<iOS应用架构谈> 学习笔记
本篇内容全部来自于 https://casatwy.com/ iOS应用架构谈 系列文章
iOS应用架构谈 开篇
架构要考虑的事情
- 调用网络API (网络) 如何让业务开发工程师方便安全地调用网络API?然后尽可能保证用户在各种网络环境下都能有良好的体验?
- 页面展示 (UI) 页面如何组织,才能尽可能降低业务方代码的耦合度?尽可能降低业务方开发界面的复杂度,提高他们的效率?
- 数据的本地持久化 (数据库) 当数据有在本地存取的需求的时候,如何能够保证数据在本地的合理安排?如何尽可能地减小性能消耗?
- 动态部署方案 iOS应用有审核周期,如何能够通过不发版本的方式展示新的内容给用户?如何修复紧急bug?
上面几点是针对App说的,下面还有一些是针对团队说的:
- 收集用户数据,给产品和运营提供参考
- 合理地组织各业务方开发的业务模块,以及相关基础模块
- 每日app的自动打包,提供给QA工程师的测试工具
这系列文章主要是回答以下这些问题:
- 网络层设计方案?设计网络层时要考虑哪些问题?对网络层做优化的时候,可以从哪些地方入手?
- 页面的展示、调用和组织都有哪些设计方案?我们做这些方案的时候都要考虑哪些问题?
- 本地持久化层的设计方案都有哪些?优劣势都是什么?不同方案间要注意的问题分别都是什么?
- 要实现动态部署,都有哪些方案?不同方案之间的优劣点,他们的侧重点?
架构设计的方法
- 搞清楚要解决哪些问题,并找到解决这些问题的充要条件
- 清楚你要做什么,业务方希望要什么
- 传的参数越少,耦合度相对而言就越小,你替换模块或者升级模块所花的的代价就越小。
- 问题分类,分模块
- 搞清楚各问题之间的依赖关系,建立好模块交流规范并设计模块
- 推演预测一下未来可能的走向,必要时添加新的模块,记录更多的基础数据以备未来之需
- 先解决依赖关系中最基础的问题,实现基础模块,然后再用基础模块堆叠出整个架构
- 打点,跑单元测试,跑性能测试,根据数据去优化对应的地方
总而言之就是要遵循这些原则:自顶向下设计(1,2,3,4步),自底向上实现(5),先测量,后优化(6)。
什么样的架构师是好架构师?
- 每天都在学习,新技术新思想上手速度快,理解速度快
- 业务出身,或者至少非常熟悉公司所处行业或者本公司的业务
- 熟悉软件工程的各种规范,踩过无数坑。不会为了完成需求不择手段,不推崇quick & dirty
- 及时承认错误,不要觉得承认错误会有损你架构师的身份
- 不为了炫技而炫技
- 精益求精
什么样的架构叫好架构
代码整齐,分类明确,没有common,没有core
- 破窗理论提醒我们,如果代码不整齐分类不明确,整个架构会随着一次一次的拓展而越来越混乱。
- 不要让一个类或者一个模块做两种不同的事情。如果有类或某模块做了两种不同的事情,一方面不适合未来拓展,另一方面也会造成分类困难
- 不要搞Common,Core这些东西。每家公司的架构代码库里面,最恶心的一定是这两个名字命名的文件夹,我这么说一定不会错。不要开Common/Core这样的文件夹,后来者一定会把这个地方搞得一团糟,最终变成Common也不Common,Core也不Core.
- 如果真有什么东西特别小,那就索性为了他单独开辟一个模块就好了,小就小点,关键是要有序。
不用文档,或很少文档,就能让业务方上手
要尽可能让你的API名字可读性强,对于iOS来说,objc这门语言的特性把这个做到了极致,函数名长就长一点,不要紧。
1 | 好的函数名: |
思路和方法要统一,尽量不要多元
- 解决一个问题会有很多种方案,但是一旦确定了一种方案,就不要在另一个地方采用别的方案了
- 要是一个框架里面解决同一种类似的问题有各种五花八门的方法或者类,我觉得做这个架构的架构师一定是自己都没想清楚就开始搞了。
没有横向依赖,万不得已不出现跨层访问
- 没有横向依赖是很重要的,这决定了你将来要对这个架构做修补所需要的成本有多大。要做到没有横向依赖,这很考验模块分类能力和是否熟悉业务。
- 跨层访问会增加耦合度,当某一层需要整体替换的时候,牵涉面就会很大。尽量不要出现跨层的情况.
对业务方该限制的地方有限制,该灵活的地方要给业务方创造灵活实现的条件
- 必须要有能力区分哪些情况需要限制灵活性,哪些情况需要创造灵活性。
- 限制灵活性,只对外公开一个修改接口, 避免业务滥用.
- 如果是设计一个ABTest相关的API的时候,我们又希望增加它的灵活性。使得业务方不光可以通过Target-Action的模式实现ABtest,也要可以通过Block的方式实现ABTest,要尽可能满足灵活性,减少业务方的使用成本。
易测试,易拓展
要实现易测试易拓展,那就要提高模块化程度,尽可能减少依赖关系,便于mock。另外,如果是高度模块化的架构,拓展起来将会是一件非常容易的事情。
保持一定量的超前性
- 准确把握技术走向
- 了解产品未来走向,在合理的地方留一条路
- 很多产品需求其实只是为了赶产品进度而产生的妥协方案,最后还是会转到正轨的。这时候业务方可以不实现转到正规的方案,但是架构这边,是一定要为这种可预知的改变做准备的。
接口少,接口参数少
越少的接口越少的参数,就能越降低业务方的使用成本。
高性能
- 做架构时首要考虑因素应当是便于业务方快速满足产品需求,因此需要尽可能提供简单易用效果好的接口给业务方,而不是提供高性能的接口给业务方
- 苹果平台的优化手段相对有限,甚至于有些时候即便动用了无所不用其极的手段乃至不择手段牺牲了稳定性,性能提高很有可能也只不过是100ms到90ms的差距。
- 性能优化的东西, 对应每层架构都有每层架构的不同优化方案.
架构分层
三层架构???
我们常见的分层架构,有三层架构的:展现层、业务层、数据层。也有四层架构的:展现层、业务层、网络层、本地数据层。这里说三层、四层,跟TCP/IP所谓的五层或者七层不是同一种概念。再具体说就是:你这个架构在逻辑上是几层那就几层,具体每一层叫什么,做什么,没有特定的规范。这主要是针对模块分类而言的。
也有说MVC架构,MVVM架构的,这种层次划分,主要是针对数据流动的方向而言的。
在实际情况中,针对数据流动方向做的设计和针对模块分类做的设计是会放在一起的,也就是说,一个MVC架构可以是四层:展现层、业务层、网络层、本地数据层。
大概在五六年前,业界很流行三层架构这个术语。然后各种文档资料漫天的三层架构,并且喜欢把它与MVC放在一起说,MVC三层架构/三层架构MVC,以至于很多人就会认为三层架构就是MVC,MVC就是三层架构。其实不是的。三层架构里面其实没有Controller的概念,而且三层架构描述的侧重点是模块之间的逻辑关系。MVC有Controller的概念,它描述的侧重点在于数据流动方向。
好,为什么流行起来的是三层架构,而不是四层架构或五层架构?
因为所有的模块角色只会有三种:数据管理者、数据加工者、数据展示者,意思也就是,笼统说来,软件只会有三层,每一层扮演一个角色。其他的第四层第五层,一般都是这三层里面的其中之一分出来的,最后都能归纳进这三层的某一层中去,所以用三层架构来描述就比较普遍。
那么我们怎么做分层?
