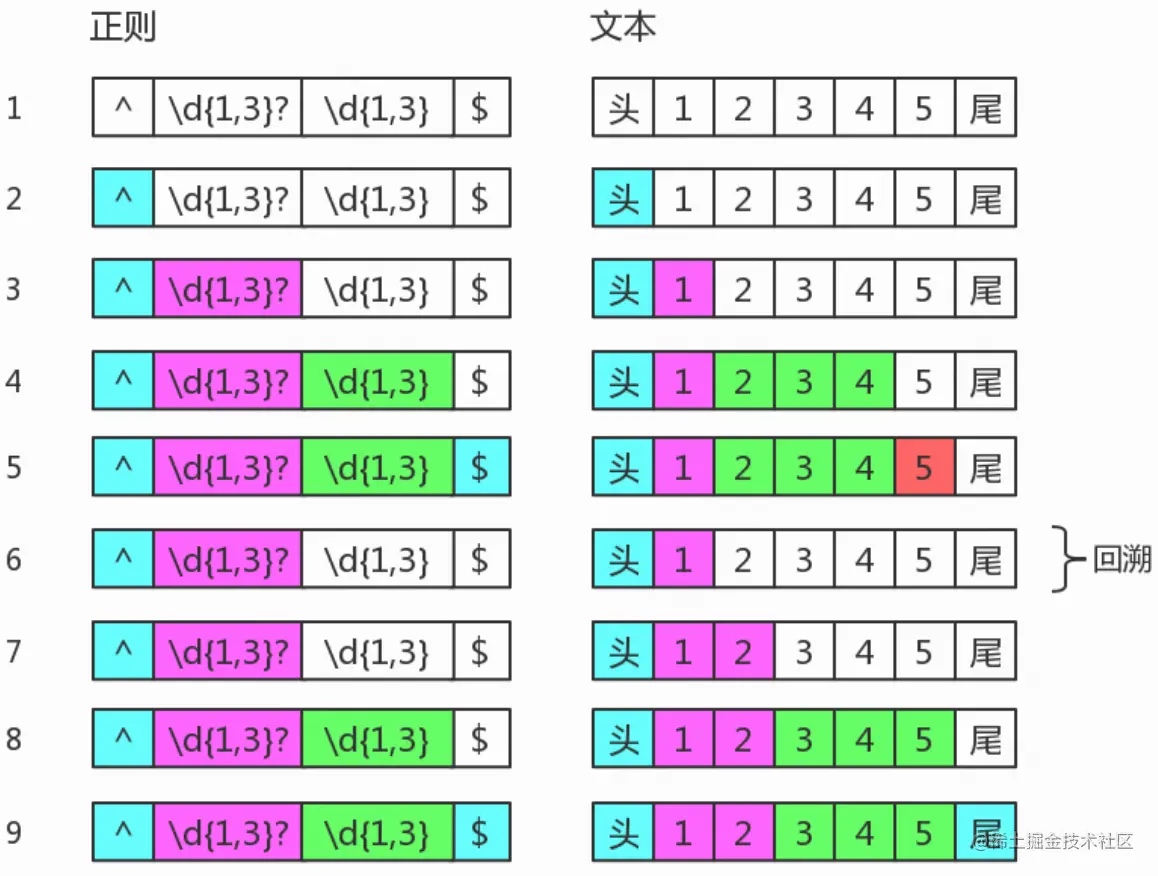
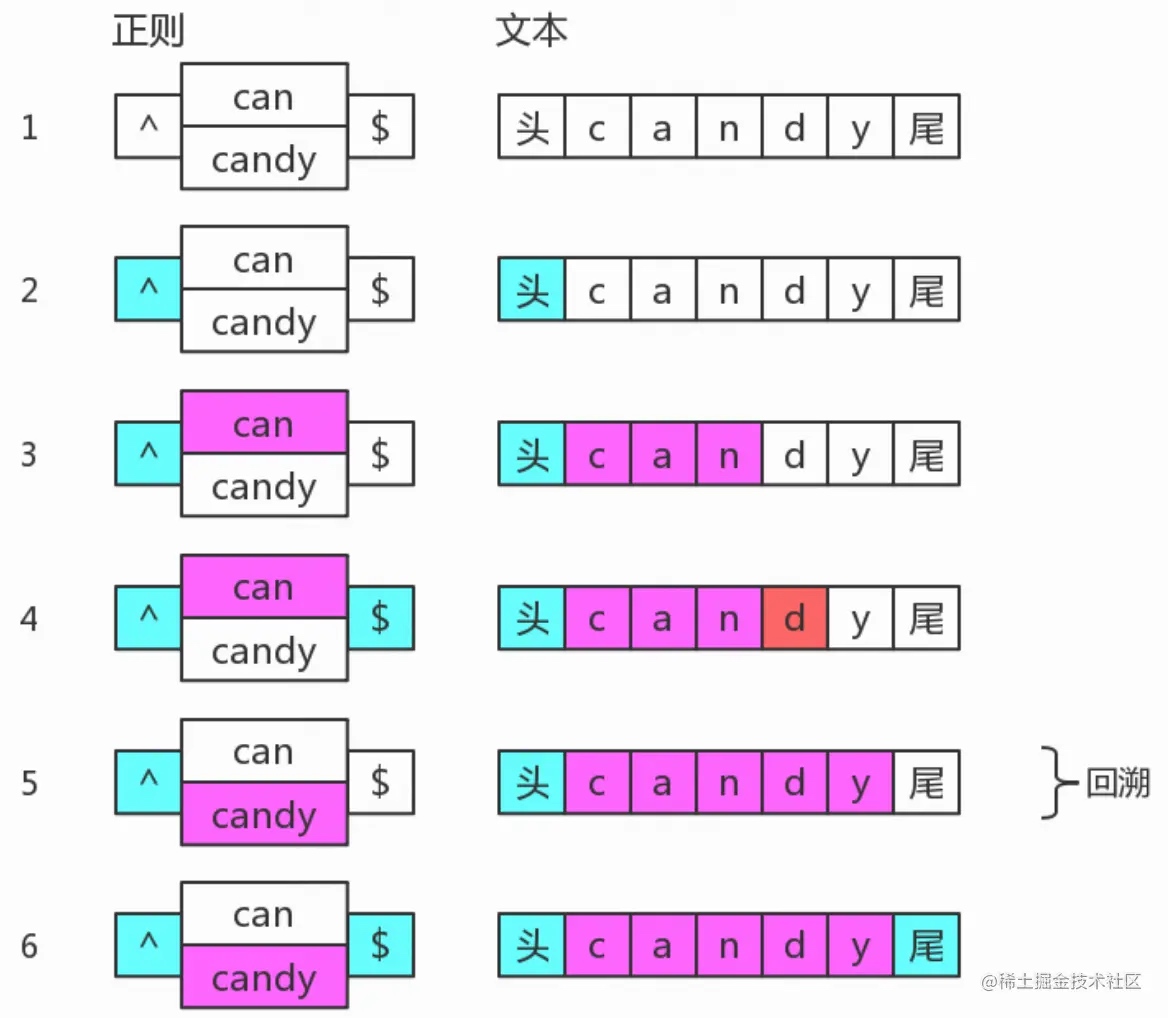
分支结构的匹配
分支结构也是惰性的,在匹配过程中会从前往后挨个尝试,如果前面的满足了,后面就不会再实验了。
但是当前面的分支结构形成了局部匹配,接下来表达式整体却不匹配时,仍会继续尝试剩下的分支。这种尝试也可以看成一种回溯。
如正则表达式 /^(can|candy)$/ ,目标字符串为“candy”,匹配过程如下:
正则表达式的优化
了解了正则表达式的匹配原理后,就可以对我们写出的正则表达式进行优化。
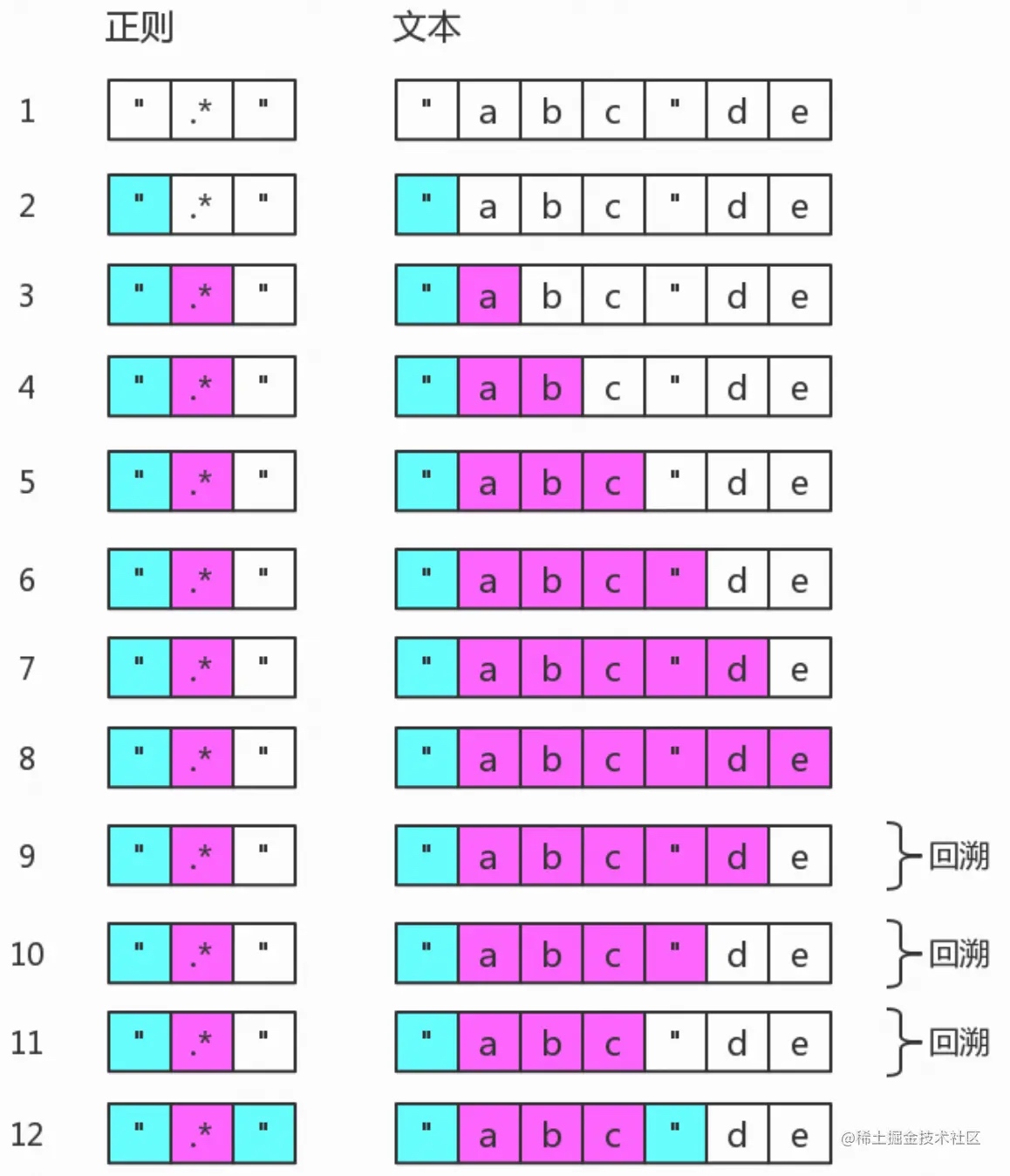
使用具体的字符组代替通配符来消除回溯
如目标字符串为 “abc”de ,如果使用 /".*"/ 进行匹配的话,虽然也可以正确匹配到”abc”,但是会比使用 /"[^"]*"/ 多产生2次回溯。因为通配符 . 可以匹配双引号,而量词的匹配默认是贪婪的,因此 .* 会匹配尽可能多的字符,而不会在第二个双引号处停下。但是 [^"] 不会匹配双引号,所以会在第二个双引号处停止匹配。
使用非捕获型分组:减少空间占用
括号的作用之一是捕获分组和分支里的数据,捕获的内容需要内存来保存。因此,当不需要使用分组引用和反向引用时,可以使用非捕获分组。
如 /^[-]?(\d\.\d+|\d+|\.\d+)$/ 可以修改成 /^[-]?(?:\d\.\d+|\d+|\.\d+)$/。
不同语言的正则表达式