应该如何做分层,不是在做架构的时候一开始就考虑的问题。虽然我们要按照自顶向下的设计方式来设计架构,但是一般情况下不适合直接从三层开始。一般都是先确定所有要解决的问题,先确定都有哪些模块,然后再基于这些模块再往下细化设计。然后再把这些列出来的问题和模块做好分类。分类之后不出意外大多数都是三层。如果发现某一层特别庞大,那就可以再拆开来变成四层,变成五层。
当你把所有模块都找出来之后,就要开始整理你的这些模块,然后这些模块分完之后你看一下图,嗯,1、2、3,一共三层,所以那就是三层架构啦。在这里最消耗脑力最考验架构功力的地方就在于:找到所有需要的模块, 把模块放在该放的地方
对的,答案就是没有分层。所谓的分层都是出架构图之后的事情了。所以你看别的架构师在演讲的时候,上来第一句话差不多都是:”这个架构分为以下几层…”。但考虑分层的问题的时机绝对不是一开始就考虑的。另外,模块一定要把它设计得独立性强,这其实是门艺术活。
Common文件夹?
- 一般情况下,我们都会有一些属于这个项目的公共类,比如取定位坐标,比如图像处理。这些模块可能非常小,单独拎出来成为一个模块感觉不够格,但是又不属于其他任何一个模块。于是就会把它们放入Common里。在当时来看这么做看不出什么问题,但关键在于:软件是有生命,会成长的。当时分出来的小模块,很有可能会随着业务的成长,逐渐发展成大模块,发展成大模块后,可以再把它从Common移出来单独成立一个模块。然而在实际操作过程中,工程师在拓展这个小模块的时候,不太容易会去考虑横向依赖的问题,因为当时这些模块都在Common里面,直接进行互相依赖是非常符合直觉的,而且也不算是不遵守规范。然而要注意的是,这才是Commom代码混乱的罪魁祸首,Common文件夹纵容了不精心管理依赖的做法。
- 在使用Cocoapods来管理项目库的时候,Common往往就是一个 pod。这个 pod 里面会有A/B/C/D/E这些函数集或小模块。如果要新开一个app或者Demo,势必会使用到Common 这个 pod,这么做,往往会把不需要包含的代码也包含进去,我对项目有高度洁癖,这种情况会让我觉得非常不舒服。
- Common本身就是一个粒度非常大的模块, 可能依赖了很多业务, 所有依赖 Common 的业务都要依赖这些没关系的业务.
简而言之,不建议开Common的原因如下:
- 在Common里面很容易形成错综复杂的小模块依赖,在模块成长过程中,会纵容工程师不注意依赖的管理,乃至于将来如果要将模块拆分出去,会非常的困难。
- Common本身与细粒度模块设计的思想背道而驰,属于一种不合适的偷懒手段,在将来业务拓张会成为阻碍。
- 一旦设置了Common,就等于给地狱之门打开了一个小缝,每次业务迭代都会有一些不太好分类的东西放入Common,这就给维护Common的人带来了非常大的工作量,而且这些工作量全都是体力活,非常容易出错。
那么,不设Common会带来哪些好处?
- 强迫工程师在业务拓张的时候将依赖管理的事情考虑进去,让模块在一开始发展的时候就有自己的土壤,成长空间和灵活度非常大。
- 减少各业务模块或者Demo的体积,不需要的模块不会由于Common的存在而包含在内。
- 可维护性大大提高,模块升级之后要做的同步工作非常轻松,解放了那个苦逼的Common维护者,更多的时间可以用在更实质的开发工作上。
- 符合细粒度模块划分的架构思想。
iOS应用架构谈 view层的组织和调用方案
一般来说,一个不够好的View层架构,主要原因有以下五种:
- 代码混乱不规范
- 过多继承导致的复杂依赖关系
- 模块化程度不够高,组件粒度不够细
- 横向依赖
- 架构设计失去传承
View层架构是最贴近业务的底层架构。
View代码结构的规定
制定代码规范严格来讲不属于View层架构的事情,但它对View层架构未来的影响会比较大,也是属于架构师在设计View层架构时需要考虑的事情。制定View层规范的重要性在于:
- 提高业务方View层的可读性可维护性
- 防止业务代码对架构产生腐蚀
- 确保传承
- 保持架构发展的方向不轻易被不合理的意见所左右
VC 一般应该保持如下结构:
1 |
|
关于private methods,正常情况下ViewController里面不应该写
正常情况下ViewController里面一般是不会存在private methods的,这个private methods一般是用于日期换算、图片裁剪啥的这种小功能。这种小功能要么把它写成一个category,要么把他做成一个模块,哪怕这个模块只有一个函数也行。
ViewController基本上是大部分业务的载体,本身代码已经相当复杂,所以跟业务关联不大的东西能不放在ViewController里面就不要放。另外一点,这个private method的功能这时候只是你用得到,但是将来说不定别的地方也会用到,一开始就独立出来,有利于将来的代码复用。
关于View的布局
直接使用 CGRectMake 的话可读性很差,光看那几个数字,也无法知道view和view之间的位置关系。用Autolayout可读性稍微好点儿,但生成Constraint的长度实在太长,代码观感不太好。
Autolayout这边可以考虑使用Masonry,代码的可读性就能好很多。如果还有使用Frame的,可以考虑一下使用HandyAutoLayout。
何时使用storyboard,何时使用nib,何时使用代码写View
实现简单的东西,用Code一样简单,实现复杂的东西,Code比StoryBoard更简单。所以我更加提倡用code去画view而不是storyboard。
是否有必要让业务方统一派生ViewController
在这里我想讨论的是,在设计View架构时,如果为了能够达到统一设置或执行统一逻辑的目的,使用派生的手段是有必要的吗?
- 使用派生比不使用派生更容易增加业务方的使用成本
- 不使用派生手段一样也能达到统一设置的目的
为什么使用了派生,业务方的使用成本会提升?
集成成本
如果业务方自己开了一个独立 demo,现在把这个demo集合进去,需要把所有独立的UIViewController改变成 TMViewController。那为什么demo不是一开始就立刻使用TMViewController呢?因为要想引入TMViewController,就要引入App所有的业务线,所有的基础库,所谓拔出萝卜带出泥,你要是想简单继承一下就能搞定的事情,搭环境就要搞半天,然后这个小Demo才能跑得起来。
对于业务层存在的所有父类来说,它们是很容易跟项目中的其他代码纠缠不清的,这使得业务方开发时遇到一个两难问题:要么把所有依赖全部搞定,然后基于App环境下开发Demo,要么就是自己Demo写好之后,按照环境要求改代码。这里的两难问题都会带来成本,都会影响业务方的迭代进度。
上手接受成本
额外学习成本,比如说:所有的ViewController都必须继承自TMViewController
架构的维护难度
尽可能少地使用继承能提高项目的可维护性,具体内容在跳出面向对象思想(一) 继承.
那么如果不使用派生,我们应该使用什么手段
在具体的方案之前,必须要想清楚几个问题,然后才能决定采用哪种方案。
- 方案的效果,和最终要达到的目的是什么?
- 在自己的知识体系里面,是否具备实现这个方案的能力?
- 在业界已有的开源组件里面,是否有可以直接拿来用的轮子?
这三个问题按照顺序一一解答之后,具体方案就能出来了。
方案的效果,和最终要达到的目的是什么?
方案的效果应该是:
- 业务方可以不用通过继承的方法,然后框架能够做到对ViewController的统一配置。
- 业务方即使脱离框架环境,不需要修改任何代码也能够跑完代码。业务方的ViewController一旦丢入框架环境,不需要修改任何代码,框架就能够起到它应该起的作用。
那么还有两个问题,框架要能够拦截到ViewController的生命周期,以及拦截的定义时机.
关于MVC、MVVM等一大堆思想
在iOS开发领域,我们应当如何进行MVC的划分?
这里面其实有两个问题:
- 为什么我们会纠结于iOS开发领域中MVC的划分问题?
- 在iOS开发领域中,怎样才算是划分的正确姿势?
因为UIViewController中自带了一个View,且控制了View的整个生命周期(viewDidLoad,viewWillAppear…),而在常识中我们都知道Controller不应该和View有如此紧密的联系,所以才导致大家对划分产生困惑?
UIView的另一个身份其实是容器!UIViewController中自带的那个view,它的主要任务就是作为一个容器。如果它所有的相关命名都改成ViewContainer,那么代码就会变成这样:
1 | - (void)viewContainerDidLoad |
在iOS开发领域,虽然也有让View去监听事件的做法,但这种做法非常少,都是把事件回传给Controller,然后Controller再另行调度。所以这时候,View的容器放在Controller就非常合适。Controller可以因为不同事件的产生去很方便地更改容器内容,比如加载失败时,把容器内容换成失败页面的View,无网络时,把容器页面换成无网络的View等等。
在iOS开发领域中,怎样才算是MVC划分的正确姿势?
M应该做的事:
- 给ViewController提供数据
- 给ViewController存储数据提供接口
- 提供经过抽象的业务基本组件,供Controller调度
C应该做的事:
- 管理View Container的生命周期
- 负责生成所有的View实例,并放入View Container
- 监听来自View与业务有关的事件,通过与Model的合作,来完成对应事件的业务。
V应该做的事:
- 响应与业务无关的事件,并因此引发动画效果,点击反馈(如果合适的话,尽量还是放在View去做)等。
- 界面元素表达
MVCS
关于胖Model和瘦Model胖Model包含了部分弱业务逻辑。胖Model要达到的目的是,Controller从胖Model这里拿到数据之后,不用额外做操作或者只要做非常少的操作,就能够将数据直接应用在View上.瘦Model只负责业务数据的表达,所有业务无论强弱一律扔到Controller。瘦Model要达到的目的是,尽一切可能去编写细粒度Model,然后配套各种helper类或方法来对弱业务做抽象,强业务依旧交给Controller。MVCS是基于瘦Model的一种架构思路,把原本Model要做的很多事情中的其中一部分关于数据存储的代码抽象成了Store,在一定程度上降低了Controller的压力。
MVVM
不管MVVM也好,MVCS也好,他们的共识都是Controller会随着软件的成长,变很大很难维护很难测试。只不过两种架构思路的前提不同,MVCS是认为Controller做了一部分Model的事情,要把它拆出来变成Store,MVVM是认为Controller做了太多数据加工的事情,所以MVVM把数据加工的任务从Controller中解放了出来,使得Controller只需要专注于数据调配的工作,ViewModel则去负责数据加工并通过通知机制让View响应ViewModel的改变。
MVVM是基于胖Model的架构思路建立的,然后在胖Model中拆出两部分:Model和ViewModel。关于这个观点我要做一个额外解释:胖Model做的事情是先为Controller减负,然后由于Model变胖,再在此基础上拆出ViewModel,跟业界普遍认知的MVVM本质上是为Controller减负这个说法并不矛盾,因为胖Model做的事情也是为Controller减负。
不用ReactiveCocoa也能MVVM,用ReactiveCocoa能更好地体现MVVM的精髓.
大部分国内外资料阐述MVVM的时候都是这样排布的:View <-> ViewModel <-> Model, 造成了MVVM不需要Controller的错觉,现在似乎发展成业界开始出现MVVM是不需要Controller的。的声音了。其实MVVM是一定需要Controller的参与的,虽然MVVM在一定程度上弱化了Controller的存在感,并且给Controller做了减负瘦身(这也是MVVM的主要目的)。但是,这并不代表MVVM中不需要Controller,MMVC和MVVM他们之间的关系应该是这样: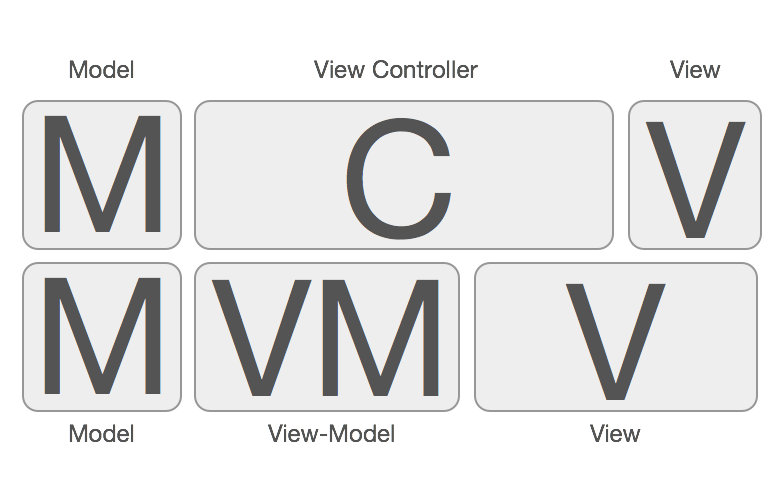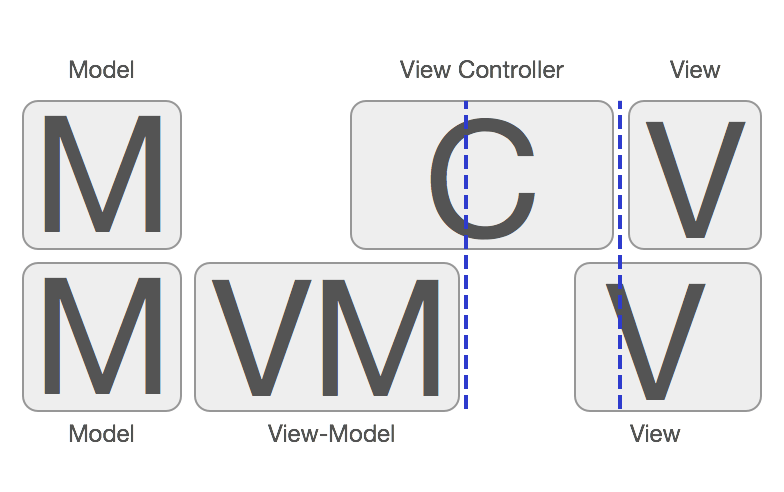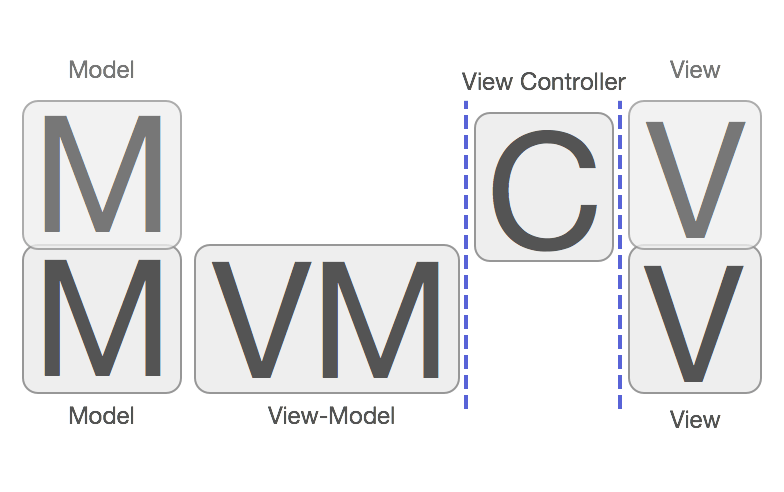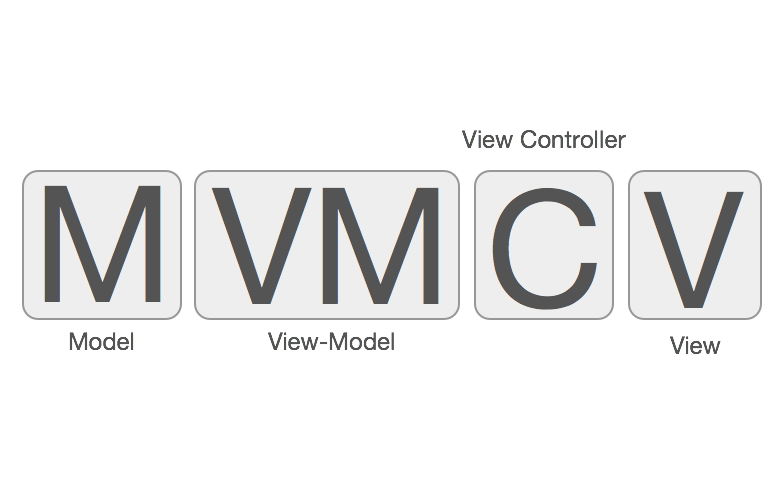
View <-> C <-> ViewModel <-> Model, 所以使用MVVM之后,就不需要Controller的说法是不正确的。严格来说MVVM其实是MVCVM。 Controller夹在View和ViewModel之间做的其中一个主要事情就是将View和ViewModel进行绑定, 在逻辑上,Controller知道应当展示哪个View,Controller也知道应当使用哪个ViewModel,然而View和ViewModel它们之间是互相不知道的,所以Controller就负责控制他们的绑定关系,所以叫Controller/控制器就是这个原因。
前面扯了那么多,其实归根结底就是一句话:在MVC的基础上,把C拆出一个ViewModel专门负责数据处理的事情,就是MVVM。
VIPER
拆分的心法
MVC其实是非常高Level的抽象,意思也就是,在MVC体系下还可以再衍生无数的架构方式,但万变不离其宗的是,它一定符合MVC的规范。