不同语言中,正则表达式的基础用法相同,但是由于使用的正则表达式引擎不同,不同语言的正则表达式用法会稍有差异。比如PHP和JavaScript中的正则表达式功能有不同之处,因为PHP使用PCRE引擎,而JavaScript使用ECMA规范。不同的正则表达式引擎实现了不同的功能集合,且时空效率有所不同。
各正则表达式引擎提供的功能对比详见正则表达式引擎对比表。
JavaScript中的正则相关API
JavaScript有8个与正则相关的API,其中5个是字符串实例上的API,3个是正则表达式实例上的API。
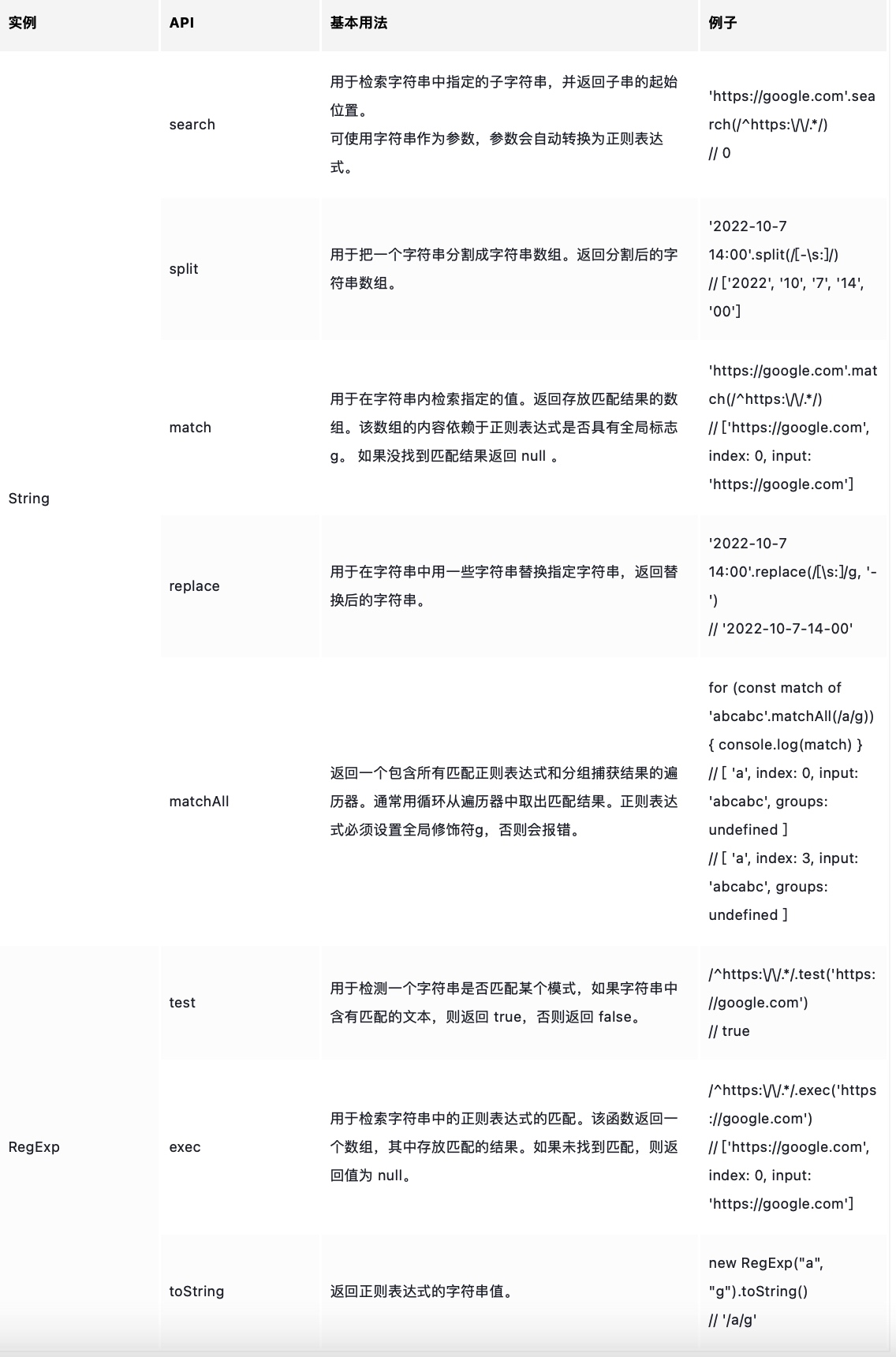
⚠️ 注意事项:
- match返回结果的格式,与正则对象是否有修饰符g有关:
- 没有g时,返回的是标准匹配格式,即数组的第一个元素是整体匹配的内容,接下来是分组捕获的内容,然后是整体匹配的第一个下标,最后是输入的目标字符串。
- 有g时,返回的是所有匹配的内容,不包括下标。
1 | var string = "2017.06.27"; |
- exec比match更强大:match带修饰符g时,就不返回关键信息index了,而exec方法可以解决这个问题。
1
2
3
4
5
6
7
8
9var string = "2017.06.27";
var regex2 = /\b(\d+)\b/g;
var result;
while ( result = regex2.exec(string) ) {
console.log( result, regex2.lastIndex );
}
// => ["2017", "2017", index: 0, input: "2017.06.27"] 4
// => ["06", "06", index: 5, input: "2017.06.27"] 7