根据前面几节的洗礼,相信各位也明白了这样的道理:拆分方式的不同诞生了各种不同的衍生架构方案(MVCS拆胖Controller,MVVM拆胖Model,VIPER什么都拆),但即便拆分方式再怎么多样,那都只是招式。而拆分的规范,就是心法
第一心法:保留最重要的任务,拆分其它不重要的任务
在iOS开发领域内,UIViewController承载了非常多的事情,比如View的初始化,业务逻辑,事件响应,数据加工等等,当然还有更多我现在也列举不出来,但是我们知道有一件事情Controller肯定逃不掉要做:协调V和M。也就是说,不管怎么拆,协调工作是拆不掉的。
Lighter View Controllers 文章第一节就提倡拆分 DataSource. 任何比较大的,放在ViewController里面比较脏的,只要不是Controller的核心逻辑,都可以考虑拆出去,然后在架构的时候作为一个独立模块去定义,以及设计实现。
第二心法:拆分后的模块要尽可能提高可复用性,尽量做到DRY
根据第一心法拆开来的东西,很有可能还是强业务相关的,这种情况有的时候无法避免。但我们拆也要拆得好看,拆出来的部分最好能够归成某一类对象,然后最好能够抽象出一个通用逻辑出来,使他能够复用。即使不能抽出通用逻辑,那也尽量抽象出一个protocol。参考文章跳出面向对象思想(二) 多态
第三心法:要尽可能提高拆分模块后的抽象度
提高抽象程度的好处在于,对于业务方来说,他只需要收集很少的信息(最小充要条件),做很少的调度(Controller负责大模块调度,大模块里面再去做小模块的调度),就能够完成任务,这才是给Controller减负的正确姿势。
如果拆分出来的模块抽象程度不够,模块对外界要求的参数比较多,那么在Controller里面,关于收集参数的代码就会多了很多。如果一部分参数的收集逻辑能够由模块来完成,那也可以做到帮Controller减轻负担。否则就感觉拆得不太干净,因为Controller里面还是多了一些不必要的参数收集逻辑。
如果拆分出来的粒度太小,Controller在完成任务的时候调度代码要写很多,那也不太好。导致拆分粒度小的首要因素就是业务可能本身就比较复杂,拆分粒度小并不是不好,能大就大一点,如果小了,那也没问题。针对这种情况的处理,就需要采用strategy模式。
设计心法
针对View层的架构不光是看重如何合理地拆分MVC来给UIViewController减负,另外一点也要照顾到业务方的使用成本。最好的情况是业务方什么都不知道,然后他把代码放进去就能跑,同时还能获得框架提供的种种功能。
第一心法:尽可能减少继承层级,涉及苹果原生对象的尽量不要继承
继承是罪恶,尽量不要继承. 不用继承可能在思路上不会那么直观,但是对于不使用继承带来的好处是足够顶得上使用继承的坏处的。顺便在此我要给Category正一下名:业界对于Category的态度比较暧昧,在多种场合(讲座、资料文档)都宣扬过尽可能不要使用Category。它们说的都有一定道理,但我认为Category是苹果提供的最好的使用集合代替继承的方案,但针对Category的设计对架构师的要求也很高,请合理使用。而且苹果也在很多场合使用Category,来把一个原本可能很大的对象,根据不同场景拆分成不同的Category,从而提高可维护性.
不使用继承的好处我在这里已经说了,放到iOS应用架构来看,还能再多额外两个好处:1. 在业务方做业务开发或者做Demo时,可以脱离App环境,或花更少的时间搭建环境。2. 对业务方来说功能更加透明,也符合业务方在开发时的第一直觉。
第二心法:做好代码规范,规定好代码在文件中的布局,尤其是ViewController
life cycle -> Delegate -> Action(event response) -> Getter&Setter
第三心法:能不放在Controller做的事情就尽量不要放在Controller里面去做
Controller会变得庞大的原因,一方面是因为Controller承载了业务逻辑。另一方面是因为在MVC中,关于Model和View的定义都非常明确,很少有人会把一个属于M或V的东西放到其他地方。然后除了Model和View以外,还会剩下很多模棱两可的东西,这些东西放在M或V是不合适的,于是就往Controller里面塞。
正是由于上述两方面原因导致了Controller的膨胀。我们再细细思考一下,Model膨胀和View膨胀,要针对它们来做拆分其实都是相对容易的,Controller膨胀之后,拆分就显得艰难无比。所以如果能够在一开始就尽量把能不放在Controller做的事情放到别的地方去做,这样在第一时间就可以让你的那部分将来可能会被拆分的代码远离业务逻辑。所以我们要稍微转变一下思路:模棱两可的模块,就不要塞到Controller去了,塞到V或者塞到M或者其他什么地方都比塞进Controller好,便于将来拆分。
第四心法:架构师是为业务工程师服务的,而不是去使唤业务工程师的
跨业务页面调用方案的设计
跨业务页面调用是指,当一个App中存在A业务,B业务等多个业务时,B业务有可能会需要展示A业务的某个页面,A业务也有可能会调用其他业务的某个页面。在小规模的App中,我们直接import其他业务的某个ViewController然后或者push或者present,是不会产生特别大的问题的。但是如果App的规模非常大,涉及业务数量非常多,再这么直接import就会出现问题。
1 | -------------- -------------- -------------- |
可以看出,跨业务的页面调用在多业务组成的App中会导致横向依赖。那么像这样的横向依赖,如果不去设法解决,会导致什么样的结果?
- 当一个需求需要多业务合作开发时,如果直接依赖,会导致某些依赖层上端的业务工程师在前期空转,依赖层下端的工程师任务繁重,而整个需求完成的速度会变慢,影响的是团队开发迭代速度。
- 当要开辟一个新业务时,如果已有各业务间直接依赖,新业务又依赖某个旧业务,就导致新业务的开发环境搭建困难,因为必须要把所有相关业务都塞入开发环境,新业务才能进行开发。影响的是新业务的响应速度。
- 当某一个被其他业务依赖的页面有所修改时,比如改名,涉及到的修改面就会特别大。影响的是造成任务量和维护成本都上升的结果。
那么应该怎样处理这个问题?
让依赖关系下沉。
怎么让依赖关系下沉?引入Mediator模式。
所谓引入Mediator模式来让依赖关系下沉,实质上就是每次呼唤页面的时候,通过一个中间人来召唤另外一个页面,这样只要每个业务依赖这个中间人就可以了,中间人的角色就可以放在业务层的下面一层,这就是依赖关系下沉。
1 | -------------- -------------- -------------- |
当A业务需要调用B业务的某个页面的时候,将请求交给Mediater,然后由Mediater通过某种手段获取到B业务页面的实例,交还给A就行了。在具体实现这个机制的过程中,有以下几个问题需要解决:
- 设计一套通用的请求机制,请求机制需要跟业务剥离,使得不同业务的页面请求都能够被Mediater处理
- 设计Mediater根据请求如何获取其他业务的机制,Mediater需要知道如何处理请求,上哪儿去找到需要的页面
后续 演化成为了组件化方案iOS应用架构谈 组件化方案
小总结
其实针对View层的架构设计,还是要做好三点:代码规范,架构模式,工具集。
View层的工具集主要还是集中在如何对View进行布局,以及一些特定的View,比如带搜索提示的搜索框这种。这篇文章只提到了View布局的工具集,其它的工具集相对而言是更加取决于各自公司的业务的,各自实现或者使用CocoaPods里现成的都不是很难。
iOS应用架构谈 网络层设计方案
网络层跟业务对接部分的设计
使用哪种交互模式来跟业务层做对接?
以Delegate为主,Notification为辅。原因如下:
- 尽可能减少跨层数据交流的可能,限制耦合, 使用 Delegate 只会严格地将信息传给对应的对象, 而在一定需要跨层访问的时候(网络变更)才使用 Notification. 之所以不用 Block 是因为
- block很难追踪,难以维护
- block会延长相关对象的生命周期
- block在离散型场景下不符合使用的规范, 集约型API调用方式和离散型API调用方式的选择??
- 统一回调方法,便于调试和维护. 使用 Block 的话 调用以及回调会在一个地方, 相当一个方法做了两件事情, 违背了 single function,single task 原则, 虽然也可以吧回调封装成一个独立的方法, 但是这样就跟 Delegate 一样了. 其次 Block 相对来说不好调试, 堆栈信息较少, 代码不直观.
- 在跟业务层对接的部分只采用一种对接手段(在我这儿就是只采用delegate这一个手段)限制灵活性,以此来交换应用的可维护性
集约型API调用方式和离散型API调用方式的选择?
1 | // 集约型API调用方式: |
集约型API调用就是网络框架实现细节, 部分参数由外部指定,离散型API调用 就是参数全部由网络框架指定, 只暴露具体业务接口即可.
其实离散型API底层也是集约型
采用离散型而不是集约型的原因
- 集约型如果退出页面, 还要主动取消, 刷新也要考虑是优先采用正在请求的还是生成新的请求, 而离散型. 而离散型可以针对不用的 API 灵活设置逻辑, 在 APIManager 实现, 无需业务自己考虑这些问题
- 便于针对某个API请求来进行离散型AOP, 而集约型需要大量判断
- 当页面退出时, 离散型可以更透明的处理这类问题, 集约型需要调用者自己去管理, 在 每个 VC 释放时主动取消. 而离散型的 VC 释放会触发 APIMananger 释放, APIMananger 释放时再释放这些请求.
- 离散型对于翻页可以提供 loadNext 之类的接口, 但是集约型就要业务自己管理分页. 离散型可以针对特定接口的特定参数做自定义的校验, 而集约型也需要业务去完成这些.
如果你的App只提供了集约化的方式,而没有离散方式的通道,那么我建议你再封装一层,便于业务方使用离散的API调用方式。
怎么做APIManager的继承?
BaseAPIManager里面负责集约化的部分,外部派生的XXXAPIManager负责离散的部分,对于BaseAPIManager来说,离散的部分有一些是必要的,比如API名字等,而我们派生的目的,也是为了提供这些数据。
网络层的安全机制
判断API的调用请求是来自于经过授权的APP
使用这个机制的目的主要有两点:
- 确保API的调用者是来自你自己的APP,防止竞争对手爬你的API
- 如果你对外提供了需要注册才能使用的API平台,那么你需要有这个机制来识别是否是注册用户调用了你的API
- 解决方案:设计签名
保证传输数据的安全
使用这个机制的主要目的有两点:
- 防止中间人攻击,比如说运营商很喜欢往用户的Http请求里面塞广告…
- SPDY依赖于HTTPS,而且是未来HTTP/2的基础,他们能够提高你APP在网络层整体的性能。
- 解决方案:HTTPS
关于速度,HTTPS肯定是比HTTP慢的,毕竟多了一次握手,但挂上SPDY之后,有了链接复用,这方面的性能就有了较大提升。这里的性能提升并不是说一个请求原来要500ms能完成,然后现在只要300ms,这是不对的。所谓整体性能是基于大量请求去讨论的:同样的请求量(假设100个)在短期发生时,挂上SPDY之后完成这些任务所要花的时间比不用SPDY要少。SPDY还有Header压缩的功能,不过因为一个API请求本身已经比较小了,压缩数据量所带来的性能提升不会特别明显,所以就单个请求来看,性能的提升是比较小的。不过这是下一节要讨论的事儿了,这儿只是顺带说一下。
网络层的优化方案
针对链接建立环节的优化
在API发起请求建立链接的环节,大致会分这些步骤:
- 发起请求,
- 要解决的问题就是网络层该不该为此API调用发起请求, 有缓存就不请求。什么时候清理缓存?
- 使用策略来减少请求的发起次数, 针对重复请求的发起和取消, 重复请求可以复用结果, 取消的请求如果还在队列中可以先释放
- DNS域名解析得到IP
- 针对DNS域名解析做的优化, 移动端 DNS 缓存很容易随链路变换或者切换 App被清掉, 不如直接 IP 请求.
- 本地有一份IP列表,这些IP是所有提供API的服务器的IP,每次应用启动的时候,针对这个列表里的所有IP取ping延时时间,然后取延时时间最小的那个IP作为今后发起请求的IP地址。
- 根据IP进行三次握手(HTTPS四次握手),链接建立成功
- 这个本地IP列表也会需要通过一个API来维护,一般是每天第一次启动的时候读一次API,然后更新到本地。
- 在应用启动的时候获得本地列表中所有IP的ping值,然后通过NSURLProtocol的手段将URL中的HOST修改为我们找到的最快的IP
针对链接传输数据量的优化
这个很好理解,传输的数据少了,那么自然速度就上去了。这里没什么花样可以讲的,就是各种压缩。
针对链接复用的优化
建立链接本身是属于比较消耗资源的操作,耗电耗时。SPDY自带链接复用以及数据压缩的功能,所以服务端支持SPDY的时候,App直接挂SPDY就可以了。如果服务端不支持SPDY,也可以使用PipeLine,苹果原生自带这个功能。
一般来说业界内普遍的认识是SPDY优于PipeLine, 然后即便如此,SPDY能够带来的网络层效率提升其实也没有文献上的图表那么明显,但还是有性能提升的
还有另外一种比较笨的链接复用的方法,就是维护一个队列,然后将队列里的请求压缩成一个请求发出去,之所以会存在滞留在队列中的请求,是因为在上一个请求还在外面飘的时候。这种做法最终的效果表面上看跟链接复用差别不大,但并不是真正的链接复用,只能说是请求合并。不过目前业界趋势是倾向于使用HTTP/2.0来代替SPDY.