// => ["27", "27", index: 8, input: "2017.06.27"] 10
此外,不带修饰符g时,虽然match和exec在执行结果上是等效的,但是exec在控制台中会提前执行,而match由于可能有副作用,在Chrome控制台中就不会提前执行。比如在控制台输入 /123/.exec('123456') ,即使不回车也能看到执行结果;而输入'123456'.match(/123/),只有回车之后才能看到执行结果。在控制台中反复调整比较复杂的正则表达式时,如果使用 match ,就需要不断回车、上箭头、修改、回车了,因此用 exec 能稍微快一点。
- 修饰符
g对exec和test函数的影响:带修饰符g时,正则表达式对象会有一个lastIndex属性表示上次匹配结果的后一个位置,每次匹配都会从lastIndex开始匹配,即使匹配的字符串不相同;而不带g时,都是从字符串第0个字符处开始匹配。下面代码中的第三次调用test,因为这一次尝试匹配,开始从下标lastIndex,即 3 位置处开始查找,因此就找不到了。
1 | var regex = /a/g; |
实际案例
一. 数字格式化
将数字转换为带千位分隔符的形式:如把 “12345678”,变成 “12,345,678”。
- 加入逗号:使用
/(?=(\d{3})+$)/g在每3位数字之前加入逗号。其中(\d{3})+$表示从结尾向前的3个、6个、9个……数字,/(?=(\d{3})+$)/表示从结尾向前的3个数字之前的位置、6个数字之前的位置、9个数字之前的位置……。
1 | var result = "12345678".replace(/(?=(\d{3})+$)/g, ',') |