iOS应用架构谈 本地持久化方案及动态部署
根据需求决定持久化方案
NSUserDefault
小规模数据,弱业务相关数据,都可以放到NSUserDefault里面,内容比较多的数据,强业务相关的数据就不太适合NSUserDefault了。
keychain
由于App卸载只要系统不重装,Keychain中的数据依旧能够得到保留,以及可被iCloud同步的特性,大家都会在这里存储用户唯一标识串。所以有需要加密、需要存iCloud的敏感小数据,一般都会放在Keychain。
文件存储
文件存储包括了Plist、archive、Stream等方式,一般结构化的数据或者需要方便查询的数据,都会以Plist的方式去持久化。Archive方式适合存储平时不太经常使用但很大量的数据,或者读取之后希望直接对象化的数据,因为Archive会将对象及其对象关系序列化,以至于读取数据的时候需要Decode很花时间,Decode的过程可以是解压,也可以是对象化,这个可以根据具体
数据库存储
数据库存储的话,花样就比较多了。苹果自带了一个Core Data,当然业界也有无数替代方案可选,不过真正用在iOS领域的除了Core Data外,就是FMDB比较多了。数据库方案主要是为了便于增删改查,当数据有状态和类别的时候最好还是采用数据库方案比较好,而且尤其是当这些状态和类别都是强业务相关的时候,就更加要采用数据库方案了。因为你不可能通过文件系统遍历文件去甄别你需要获取的属于某个状态或类别的数据,这么做成本就太大了。当然,特别大量的数据也不适合直接存储数据库,比如图片或者文章这样的数据,一般来说,都是数据库存一个文件名,然后这个文件名指向的是某个图片或者文章的文件。如果真的要做全文索引这种需求,建议最好还是挂个API丢到服务端去做。
持久层实现时要注意的隔离
在设计持久层架构的时候,我们要关注以下几个方面的隔离:
持久层与业务层的隔离
Data Model
Data Model这个术语针对的问题领域是业务数据的建模,以及代码中这一数据模型的表征方式。两者相辅相承:因为业务数据的建模方案以及业务本身特点,而最终决定了数据的表征方式。同样操作一批数据,你的数据建模方案基本都是细化业务问题之后,抽象得出一个逻辑上的实体。在实现这个业务时,你可以选择不同的表征方式来表征这个逻辑上的实体,比如字节流(TCP包等),字符串流(JSON、XML等),对象流。对象流又分通用数据对象(NSDictionary等),业务数据对象(HomeCellModel等)。
前面已经遍历了所有的Data Model的形式。在习惯上,当我们讨论Model化时,都是单指对象流中的业务数据对象这一种。然而去Model化就是指:更多地使用通用数据对象去表征数据,业务数据对象不会在设计时被优先考虑的一种设计倾向。这里的通用数据对象可以在某种程度上理解为范型。
Model Layer
Model Layer描述的问题领域是如何对数据进行增删改查(CURD, Create Update Read Delete),和相关业务处理。一般来说如果在Model Layer中采用瘦Model的设计思路的话,就差不多到CURD为止了。胖Model还会关心如何为需要数据的上层提供除了增删改查以外的服务,并为他们提供相应的解决方案。例如缓存、数据同步、弱业务处理等。
去Model化
Model 是一种很容易引入耦合的做法,在尽可能弱化Model概念的同时,就能够为引入业务和对接业务提供充分的空间。同时,也能通过去Model的设计达到区分强弱业务的目的,这在将来的代码迁移和维护中,是至关重要的。很多设计不好的架构,就在于架构师并没有认识到区分强弱业务的重要性,所以就导致架构腐化的速度很快,越来越难维护。
数据库读写隔离
在网站的架构中,对数据库进行读写分离主要是为了提高响应速度。在iOS应用架构中,对持久层进行读写隔离的设计主要是为了提高代码的可维护性。这也是两个领域要求架构师在设计架构时要求侧重点不同的一个方面。
在这里我们所谓的读写隔离并不是指将数据的读操作和写操作做隔离。而是以某一条界限为准,在这个界限以外的所有数据模型,都是不可写不可修改,或者修改属性的行为不影响数据库中的数据。在这个界限以内的数据是可写可修改的。一般来说我们在设计时划分的这个界限会和持久层与业务层之间的界限保持一致,也就是业务层从持久层拿到数据之后,都不可写不可修改,或业务层针对这一数据模型的写操作、修改操作都对数据库文件中的内容不产生作用。只有持久层中的操作才能够对数据库文件中的内容产生作用。
在苹果官方提供的持久层方案Core Data的架构设计中,并没有针对读写作出隔离,数据的结果都是以NSManagedObject扔出。所以只要业务工程师稍微一不小心动一下某个属性,NSManagedObjectContext在save的时候就会把这个修改给存进去了。另外,当我们需要对所有的增删改查操作做AOP的切片时,Core Data技术栈的实现就会非常复杂。
读写隔离还能够便于加入AOP切点,因为针对数据库的写操作被隔离到一个固定的地方,加AOP时就很容易在正确的地方放入切片。
多线程控制导致的隔离
SQLite库提供了三种方式:Single Thread,Multi Thread,Serialized。
Single Thread模式不是线程安全的,不提供任何同步机制。Multi Thread模式要求database connection不能在多线程中共享,其他的在使用上就没什么特殊限制了。Serialized模式顾名思义就是由一个串行队列来执行所有的操作,对于使用者来说除了响应速度会慢一些,基本上就没什么限制了。大多数情况下SQLite的默认模式是Serialized。
如果对响应速度要求很高的话,建议开一个辅助数据库,把一个大的写入任务先写入辅助数据库,然后拆成几个小的写入任务见缝插针地隔一段时间往主数据库中写入一次,写完之后再把辅助数据库删掉。
不过从实际经验上看,本地App的持久化需求的读写操作一般都不会大, Serialized模式我认为是性价比比较高的一种选择,代码容易写容易维护,性能损失不大。为了提高几十毫秒的性能而牺牲代码的维护性,我是觉得划不来的。
数据表达和数据操作的隔离
1 | Record *record = [[Record alloc] init]; |
一个对象映射了一个数据库里的表,然后针对这个对象做操作就等同于针对这个表以及这个对象所表达的数据做操作。这个Record既是数据库中数据表的映射,又是这个表中某一条数据的映射。
数据表为单位去针对操作进行对象封装,然后再针对数据记录进行对象封装。数据表中的操作都是针对记录的普通增删改查操作,都是弱业务逻辑。数据记录仅仅是数据的表达方式,这些操作最好交付给数据层分管强业务的对象去执行。
持久层与业务层的交互方式
在交互方案的设计中,架构师应当区分好强弱业务,把传统的Data Model区分成Table和Record,并由DataCenter去实现强业务,Table去实现弱业务。在这里由于DataCenter是强业务相关,所以在实际编码中,业务工程师负责创建DataCenter,并向业务层提供业务友好的方法,然后再在DataCenter中操作Table来完成业务层交付的需求。区分强弱业务,将Table和Record拆分开的好处在于:
- 通过业务细分降低耦合度,使得代码迁移和维护非常方便
- 通过拆解数据处理逻辑和数据表达形态,使得代码具有非常良好的可拓展性
- 做到读写隔离,避免业务层的误操作引入Bug
- 为Virtual Record这一设计思路的实践提供基础,进而实现更灵活,对业务更加友好的架构
数据库性能调优
移动App场景下数据库的性能优化手段不像服务端那样丰富多彩,很多牛逼技术和参数调优手段想用也用不了。差不多就只剩下数据切片的手段比较有效了
纵切在实际操作时,大多都是根据业务场景去切分成多个不同的表,分别来表达用户各业务相关的部分数据,所以纵切的结果就是把Column特别多的一张表拆成Column不那么多的好几个表。
横切也是一种数据库的优化手段,横切与纵切不同的地方在于,横切是在保留了这套数据的完整性的前提下进行的切分,横切的结果就是把一个原本数据量很大的表,分成了好几个数据量不那么大的表。
数据库版本迁移方案
数据迁移事实上实现起来还是比较简单的,做好以下几点问题就不大了:
- 根据应用的版本记录每一版数据库的改变,并将这些改变封装成对象
- 记录好当前数据库的版本,便于跟迁移记录做比对
- 在启动数据库时执行迁移操作,如果迁移失败,提供一些降级方案
在版本迁移时要注意的一点是性能问题。我们一般都不会在主线程做版本迁移的事情,这自然不必说。需要强调的是,SQLite本身是一个容错性非常强的数据库引擎,因此差不多在执行每一个SQL的时候,内部都是走的一个Transaction。当某一版的SQL数量特别多的时候,建议在版本迁移的方法里面自己建立一个Transaction,然后把相关的SQL都包起来,这样SQLite执行这些SQL的时候速度就会快一点。
数据同步方案
单向数据同步
如何完成单向数据同步的需求
- 添加identifier。当设备发起同步请求的时候,把identifier带上,当服务器完成任务返回数据时,也把这些identifier带上。然后客户端再根据服务端给到的identifier再更新本地数据的状态。identifier一般都会采用UUID字符串。
- 添加isDirty. 当本地新生成数据或者更新数据之后,收到服务器的确认返回之前,isDirty置为YES。当服务器的确认包返回之后,再根据包里提供的identifier找到这条数据,然后置为NO。这样就完成了数据的同步。如果希望做得比较细致,在发送同步请求期间依旧允许用户修改的话,就需要在数据库额外增加一张
DirtyList来记录这些操作,这个表里至少要有两个字段:identifier,primaryKey。然后每一次操作都分配一次identifier,那么新的修改操作就有了新的identifier。在进行同步时,根据primaryKey找到原数据表里的那条记录,然后把数据连同identifier交给服务器。然后在服务器的确认包回来之后,就只要拿出identifier再把这条操作记录删掉即可。这个表也可以直接服务于多个表,只是还需要额外添加一个tablename字段,方便发起同步请求的时候能够找得到数据。 - 添加isDeleted. 当有数据同步的需求的时候,删除操作就不能是简单的物理删除了,而只是逻辑删除,所谓逻辑删除就是在数据库里把这条记录的
isDeleted记为YES,只有当服务器的确认包返回之后,才会真正把这条记录删除。isDeleted和isDirty的区别在于:收到确认包后,返回的identifier指向的数据如果是isDeleted,那么就要删除这条数据,如果指向的数据只是新插入的数据和更新的数据,那么就只要修改状态就行。 - 在请求的数据包中,添加dependencyIdentifier.在我看到的很多其它数据同步方案中,并没有提供dependencyIdentifier,这会导致一个这样的问题:假设有两次数据同步请求一起发出,A先发,B后发。结果反而是B请求先到,A请求后到。如果A请求的一系列同步操作里面包含了插入某个对象的操作,B请求的一系列同步操作里面正好又删除了这个对象,那么由于到达次序的先后问题错乱,就导致这个数据没办法删除。所以在请求的数据包中,我们要带上上一次请求时一系列identifier的其中一个, 一般都是选择上次请求里面最后的那一个操作的identifier,这样就能表征上一次请求的操作了。服务端这边也要记录最近的100个请求包里面的最后一个identifier(100 是拍脑袋定的). 服务端在收到同步请求包的时候,先看denpendencyIdentifier是否已被记录,如果已经被记录了,那么就执行这个包里面的操作。如果没有被记录,那就先放着再等等,等到条件满足了再执行,这样就能解决这样的问题。之所以不用更新时间而是identifier来做标识,是因为如果要用时间做标识的话,就是只能以客户端发出数据包时候的时间为准, 多设备就会有问题. 当然用时间的话服务器就不用记录那么多的数据.
双向数据同步
- 封装操作对象, 这个协议应当包括:
- 操作的唯一标识
- 数据的唯一标识, 在找到具体操作的时候执行确认逻辑的处理时,都会涉及到对象本身的处理,更新也好删除也好,都要在本地数据库有所体现。所以这个标识就是用于找到对应数据的。
- 操作的类型 Delete,Update,Insert
- 具体的数据,主要是在Insert和Update的时候会用到
- 操作的依赖标识 为了防止先发的包后到后发的包先到这种极端情况
- 用户执行这项操作时的时间戳, 操作数据在从服务器同步下来之后,会存放在一个新的表中,这个表就是待操作数据表,在具体执行这些操作的同时会跟待同步的数据表中的操作数据做比对。如果是针对同一条数据的操作,且这两个操作存在冲突,那么就以时间戳来决定如何执行
- 新增待操作数据表和待同步数据表. 从服务器拉下来的同步操作列表,我们存在待执行数据表中, 在执行过程中,这些操作也要跟待同步数据表进行匹配,看有没有冲突,没有冲突就继续执行,有冲突的话要么按照时间戳执行,要么就告知用户让用户做决定。待同步数据表的作用其实也跟单向同步方案时候的作用类似, 就是防止在发送请求的时候用户有操作, 发起同步请求之前,我们都应该先去查询有没有待执行的列表,当待执行的操作列表同步完成之后,就可以删除里面的记录了,然后再把本地待同步的数据交给服务器。
- 何时从服务器拉取待执行列表
- 每次要把本地数据丢到服务器去同步之前,都要拉取一次待执行列表,执行完毕之后再上传本地同步数据
- 每次进入相关页面的时候都更新一次,看有没有新的操作
- 对实时性要求比较高的,要么客户端本地起一个线程做轮询,要么服务器通过长链接将待执行操作推送过来
- 其它我暂时也想不到了,具体还是看需求吧
iOS应用架构谈 组件化方案
先说说最早的组件化思路蘑菇街 App 的组件化之路
- App启动时实例化各组件模块,然后这些组件向ModuleManager注册Url,有些时候不需要实例化,使用class注册。
- 当组件A需要调用组件B时,向ModuleManager传递URL,参数跟随URL以GET方式传递,类似openURL。然后由ModuleManager负责调度组件B,最后完成任务。
第一步的问题在于,在组件化的过程中,注册URL并不是充分必要条件,组件是不需要向组件管理器注册Url的。而且注册了Url之后,会造成不必要的内存常驻,如果只是注册Class,内存常驻量就小一点,如果是注册实例,内存常驻量就大了。
第二步的问题, 一定是组件化的中间件为openUrl提供服务,而不是openUrl方式为组件化提供服务。
App的组件化方案一定不是建立在URL上的,openURL的跨App调用是可以建立在组件化方案上的。当然,如果App还没有组件化,openURL方式也是可以建立的,就是丑陋一点而已。
正确的组件化方案
1 | -------------------------------------- |
这幅图是组件化方案的一个简化版架构描述,主要是基于Mediator模式和 Target-Action模式,中间采用了runtime来完成调用。这套组件化方案将远程应用调用和本地应用调用做了拆分,而且是由本地应用调用为远程应用调用提供服务,与蘑菇街方案正好相反。
调用方式
先说本地应用调用,本地组件A在某处调用[[CTMediator sharedInstance] performTarget:targetName action:actionName params:@{…}]向CTMediator发起跨组件调用,CTMediator根据获得的target和action信息,通过objective-C的runtime转化生成target实例以及对应的action选择,然后最终调用到目标业务提供的逻辑,完成需求。