- 去掉开头的逗号:使用上述正则多验证几个案例就会发现,一旦数字长度是3的倍数,就会在数字前面的位置也加上逗号,因此需要匹配到的位置不能是开头。可以用
(?!^)表示匹配开头以外的位置。
1 | var regex = /(?!^)(?=(\d{3})+$)/g; |
- 支持字符串包含多个数字的情况:如要把 “12345678 123456789” 替换成 “12,345,678 123,456,789”。直接将
(?!^)换成(?!\b)即可,表示匹配的位置不能是单词边界。而\B本身表示非单词边界的位置,因此可以将(?!\b)进一步简化为\B。
1 | var string = "12345678 123456789", |
二. 表单校验-验证密码
表单校验是正则表达式最常见的应用场景。 用户输入中密码设置的常见要求是:密码长度 6-12 位,由数字、小写字母和大写字母组成,但必须至少包括 2 种字符。 我们可以先简化这个条件:
- 匹配6~12位,由数字、小写字母和大写字母组成的密码的正则表达式很简单:
/^[0-9A-Za-z]{6,12}$/ - 满足条件1,但是只要求必须包含1种指定字符:比如只要求必须包含数字,可以使用
(?=.*[0-9])^,即开头处、后面的字符串匹配“任何多个任意字符,后面有一个数字”这一模式的前面的位置:/(?=.*[0-9])^[0-9A-Za-z]{6,12}$/ - 满足条件1,但是要求必须同时包含2种指定字符:如必须同时包含数字和小写字母,可以使用2个2中的位置匹配模式进行限制
(?=.*[0-9])(?=.*[a-z]):/(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,12}$/
现在来匹配完整的密码模式。可以把“必须至少包括2种字符”的要求变成:同时包含数字和小写字母,或同时包含数字和大写字母,或同时包含小写字母和大写字母。因此校验密码的正则表达式可以写成:
1 | var regex = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[A-Z]))^[0-9A-Za-z]{6,12}$/; |
- 另一种解法:“至少包含两种字符”也可以理解为,不能全都是数字,也不能全都是小写字母,也不能全都是大写字母,因此也可以写成以下形式
1
2
3
4
5
6
7var regex = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;
console.log( regex.test("1234567") ); // false 全是数字
console.log( regex.test("abcdef") ); // false 全是小写字母
console.log( regex.test("ABCDEFGH") ); // false 全是大写字母
console.log( regex.test("ab23C") ); // false 不足6位
console.log( regex.test("ABCDEF234") ); // true 大写字母和数字
console.log( regex.test("abcdEF234") ); // true 三者都有
三. 表单校验-验证邮箱
RFC 5322:Internet Message Format规范中定义了邮箱地址规范,根据RFC5322规范编写的邮箱校验正则表达式如下:

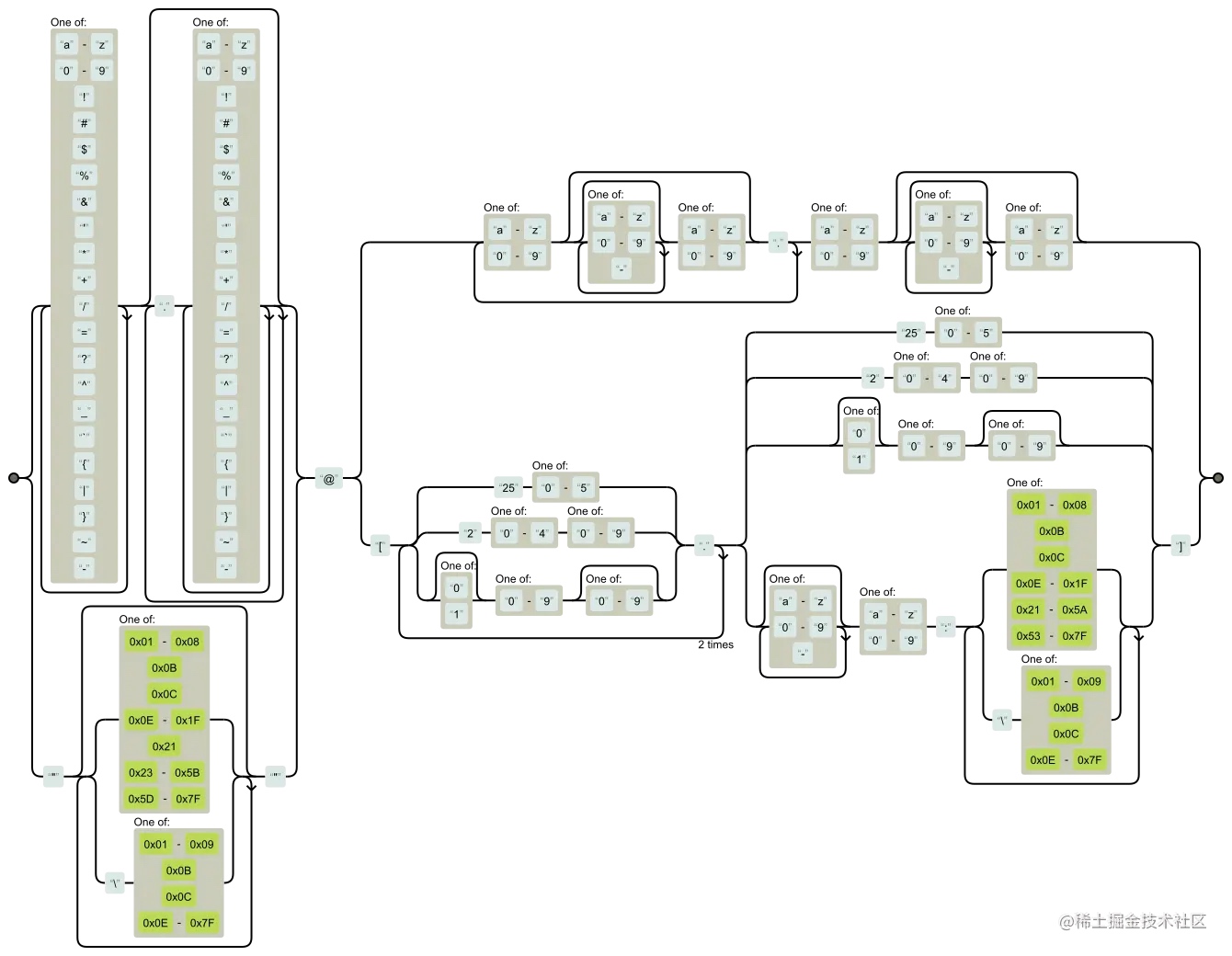
这个正则表达式包括2个部分:@前的部分和@后的部分。 @前的部分允许2种模式:
- 一系列字母、数字和特定符号,包括一个或多个点。但是点不能连续出现,或者出现在邮箱地址的第一位或最后一位。
- 用双引号括起来,允许任何ASCII码字符出现在双引号中,但是空白字符、双引号和反斜杠必须使用反斜杠转义。
@后的部分也允许2种模式:
- 一个完整域名,如regular-expressions.info
- 用方括号括起来的IP地址或其他可能的路由地址(需要说明的是,虽然RFC5322中规定域名字面量可以包括不可打印字符,但是目前并没有在任何规范中看到为什么不可打印字符必须出现在
(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:之后。因此这个正则表达式的最后一部分还有待考证,欢迎大家补充说明)。
虽然这是由官方标准定义的邮箱地址模式,但是并不推荐使用它来校验用户输入,因为接收输入的应用本身可能无法处理符合这个模式的所有邮箱地址。如其他可能的路由地址可能包含不可打印的ASCII字符,可能在应用中造成显示问题;再比如不是所有应用都支持在@前使用双引号或在@后使用方括号。
如果不管IP地址和其他特殊的路由地址,不支持双引号和方括号出现在邮箱地址中,可以将邮箱地址校验正则简化为如下形式:
最后,在长度方面,RFC 5322标准说明了@前的local部分最大长度为64字符,每个域名的最大长度为63字符,但是并未对整体长度进行限制。而电子邮件传输协议SMTP协议能处理的最大邮箱地址长度是254个字符,因此,在上面邮箱地址模式中加入对长度的考虑可以得到以下邮箱地址校验模式。
- 我们需要这么复杂的邮箱地址校验方法吗?
假设用户输入了一个邮箱地址john.doe@somewhere.com。这个邮箱符合RFC 5322标准,可以通过校验,但是这并不能保证这个邮箱地址存在并可以接收邮件,除非你真正向这个地址成功发送了一封邮件。因此,如果我们最终都得通过发送邮件来确认一个邮箱地址是否存在,可以使用更简单的正则表达式来校验输入,在保证不会拒绝任何已存在的邮箱地址的情况下,尽可能减少非法邮箱输入。
比如可以使用浏览器在 <input type="email" placeholder="Enter your email" /> 中用于校验输入的正则表达式:
1 | /^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$/ |
参考资料
- JavaScript正则表达式迷你书(第一版)
- regular-expressions-Email-Address
- Regular Expressions Cookbook, 2nd Edition by Jan Goyvaerts, Steven Levithan
- How to Use Regular Expressions in JavaScript – Tutorial for Beginners
- Crate email_address Email Address Regular Expression That 99.99% Works.
正则表达式相关工具网站
- 正则表达式可视化:推荐三款正则可视化工具
- 对比正则表达式和非正则表达式的执行性能:JSBench.me