App中做路由解析可以做得简单点,制定URL规范就也能完成,最简单的方式就是scheme://target/action这种,简单做个字符串处理就能把target和action信息从URL中提取出来了。
组件仅通过Action暴露可调用接口
所有组件都通过组件自带的Target-Action来响应,也就是说,模块与模块之间的接口被固化在了Target-Action这一层,避免了实施组件化的改造过程中,对Business的侵入,同时也提高了组件化接口的可维护性。
1 | -------------------------------- |
大家可以看到,虚线圈起来的地方就是用于跨组件调用的target和action,这种方式避免了由BusinessA直接提供组件间调用会增加的复杂度,而且任何组件如果想要对外提供调用服务,直接挂上target和action就可以了,业务本身在大多数场景下去进行组件化改造时,是基本不用动的。
复杂参数和非常规参数,以及组件化相关设计思路
这里我们需要针对术语做一个理解上的统一:
复杂参数是指由普通类型的数据组成的多层级参数。在本文中,我们定义只要是能够被json解析的类型就都是普通类型,包括NSNumber, NSString, NSArray, NSDictionary,以及相关衍生类型,比如来自系统的NSMutableArray或者你自己定义的都算。
杂参数的定义是由普通类型组成的具有复杂结构的参数。普通类型的定义就是指能够被json解析的类型。
非常规参数是指由普通类型以外的类型组成的参数,例如UIImage等这些不能够被json解析的类型。然后这些类型组成的参数在文中就被定义为非常规参数。
非常规参数是包含非常规类型的参数。非常规类型的定义就是不能被json解析的类型都叫非常规类型。
边界情况:
- 假设多层级参数中有存在任何一个内容是非常规参数,本文中这种参数就也被认为是非常规参数。
- 如果某个类型当前不能够被json解析,但通过某种转化方式能够转化成json,那么这种类型在场景上下文中,我们也称为普通类型。
举个例子就是通过json描述的自定义view。如果这个view能够通过某个组件被转化成json,那么即使这个view本身并不是普通类型,在具有转化器的上下文场景中,我们依旧认为它是普通类型。
- 如果上下文场景中没有转化器,这个view就是非常规类型了。
- 假设转化出的json不能够被还原成view,比如组件A有转化器,组件B中没有转化器,因此在组件间调用过程中json在B组件里不能被还原成view。在这种调用方向中,只要调用者能将非常规类型转化成json的,我们就依然认为这个view是普通类型。如果调用者是组件A,转化器在组件B中,A传递view参数时是没办法转化成json的,那么这个view就被认为是非常规类型,哪怕它在组件B中能够被转化成json。
然后我来解释一下为什么应该由本地组件间调用来支持远程应用调用:
在远程App调用时,远程App是不可能通过URL来提供非常规参数的,最多只能以json string的方式经过URLEncode之后再通过GET来提供复杂参数,然后再在本地组件中解析json,最终完成调用。
最终完成调用。在组件间调用时,通过performTarget:action:params:是能够提供非常规参数的,
于是我们可以知道,远程App调用时的上下文环境以及功能是本地组件间调用时上下文环境以及功能的子集。
因此这个逻辑注定了必须由本地组件间调用来为远程App调用来提供服务.
另外,远程App调用和本地组件间调用必须要拆分开,远程App调用只能走CTMediator提供的专用远程的方法,本地组件间调用只能走CTMediator提供的专用本地的方法,两者不能通过同一个接口来调用。原因:
- 远程App调用处理入参的过程比本地多了一个URL解析的过程,这是远程App调用特有的过程。这一点我前面说过,这里我就不细说了。
- 架构师没有充要条件条件可以认为远程App调用对于无响应请求的处理方式和本地组件间调用无响应请求的处理方式在未来产品的演进过程中是一致的
组件化方案中的去model设计
组件间调用时,是需要针对参数做去model化的。如果组件间调用不对参数做去model化的设计,就会导致业务形式上被组件化了,实质上依然没有被独立。
在这种跨模块场景中,参数最好还是以去model化的方式去传递,在iOS的开发中,就是以字典的方式去传递。这样就能够做到只有调用方依赖mediator,而响应方不需要依赖mediator。
去model的组件化方案中,影响效率的点有两个:调用方如何知道接收方需要哪些key的参数? 调用方如何知道有哪些target可以被调用?其实后面的那个问题不管是不是去model的方案,都会遇到。为什么放在一起说,因为我接下来要说的解决方案可以把这两个问题一起解决。
解决方案就是使用category
mediator这个repo维护了若干个针对mediator的category,每一个对应一个target,每个category里的方法对应了这个target下所有可能的调用场景,这样调用者在包含mediator的时候,自动获得了所有可用的target-action,无论是调用还是参数传递,都非常方便。接下来我要解释一下为什么是category而不是其他:
- category本身就是一种组合模式,根据不同的分类提供不同的方法,此时每一个组件就是一个分类,因此把每个组件可以支持的调用用category封装是很合理的。
- 在category的方法中可以做到参数的验证,在架构中对于保证参数安全是很有必要的。当参数不对时,category就提供了补救的入口。
- category可以很轻松地做请求转发,如果不采用category,请求转发逻辑就非常难做了。
- category统一了所有的组件间调用入口,因此无论是在调试还是源码阅读上,都为工程师提供了极大的方便。
- 由于category统一了所有的调用入口,使得在跨模块调用时,对于param的hardcode在整个App中的作用域仅存在于category中,在这种场景下的hardcode就已经变成和调用宏或者调用声明没有任何区别了,因此是可以接受的。
基于其他考虑还要再做的一些额外措施
基于安全考虑
将远程app调用入口和本地组件调用入口区分开, 只要拆出远程调用和本地调用,各种做法就都有施展的空间了。
基于动态调度考虑
做这个事情的切点在本文架构中,有很多个:
- 以url parse为切点
- 以实例化target时为切点
- 以category调度方法为切点
- 以target下的action为切点
完整的审查流程:
- App启动时下载调度列表,或者定期下载调度列表。然后审查时检查当前action是否存在要被动态调度跳转的action,如果存在,则跳转到另一个action
- 每一次到达新的action时,以action为参数调用API获知是否需要被跳转,如果需要被跳转,则API告知要跳转的action,然后再跳转到API指定的action
- 如果产品对即时性的要求比较高,那么采用第二种方案,如果产品对即时性要求不那么高,第一种方案就可以了
相比之下,蘑菇街的组件化方案有以下缺陷
- 蘑菇街没有拆分远程调用和本地间调用
- 蘑菇街以远程调用的方式为本地间调用提供服务
- 蘑菇街的本地间调用无法传递非常规参数,复杂参数的传递方式非常丑陋
- 蘑菇街必须要在app启动时注册URL响应者, 这个条件在组件化方案中是不必要条件
- 新增组件化的调用路径时,蘑菇街的操作相对复杂. 在本文给出的组件化方案中,响应者唯一要做的事情就是提供Target和Action,并不需要再做其它的事情。
- 蘑菇街没有针对target层做封装, 这种做法使得所有的跨组件调用请求直接hit到业务模块,业务模块必然因此变得臃肿难以维护,属于侵入式架构。应该将原本属于调用相应的部分拿出来放在target-action中,才能尽可能保证不将无关代码侵入到原有业务组件中,才能保证业务组件未来的迁移和修改不受组件调用的影响,以及降低为项目的组件化实施而带来的时间成本。